织梦装修公司网站模板免费服务器使用推荐
部署其实是不太复杂的,但实际上也耗费了接近2-3天的时间去不断的设置
1 硬件配置信息 采用esxi 虚拟化的方式将T4 卡穿透给esxi 种的ubuntu20.4虚拟机
CPU给到8 core 内存至少32GB以上 T4卡是16GB
2 预先准备OS环境 这里使用的是ubuntu20.4版本,esxi中需要设置uefI启动方式,否则会不识别到T4卡或者T4卡的驱动无法安装正确
3 下载最新的驱动和cuda版本以及cudnn的版本 及Anaconda信息如下
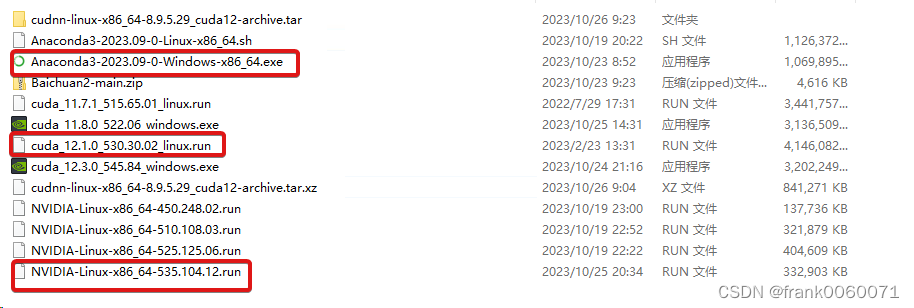
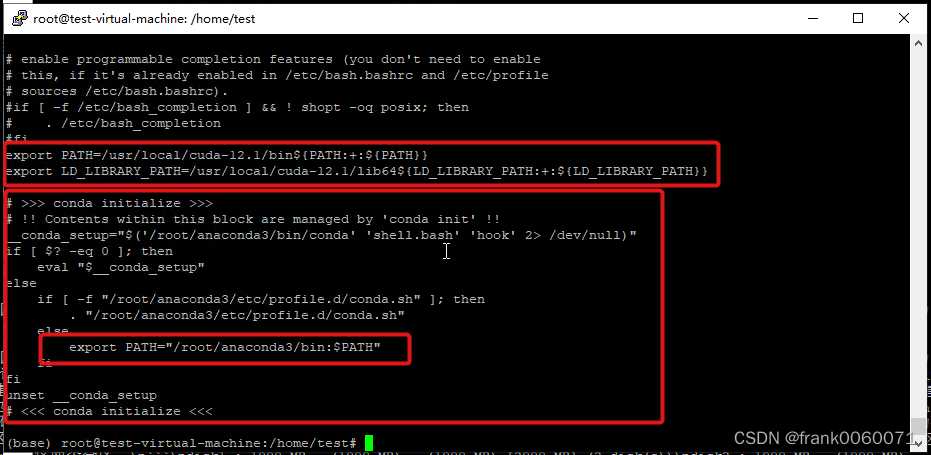
可以通过命令进行确认,这里需要注意的是环境变量需要设置好,主要是cuda和conda
~/.bashrc
确认T4卡是否正常 可以看到已经在使用中

4 安装anaconda 后需要激活相应的环境
conda create -n baichuan2 python=3.10
创建后会有提示进行相应的组件下载,这里建议能有科学上网或者代理类似的
ubuntu下面直接使用临时会话的代理的命令是:
export http_proxy=htt