网站后台管理要求西安烽盈网站建设推广
Java实现购买机票案例
- 需求分析
- 代码实现
- 小结Time
需求分析

1.首先,考虑方法是否需要接收数据处理?
阅读需求我们会发现,不同月份、不同原价、不同舱位类型优惠方案都不一样;
所以,可以将原价、月份、舱位类型写成参数
2.接着,考虑方法是否有返回值?
阅读需求我们发现,最终结果是求当前用户的优惠票价
所以,可以将优惠票价作为方法的返回值。
3.最后,再考虑方法内部的业务逻辑
先使用if判断月份是旺季还是淡季,然后使用switch分支判断是头等舱还是经济舱,计算 票价
代码实现
import java.util.Scanner;public class Test1 {public static double getPrice(int math,double price,String type) {//判断是那个月份购买机票if (math >= 5 && math <= 10) {//判断机舱类型switch (type) {case "头等舱":price *= 0.9;break;case "经济舱":price *= 0.85;break;}} else {switch (type) {case "头等舱":price *= 0.7;break;case "经济舱":price *= 0.65;break;}}//返回价格return price;}public static void main(String[] args) {Scanner scanner = new Scanner(System.in);System.out.println("请输入你买票的月份");int math = scanner.nextInt();System.out.println("请输入当前几机票的价格");double price = scanner.nextDouble();System.out.println("请输入你购买的舱的类型");String type = scanner.next();double getPrice = getPrice(math,price,type);System.out.println("优惠后的机票价钱是:"+getPrice);}
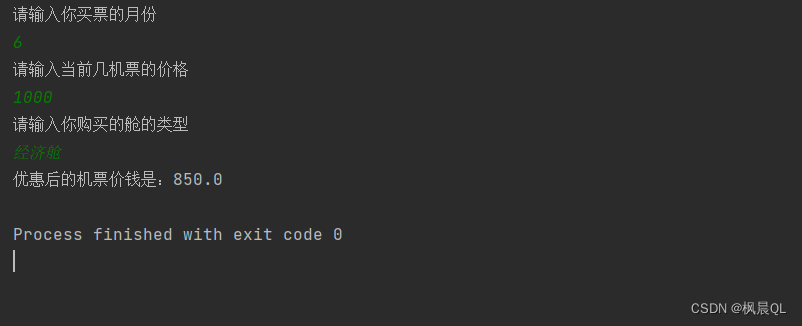
}运行结果
小结Time
多练习,加油!!