ps如何做音乐网站会宁网站建设
ubuntu20.04设置共享文件夹
- 一,简介
- 二,操作步骤
- 1,设置Windows下的共享目录
- 2,挂载共享文件夹
- 3,测试是否挂载成功
一,简介
在公司电脑上,使用samba设置共享文件夹,IT安全部门权限不通过,故使用另外一种方法设置共享文件夹。供参考。
二,操作步骤
1,设置Windows下的共享目录
首先关闭Ubuntu虚拟机:
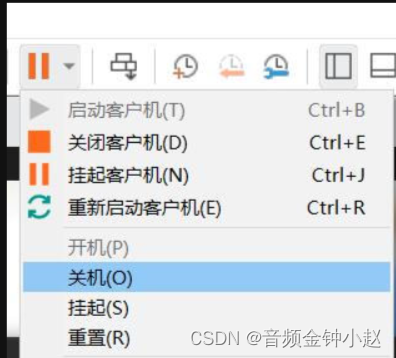
VMware菜单栏:虚拟机->设置->选项:

选择Windows自己的目录:

点击:下一步->完成
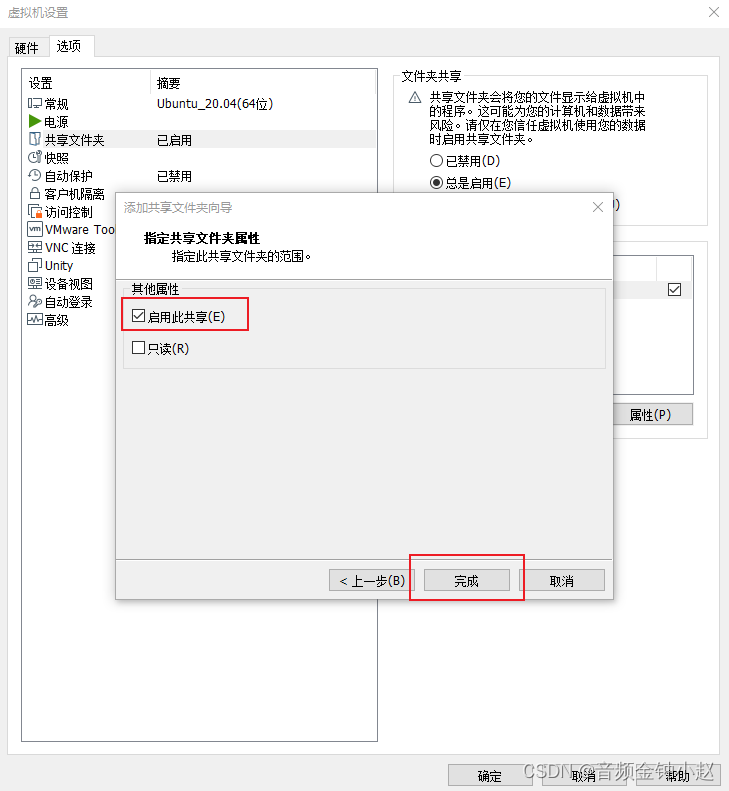
如下图所示,代表共享文件夹添加成功,点击确定,关闭界面。

2,挂载共享文件夹
打开虚拟机,Ctrl+Alt+T打开命令行,并确认/mnt目录下是否存在hgfs文件夹,如果没有该目录则进行如下操作。若存在则进行下一步:
输入此命令(用于查看物理共享目录) vmware-hgfsclient
输入以下命令(创建虚拟机中的共享文件夹) sudo mkdir /mnt/hgfs
输入vmware-hgfsclient,可以看到刚才设置的Windows的共享目录名称:

用于打开fstab文件 sudo vim /etc/fstab
点击 i 进入插入模式并在该文件的尾行添入.host:/ /mnt/hgfs fuse.vmhgfs-fuse allow_other 0 0
具体添加步骤截图这里不再描述。
添加之后的效果如下所示:

3,测试是否挂载成功
终端中执行如下命令 sudo mount -a
无报错代表添加成功:

重启后再次查看/mnt/hgfs目录,已经能够看到之前设置的目录名称:
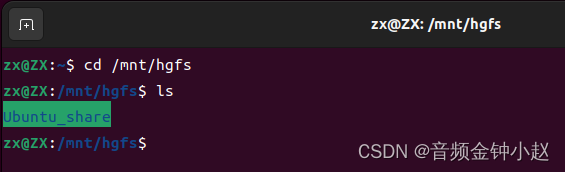
至此,配置完成。