服装网站设计策划书范文节省时间用wordpress
TIM定时器(第一部分)
- TIM(Timer)定时器
- 定时器可以对输入的时钟进行计数,并在计数值达到设定值时触发中断
- 16位计数器、预分频器、自动重装寄存器的时基单元,在72MHz计数时钟下可以实现最大59.65s的定时
- 不仅具备基本的定时中断功能,而且还包含内外时钟源选择、输入捕获、输出比较、编码器接口、主从触发模式等多种功能
- 根据复杂度和应用场景分为了高级定时器、通用定时器、基本定时器三种类型
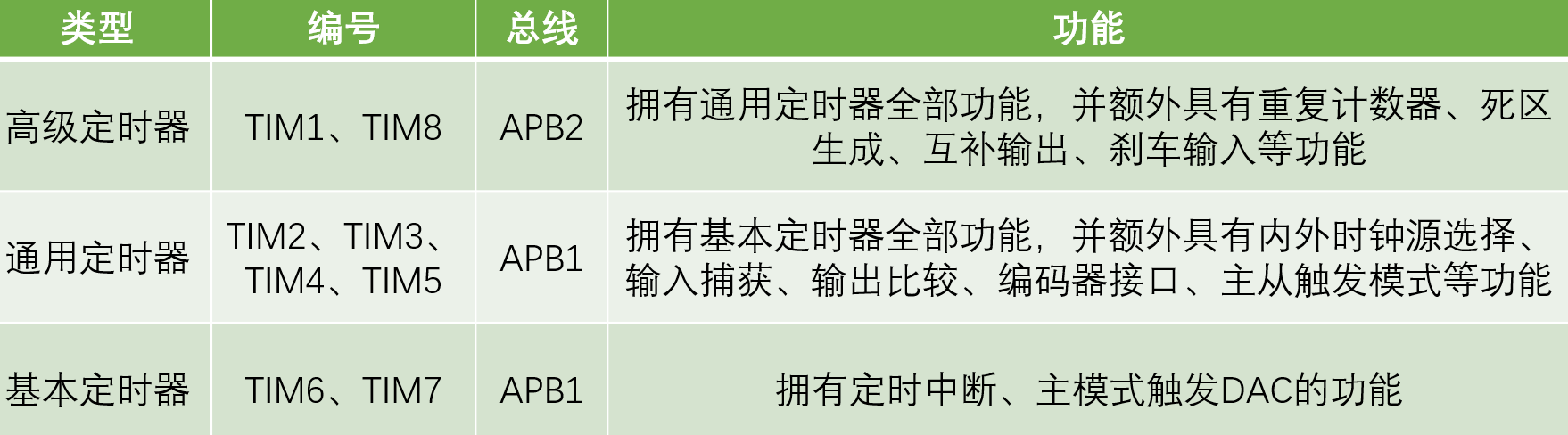
定时器类型
STM32F103C8T6定时器资源:TIM1、TIM2、TIM3、TIM4
定时器结构图
基本定时器
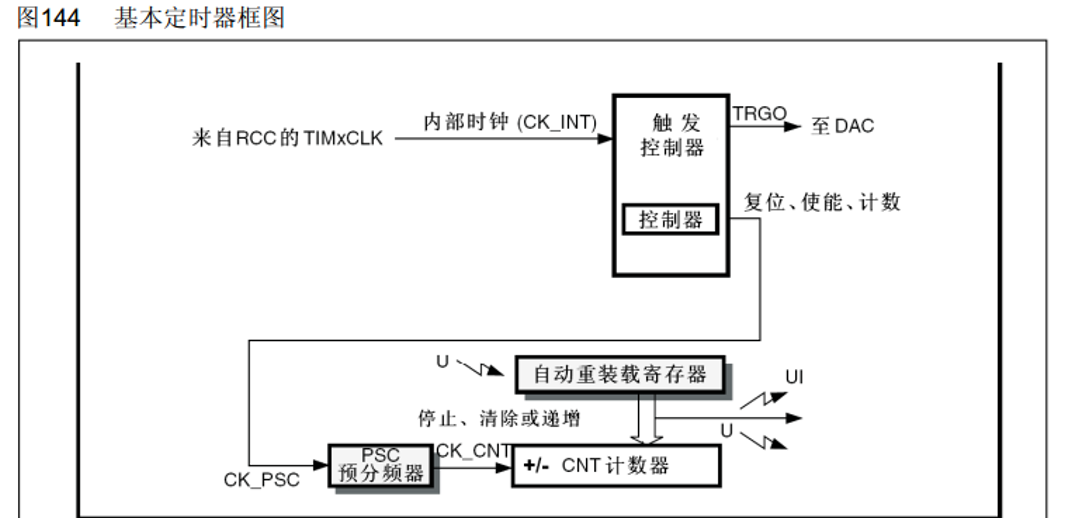
内部时钟一般为72Mhz, 预分频器就是把时钟频率分频,最高可以65536, 比如预分配器是2,那么时钟频率为24Mhz,计时器等于自动重装载寄存器的时候,就是计时时间到了,那它就会产生中断信号,并且清零计数器,计数器自动开始下一次的计数计时。
有黑色阴影的就是带有影子寄存器的缓冲机制。
通用定时器

先初始化TIM3,然后使用主模式把它的更新事件映射到TRGO上,接着再初始化TIM2,这里选择ITR2,对应的就是TIM3的TRGO,然后后面再选择时钟为外部时钟模式1,这样TIM3的更新事件就可以驱动TIM2的时基单元,也就实现了定时器的级联。
高级定时器

原本的通用定时器最高时间为59秒多,现在有了重复计数计数器后,就还需要再乘65536,提升了定时时间。
右边的输出引脚,由原来的一个变为了两个互补的输出,可以输出一对互补的PWM波,这些电路为了驱动三相无刷电机。
DTG寄存器就是高级定时器对输出比较模块的升级。
DTG(Dead Time Generate)死区生成电路:在开关切换的瞬间,由于器件的不理想,造成短暂的直通现象,所以才加入DTG, 在开关切换的瞬间,产生一定时长的死区,让桥臂的上下管全部关断,防止直通现象。
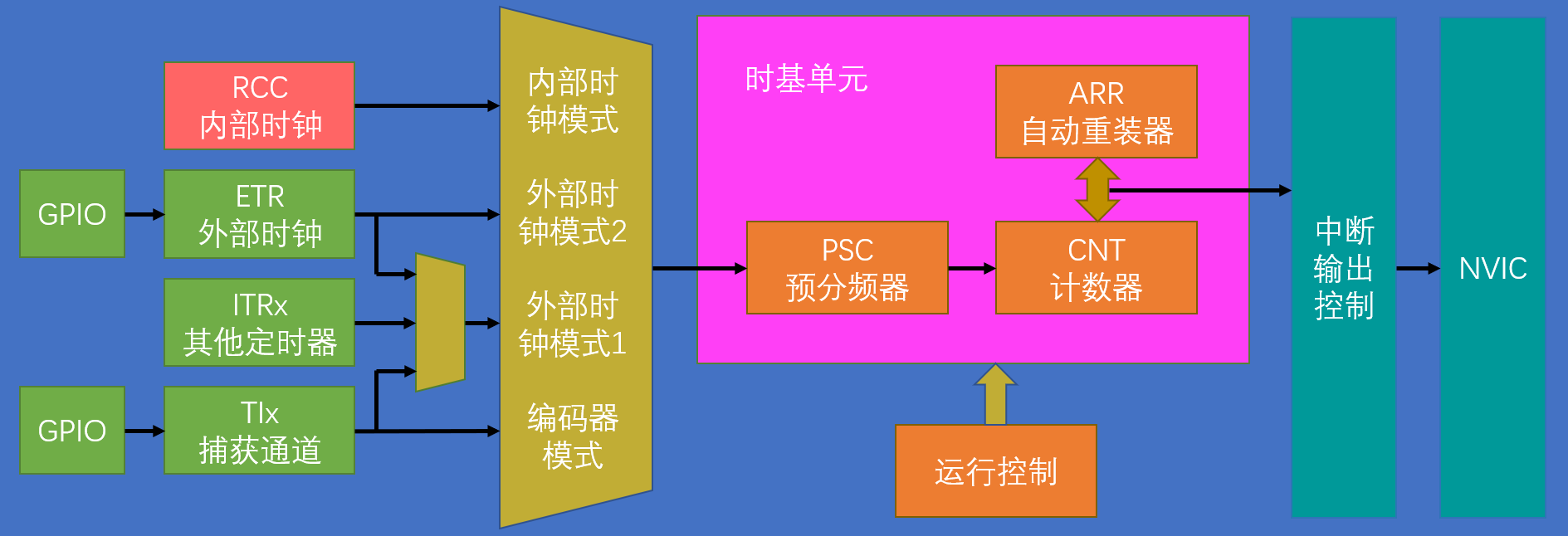
定时中断基本结构
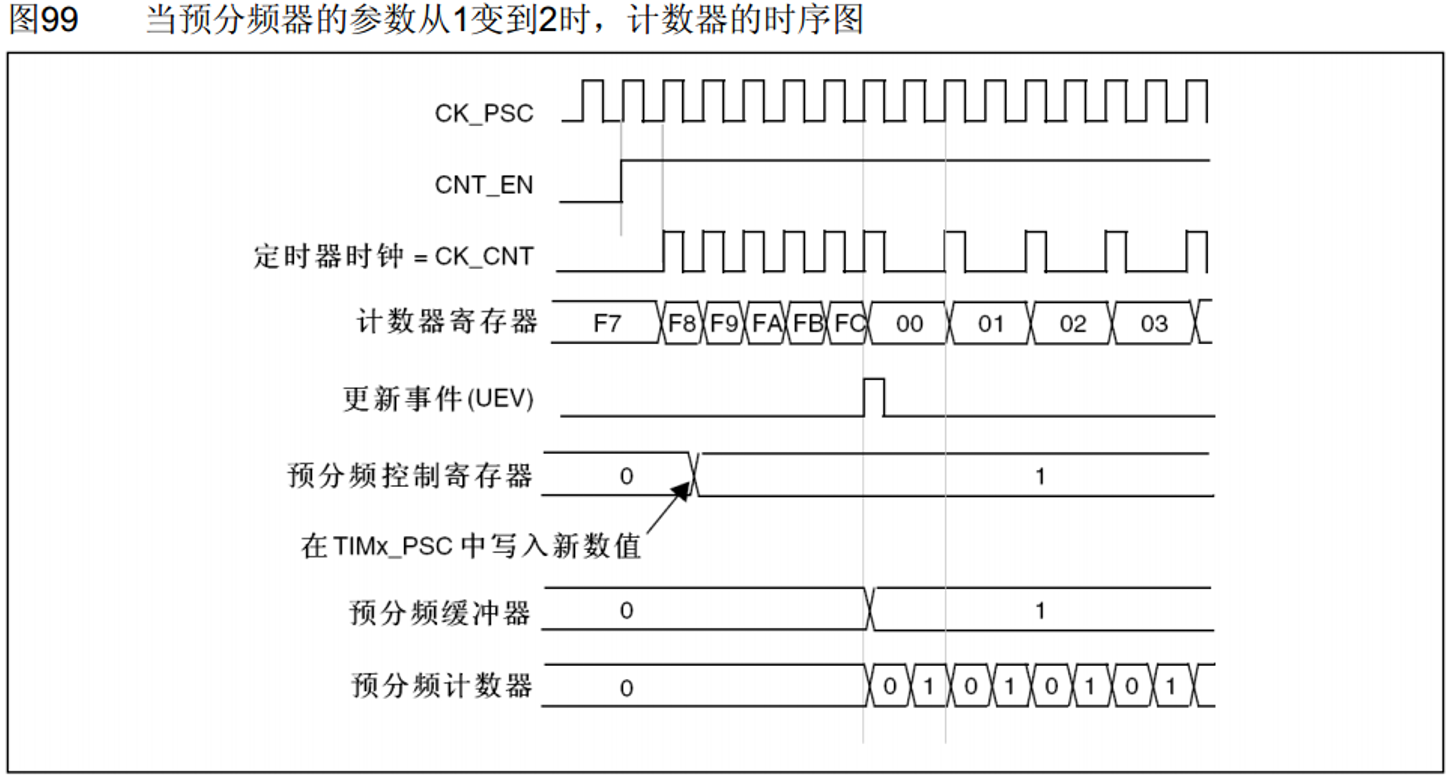
预分频器时序
计数器计数频率:CK_CNT = CK_PSC / (PSC + 1)
计数器时序
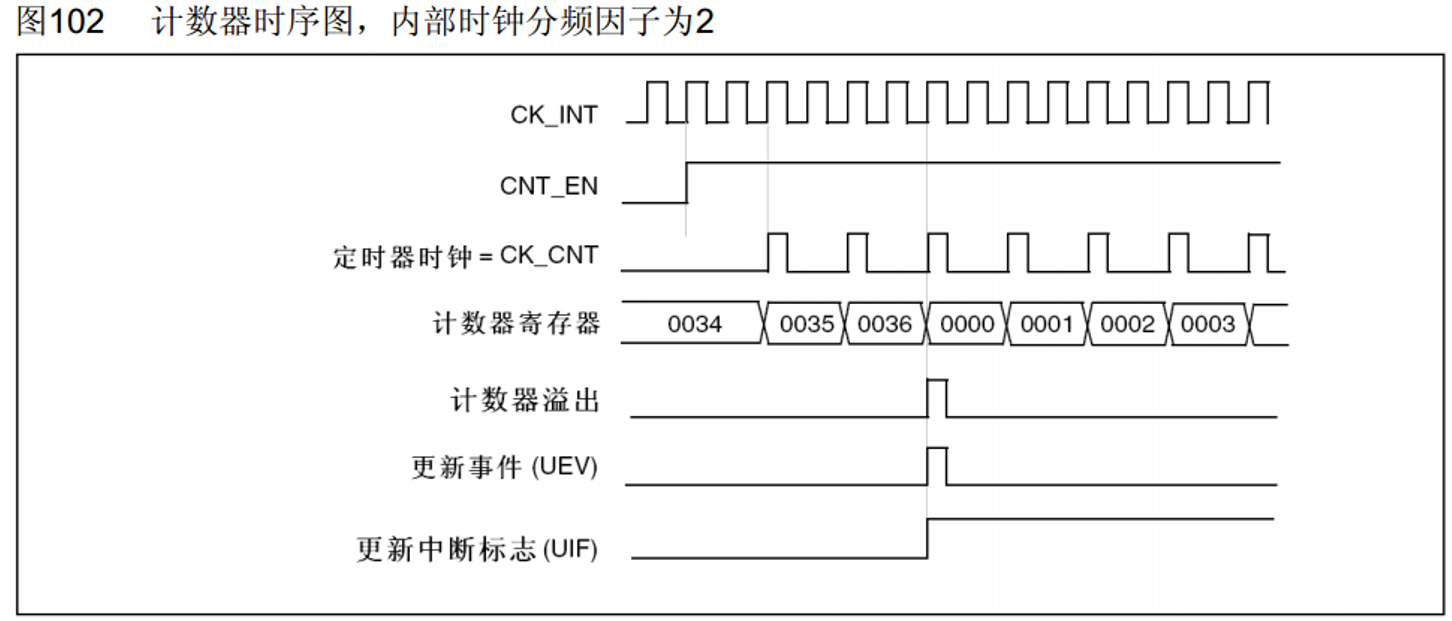
计数器溢出频率:CK_CNT_OV = CK_CNT / (ARR + 1)
把计数频率带入得 = CK_PSC / (PSC + 1) / (ARR + 1)
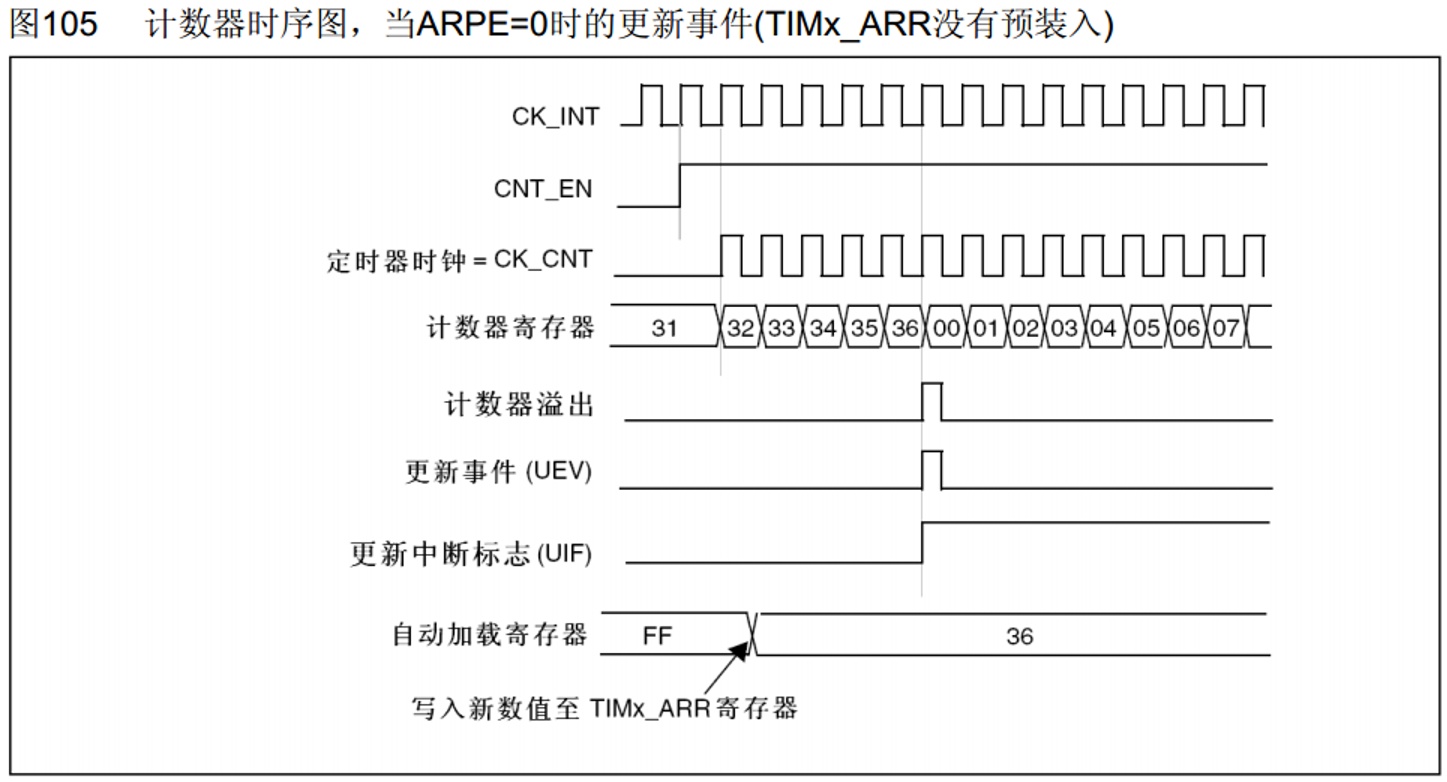
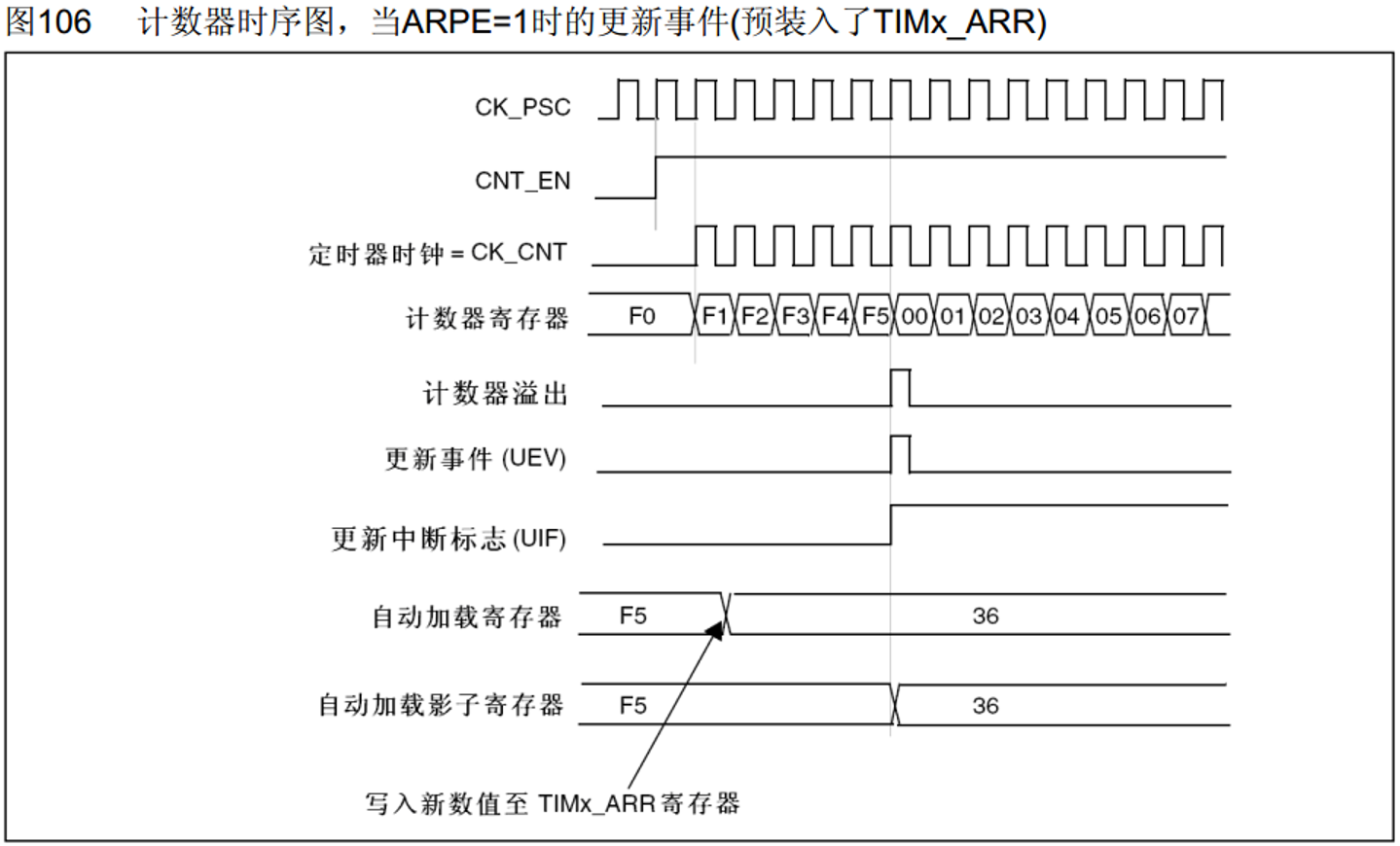
计时器有/无预装时序
ARPE就是控制有/无预装,0代表没有,1代表有
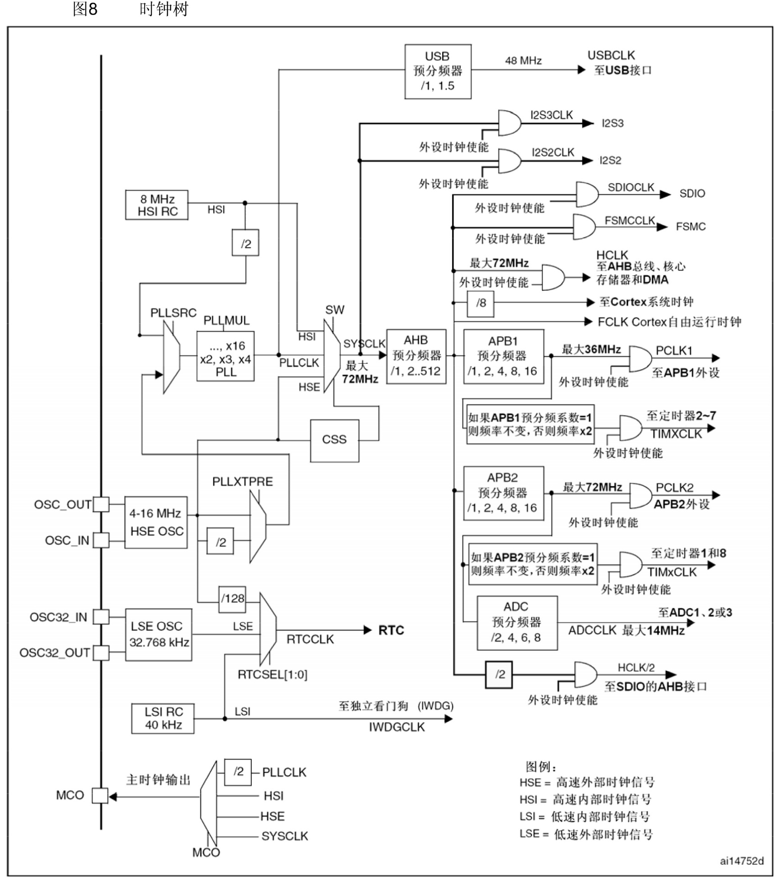
RCC时钟树
时钟树,STM32中用来产生和配置时钟,并且把配置好的时钟发送到各个外设的系统,时钟是所有外设运行的基础。
输出比较简介(第二部分)
- OC(Output Compare)输出比较
- 输出比较可以通过比较CNT与CCR寄存器值的关系,来对输出电平进行置1、置0或翻转的操作,用于输出一定频率和占空比的PWM波形
- 每个高级定时器和通用定时器都拥有4个输出比较通道
- 高级定时器的前3个通道额外拥有死区生成和互补输出的功能
CCR(捕获比较寄存器)
![]()
PWM
- PWM(Pulse Width Modulation)脉冲宽度调制
- 在具有惯性的系统中,可以通过对一系列脉冲的宽度进行调制,来等效地获得所需要的模拟参量,常应用于电机控速等领域
- PWM参数:频率 = 1 / TS 占空比 = TON / TS 分辨率 = 占空比变化步距
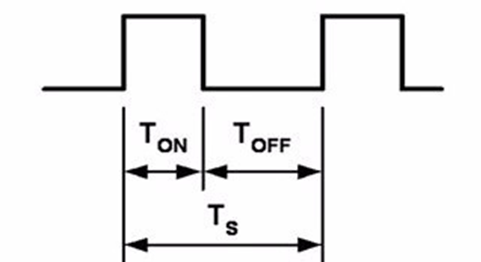
输出比较通道
通用

高级
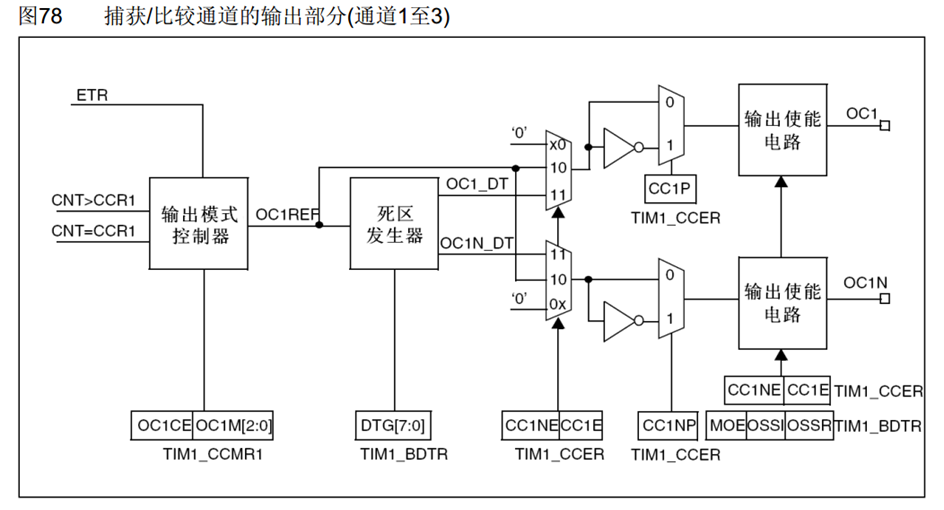
OC1和OC1N是两个互补的输出端口,分别控制上管和下管的导通和关闭。
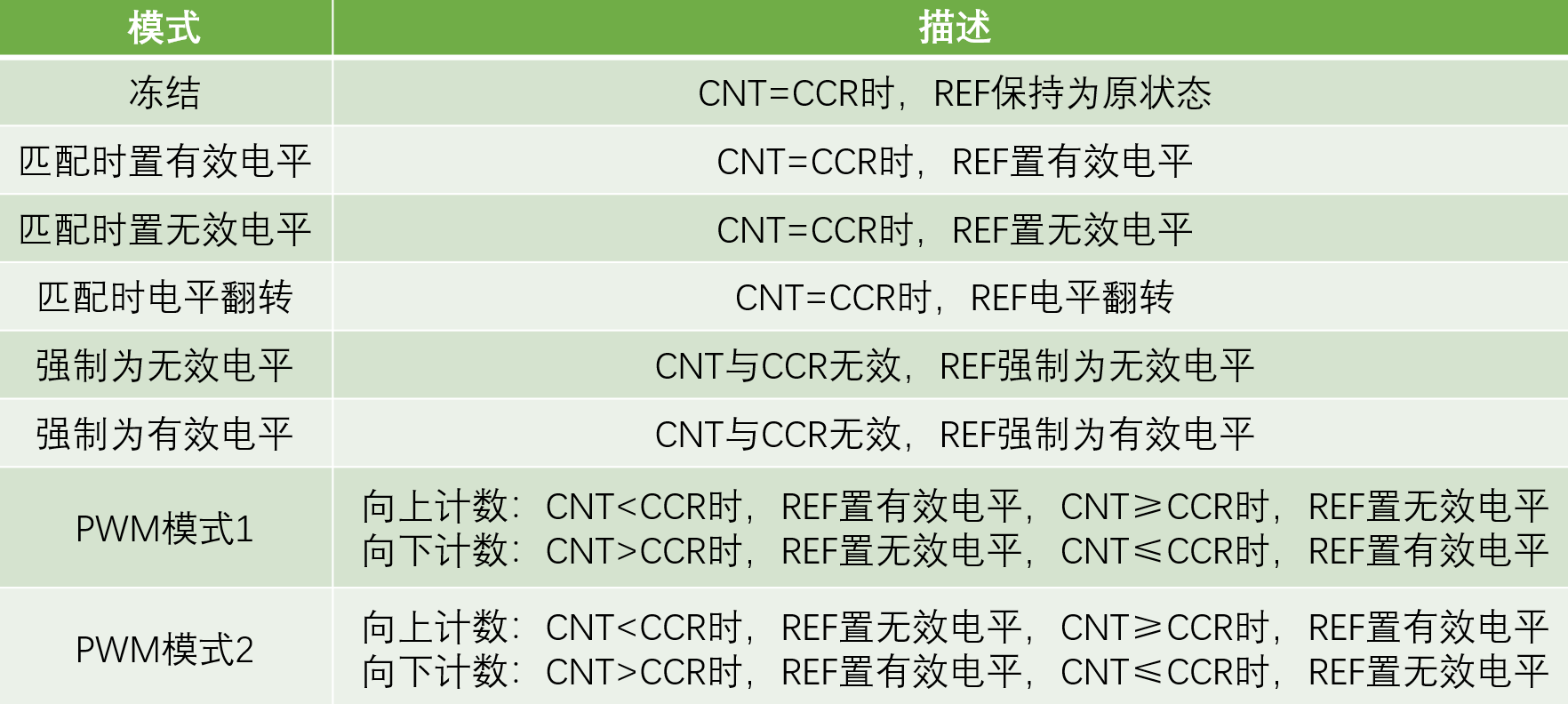
输出比较模式
PWM基本结构
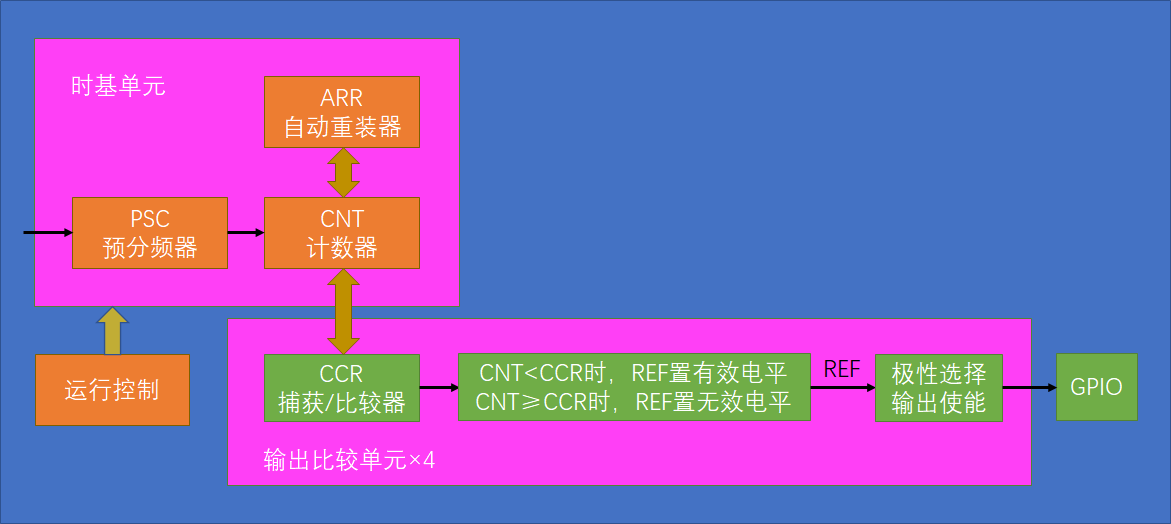
参数计算
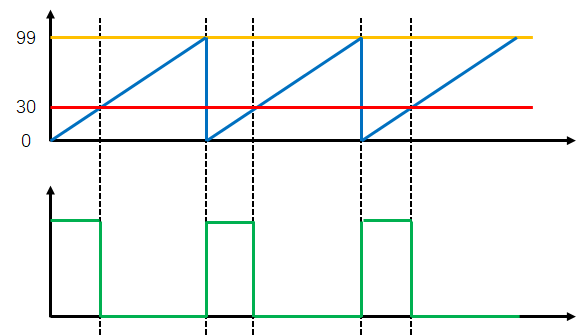
PWM频率: Freq = CK_PSC / (PSC + 1) / (ARR + 1)
PWM占空比: Duty = CCR / (ARR + 1)
PWM分辨率: Reso = 1 / (ARR + 1)
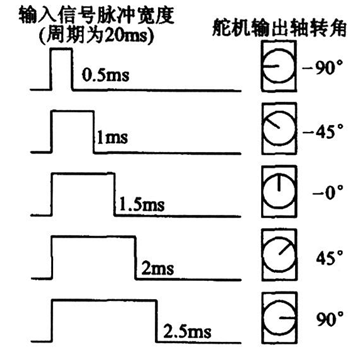
舵机简介
- 舵机是一种根据输入PWM信号占空比来控制输出角度的装置
- 输入PWM信号要求:周期为20ms,高电平宽度为0.5ms~2.5ms


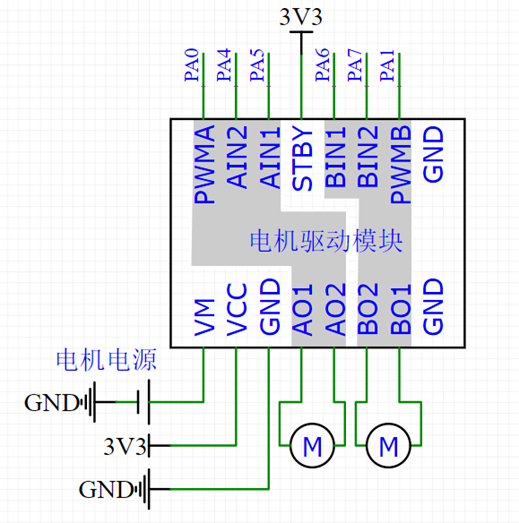
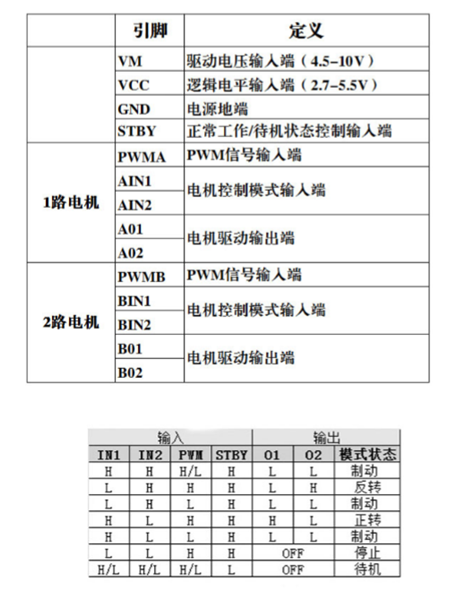
直流电机及驱动简介
- 直流电机是一种将电能转换为机械能的装置,有两个电极,当电极正接时,电机正转,当电极反接时,电机反转
- 直流电机属于大功率器件,GPIO口无法直接驱动,需要配合电机驱动电路来操作
- TB6612是一款双路H桥型的直流电机驱动芯片,可以驱动两个直流电机并且控制其转速和方向


硬件驱动电路
输入捕获简介(第三部分)
- IC(Input Capture)输入捕获
- 输入捕获模式下,当通道输入引脚出现指定电平跳变时,当前CNT的值将被锁存到CCR中,可用于测量PWM波形的频率、占空比、脉冲间隔、电平持续时间等参数
- 每个高级定时器和通用定时器都拥有4个输入捕获通道
- 可配置为PWMI模式,同时测量频率和占空比
- 可配合主从触发模式,实现硬件全自动测量
- 对于输入捕获和输出比较寄存器,只能使用其中一个,不能同时使用
频率测量
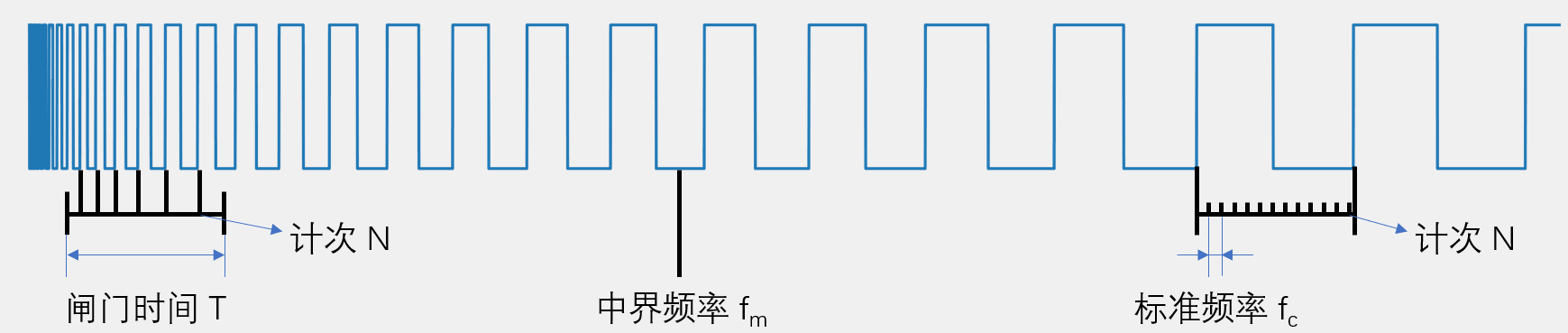

测频法适合测量高频信号、测周法适合测量低频信号
主从触发模式
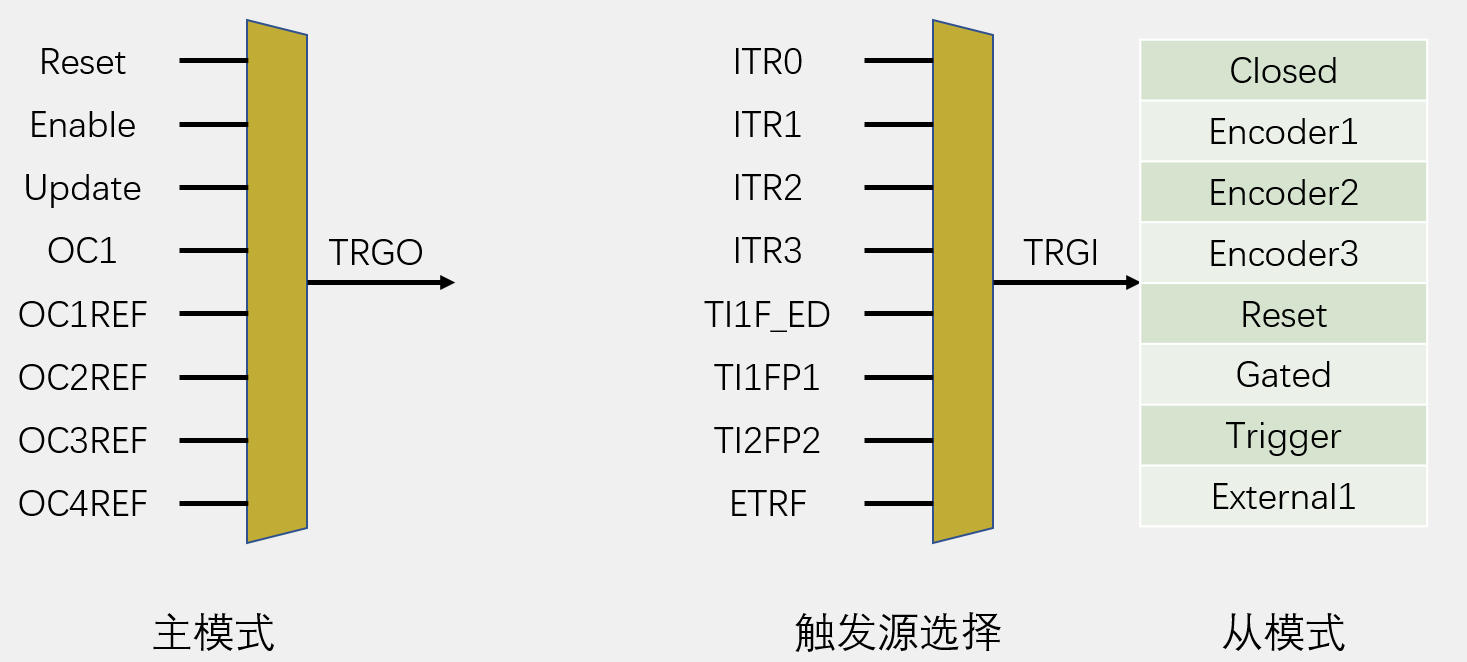
主模式可以将定时器内部的信号,映射到TRGO引脚,用于触发别的外设。
从模式是接收其他外设或者自身外设的一些信号,用于控制自身定时器的运行,也就是被别的信号控制。
触发源选择指定的一个信号得到TRGI,TRGI去触发从模式,从模式可以选择一项操作来自动执行。
输入捕获基本结构
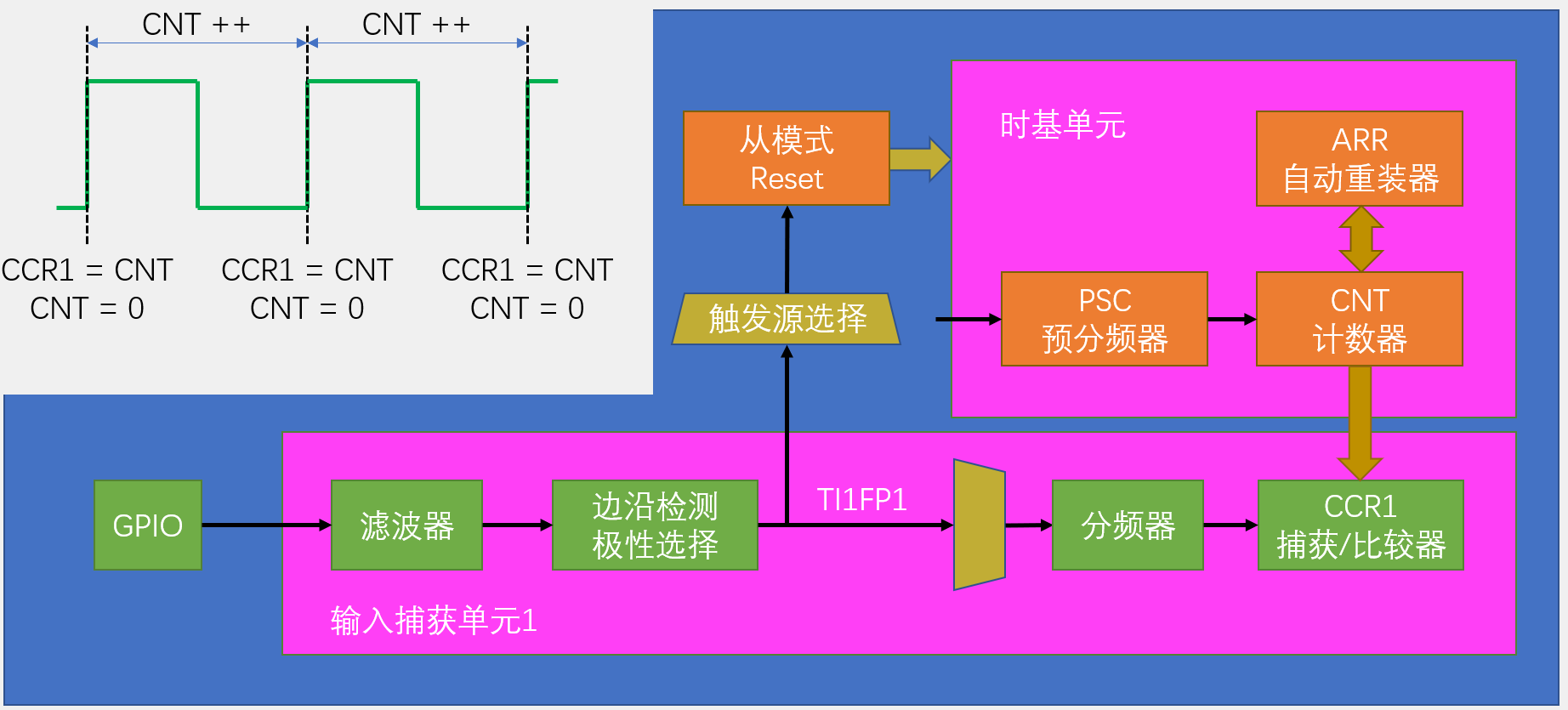
输入捕获一般来捕获频率。
PWMI基本结构
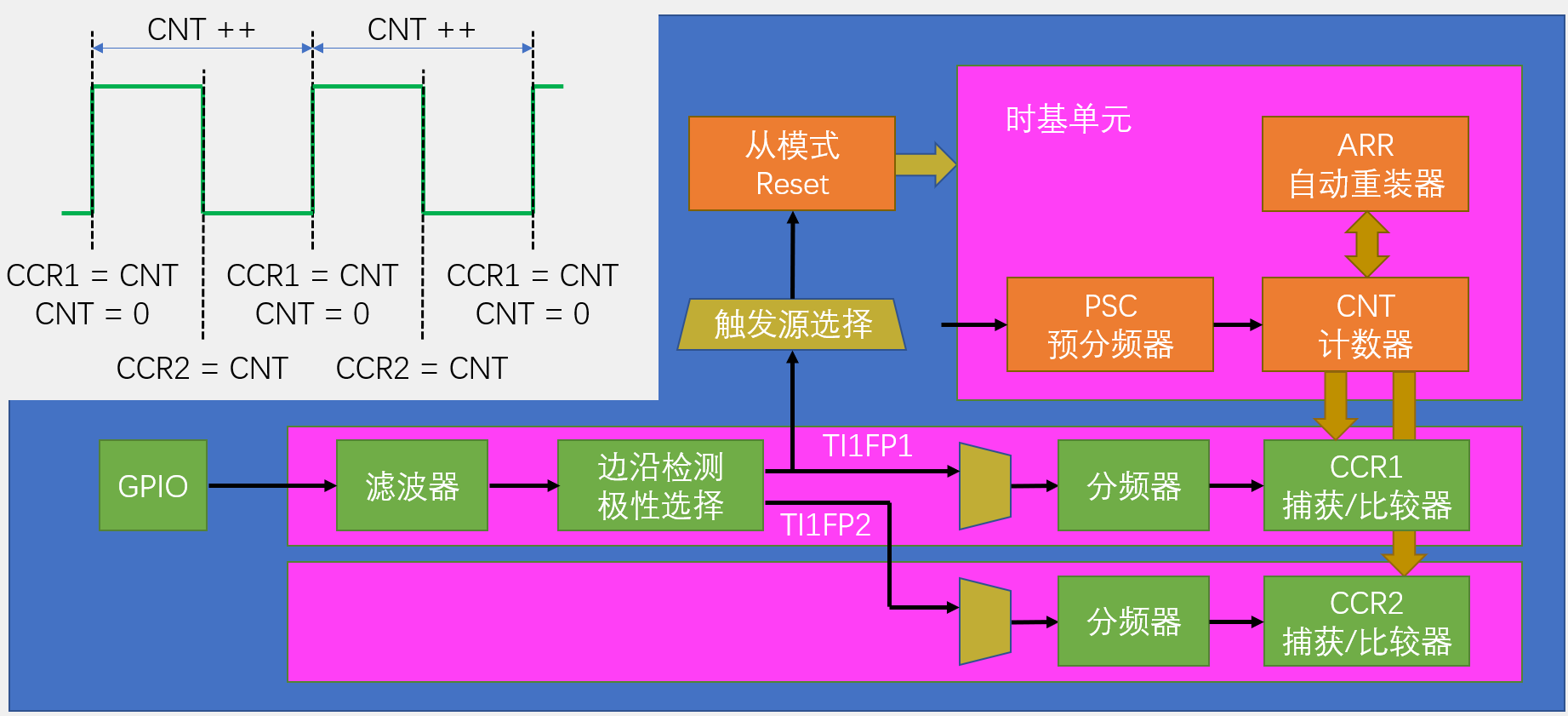
TI1FP1配置上升沿触发,触发捕获和清零CNT,正常捕获周期 ,然后再把TI1FP2配置为下降沿触发,通过交叉通道,去触发通道2的捕获单元。
PWMI一般来捕获频率和占空比。
TIM编码器接口(第四部分)
- Encoder Interface 编码器接口
- 编码器接口可接收增量(正交)编码器的信号,根据编码器旋转产生的正交信号脉冲,自动控制CNT自增或自减,从而指示编码器的位置、旋转方向和旋转速度
- 每个高级定时器和通用定时器都拥有1个编码器接口
- 两个输入引脚借用了输入捕获的通道1和通道2
编码器测速一般应用在电机控制的项目上,使用PWM驱动电机,再使用编码器测量电机的速度,然后再用PID算法进行闭环控制。
一个编码器有两个输出,一个是A相,一个是B相,然后接入到STM32,定时器的编码器接口,编码器接口自动控制定时器时基单元中的CNT计数器进行自增或自减,比如初始化后,CNT初始化为0,然后编码器右转,CNT++,右转产生一个脉冲,CNT就加一次,比如右转产生10个脉冲后,停下来,那么这个过程CNT就由0自增到10,比如编码器再左转产生5个脉冲,CNT就会在原本的10的基础上自减5。
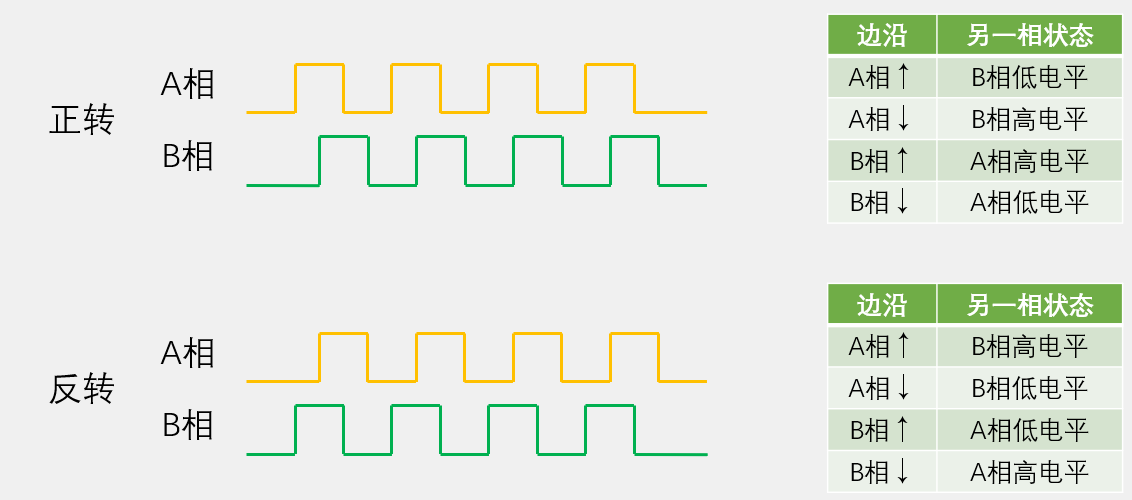
正交编码器
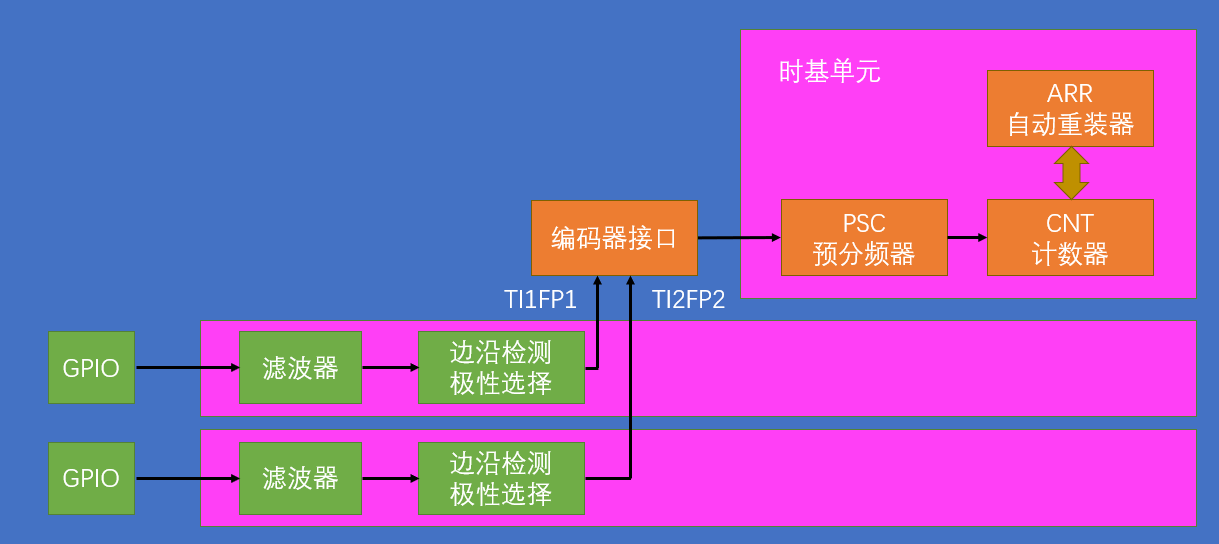
编码器接口基本结构
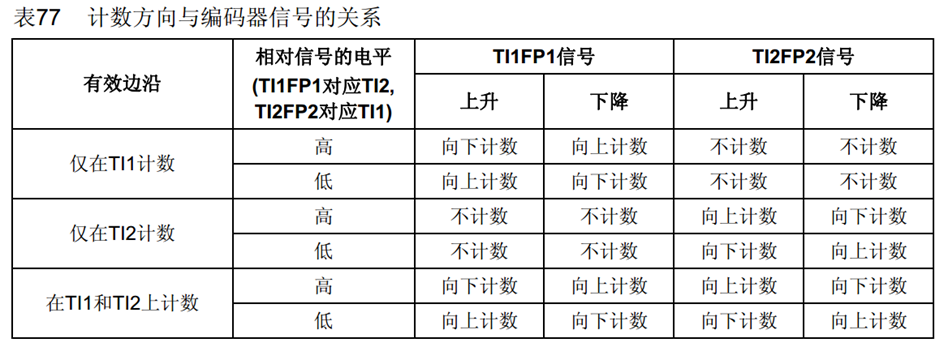
工作模式
正转的状态都向上计数,反转的状态都向下计数。
一般情况下用第三种工作模式。
举例(均不反向)

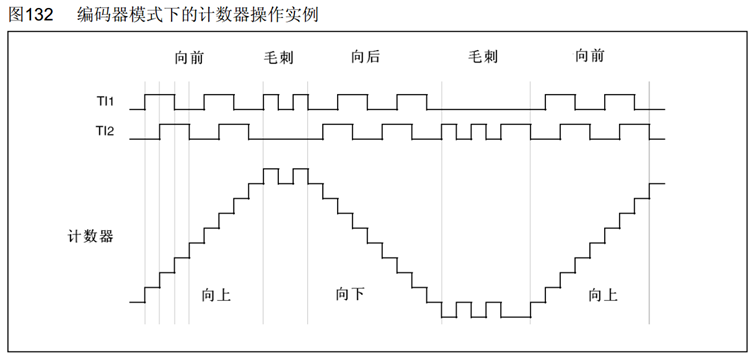
第一个状态,TI1上升沿,TI2低电平,查询上面表,上升沿并且低电平,就是向上计数,这就是正转。
毛刺展示的就是正交编码器抗噪声原理,TI2没有变化,但是TI1连续跳变,这不符合正交编码器的信号规律,正常情况下是两个输出交替变化。 所以出现了一个引脚不变,另一个引脚连续跳变多次的毛刺信号,计数器就会加减加减来回摆动,实现了抗噪声。
举例(TI1反向)

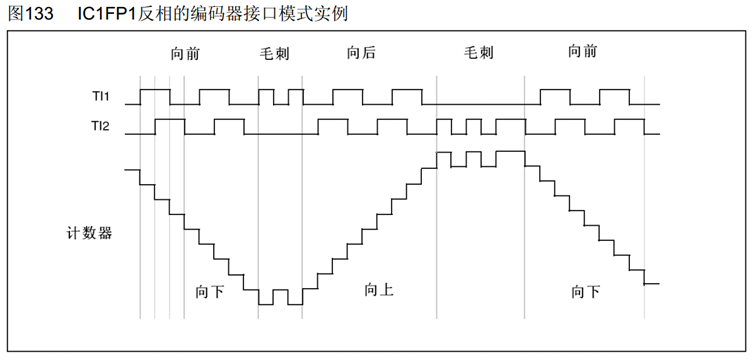
如果使用TIM_ICPolarity_Rising,那么就是均不反向;如果使用TIM_ICPolarity_Falling,那么就是反向。
这里的举例是TI1反向,可以根据极性来选择反不反向。
比如我原本想要正速度,但是是负速度,就可以选择这个反向,也可以交换两个引脚,交换极性。
代码部分
定时器中断配置代码部分
#include "Timer.h"extern uint16_t Num;void Timer_Init(void)
{RCC_APB1PeriphClockCmd(RCC_APB1Periph_TIM2, ENABLE); // 1.时钟使能TIM_InternalClockConfig(TIM2); // 2.选择时钟模式// TIM_ETRClockMode2Config(TIM2, TIM_ExtTRGPSC_OFF, TIM_ExtTRGPolarity_NonInverted, 0x0F); // 配置外部时钟2TIM_TimeBaseInitTypeDef TIM_TimeBaseInitSturcture; // 3.TIM初始化TIM_TimeBaseInitSturcture.TIM_ClockDivision = TIM_CKD_DIV1;TIM_TimeBaseInitSturcture.TIM_CounterMode = TIM_CounterMode_Up;TIM_TimeBaseInitSturcture.TIM_Period = 10000 - 1;TIM_TimeBaseInitSturcture.TIM_Prescaler = 7200 - 1; // 计算公式: 72Mz/(PSC+1)/(ARR+1)TIM_TimeBaseInitSturcture.TIM_RepetitionCounter = 0;TIM_TimeBaseInit(TIM2, &TIM_TimeBaseInitSturcture); TIM_ClearFlag(TIM2, TIM_FLAG_Update); // 手动更新中断标志位清除(因为单片机一上电就会中断,先清楚标志位)TIM_ITConfig(TIM2, TIM_IT_Update, ENABLE); // 4.配置时钟中断NVIC_PriorityGroupConfig(NVIC_PriorityGroup_2); // 5.设置NVIC优先级分组NVIC_InitTypeDef NVIC_InitStructure; // 6.配置NVICNVIC_InitStructure.NVIC_IRQChannel = TIM2_IRQn;NVIC_InitStructure.NVIC_IRQChannelCmd = ENABLE;NVIC_InitStructure.NVIC_IRQChannelPreemptionPriority = 2;NVIC_InitStructure.NVIC_IRQChannelSubPriority = 1; NVIC_Init(&NVIC_InitStructure);TIM_Cmd(TIM2, ENABLE); // 7.使能TIM2
}/* TIM2中断函数(用户自定函数) */
void TIM2_IRQHandler(void)
{if (TIM_GetITStatus(TIM2, TIM_IT_Update) == SET) // 检查TIM2中断是否发生{Num++;TIM_ClearITPendingBit(TIM2, TIM_IT_Update); // 清楚TIM2中断标志位}
}PWM配置代码部分
#include "Bsp_PWM.h"void PWM_Init(void)
{RCC_APB1PeriphClockCmd(RCC_APB1Periph_TIM2, ENABLE); // 1.TIM2时钟使能RCC_APB2PeriphClockCmd(RCC_APB2Periph_GPIOA, ENABLE); // 2.GPIOA时钟使能// RCC_APB2PeriphClockCmd(RCC_APB2Periph_AFIO, ENABLE); // 重映射设置// GPIO_PinRemapConfig(GPIO_PartialRemap1_TIM2, ENABLE); // 重新映射TIM2// GPIO_PinRemapConfig(GPIO_Remap_SWJ_JTAGDisable, ENABLE); // 如果需要使用重映射,但它是一个调试接口,则需要同时编写这两个接口。GPIO_InitTypeDef GPIO_InitStructure; // 3.配置GPIOGPIO_InitStructure.GPIO_Mode = GPIO_Mode_AF_PP;GPIO_InitStructure.GPIO_Pin = GPIO_Pin_0;GPIO_InitStructure.GPIO_Speed = GPIO_Speed_50MHz;GPIO_Init(GPIOA, &GPIO_InitStructure); TIM_TimeBaseInitTypeDef TIM_TimeBaseInitStructure; // 4.配置TIMTIM_TimeBaseInitStructure.TIM_ClockDivision = TIM_CKD_DIV1;TIM_TimeBaseInitStructure.TIM_CounterMode = TIM_CounterMode_Up;TIM_TimeBaseInitStructure.TIM_Period = 100 - 1; // ARR值(重装载值) TIM_TimeBaseInitStructure.TIM_Prescaler = 720 - 1; // PSC(预分频系数)TIM_TimeBaseInitStructure.TIM_RepetitionCounter = 0;TIM_TimeBaseInit(TIM2, &TIM_TimeBaseInitStructure);TIM_OCInitTypeDef TIM_OCInitStructure; // 5.TIM输出比较通道初始化TIM_OCStructInit(&TIM_OCInitStructure); // 结构指定初始值TIM_OCInitStructure.TIM_OCMode = TIM_OCMode_PWM1;TIM_OCInitStructure.TIM_OCPolarity = TIM_OCPolarity_High;TIM_OCInitStructure.TIM_OutputState = TIM_OutputState_Enable;TIM_OCInitStructure.TIM_Pulse = 90; // CCR(捕获/比较寄存器)TIM_OC1Init(TIM2, &TIM_OCInitStructure);TIM_Cmd(TIM2, ENABLE); // 6.TIM2使能}void PWM_SetCompare1(uint16_t Compare)
{TIM_SetCompare1(TIM2, Compare); // 设置TIM2 Capture Compare1寄存器值
}输入捕获配置代码部分
#include "IC.h"void IC_Init(void)
{RCC_APB2PeriphClockCmd(RCC_APB2Periph_GPIOA, ENABLE); // 1.开启时钟RCC_APB1PeriphClockCmd(RCC_APB1Periph_TIM3, ENABLE);GPIO_InitTypeDef GPIO_InitStructure; // 2.GPIO配置GPIO_InitStructure.GPIO_Mode = GPIO_Mode_IPU;GPIO_InitStructure.GPIO_Pin = GPIO_Pin_6;GPIO_InitStructure.GPIO_Speed = GPIO_Speed_50MHz;GPIO_Init(GPIOA, &GPIO_InitStructure);TIM_InternalClockConfig(TIM3); // 3.选择时钟模式TIM_TimeBaseInitTypeDef TIM_TimeBaseInitStructure; // 4.时基单元配置TIM_TimeBaseInitStructure.TIM_ClockDivision = TIM_CKD_DIV1;TIM_TimeBaseInitStructure.TIM_CounterMode = TIM_CounterMode_Up;TIM_TimeBaseInitStructure.TIM_Period = 65536 - 1;TIM_TimeBaseInitStructure.TIM_Prescaler = 72 - 1;TIM_TimeBaseInitStructure.TIM_RepetitionCounter = 0;TIM_TimeBaseInit(TIM3, &TIM_TimeBaseInitStructure);TIM_ICInitTypeDef TIM_ICInitStructure; // 5.输入捕获配置TIM_ICInitStructure.TIM_Channel = TIM_Channel_1;TIM_ICInitStructure.TIM_ICFilter = 0xF;TIM_ICInitStructure.TIM_ICPolarity = TIM_ICPolarity_Rising;TIM_ICInitStructure.TIM_ICPrescaler = TIM_ICPSC_DIV1;TIM_ICInitStructure.TIM_ICSelection = TIM_ICSelection_DirectTI;TIM_PWMIConfig(TIM3, &TIM_ICInitStructure);TIM_SelectInputTrigger(TIM3, TIM_TS_TI1FP1); // 6.触发源选择TIM_SelectSlaveMode(TIM3, TIM_SlaveMode_Reset); // 7.配置从模式TIM_Cmd(TIM3, ENABLE); // 8.开启TIM3时钟
}uint32_t IC_GetFreq(void)
{return 1000000 / (TIM_GetCapture1(TIM3) + 1); // fx = fc / N fc=72M/(PSC+1)=1M N(读取CCR的值)
}uint32_t IC_GetDuty(void)
{return (TIM_GetCapture2(TIM3) + 1) * 100 / (TIM_GetCapture1(TIM3) + 1); // Duty = CCR2 / CCR1 因为要显示整数,乘100。返回的值范围为0~100,对应占空比为0%~100%
}编码器配置代码部分
#include "Bsp_EncoderSpeed.h"void EncoderSpeed_Init(void)
{RCC_APB2PeriphClockCmd(RCC_APB2Periph_GPIOA, ENABLE); // 1.开启GPIOA时钟RCC_APB1PeriphClockCmd(RCC_APB1Periph_TIM3, ENABLE); // 2.开启TIM3时钟GPIO_InitTypeDef GPIO_InitStructure; // 3.GPIO配置GPIO_InitStructure.GPIO_Mode = GPIO_Mode_IPU; // 上拉输入GPIO_InitStructure.GPIO_Pin = GPIO_Pin_6 | GPIO_Pin_7;GPIO_InitStructure.GPIO_Speed = GPIO_Speed_50MHz;GPIO_Init(GPIOA, &GPIO_InitStructure);TIM_InternalClockConfig(TIM3); // 4.时钟模式选择(这里选择内部时钟)TIM_TimeBaseInitTypeDef TIM_TimeBaseInitStructure; // 5.TIM0配置TIM_TimeBaseInitStructure.TIM_ClockDivision = TIM_CKD_DIV1; // 分频系数TIM_TimeBaseInitStructure.TIM_CounterMode = TIM_CounterMode_Up; // 计数模式TIM_TimeBaseInitStructure.TIM_Period = 65536 - 1;TIM_TimeBaseInitStructure.TIM_Prescaler = 1 - 1;TIM_TimeBaseInitStructure.TIM_RepetitionCounter = 0; // 重复计数次数(当设为1时,需要进入2次中断,中断代码才生效)TIM_TimeBaseInit(TIM3, &TIM_TimeBaseInitStructure);TIM_ICInitTypeDef TIM_ICInitStructure; // 6.输入捕获配置TIM_ICStructInit(&TIM_ICInitStructure);TIM_ICInitStructure.TIM_Channel = TIM_Channel_1; // TIM频道1TIM_ICInitStructure.TIM_ICFilter = 0xF; // 输入捕获滤波器TIM_ICInit(TIM3, &TIM_ICInitStructure);TIM_ICInitStructure.TIM_Channel = TIM_Channel_2;TIM_ICInit(TIM3, &TIM_ICInitStructure);TIM_EncoderInterfaceConfig(TIM3, TIM_EncoderMode_TI12, TIM_ICPolarity_Rising, TIM_ICPolarity_Rising); // 7.编码器配置库函数TIM_Cmd(TIM3, ENABLE); // 8.使能TIM3 }/* 获得编码器速度 */
int16_t Encoder_GetSpeed(void)
{int16_t Temp;Temp = TIM_GetCounter(TIM3);TIM_SetCounter(TIM3, 0);return Temp;
}/* 获得编码器的CNT */
int16_t Encoder_GetCNT(void)
{return TIM_GetCounter(TIM3);
}不知道为什么我注释代码在VS code里面时排列整齐,到这就不整齐了,逼死强迫症患者。