怎么样做推广网站网站上删除信息如何做
结果展示
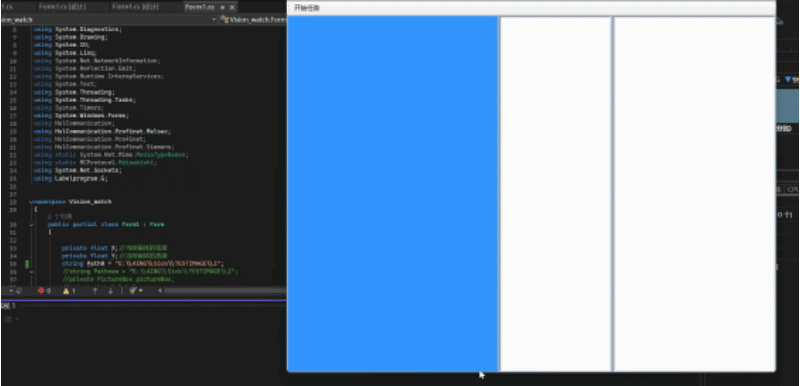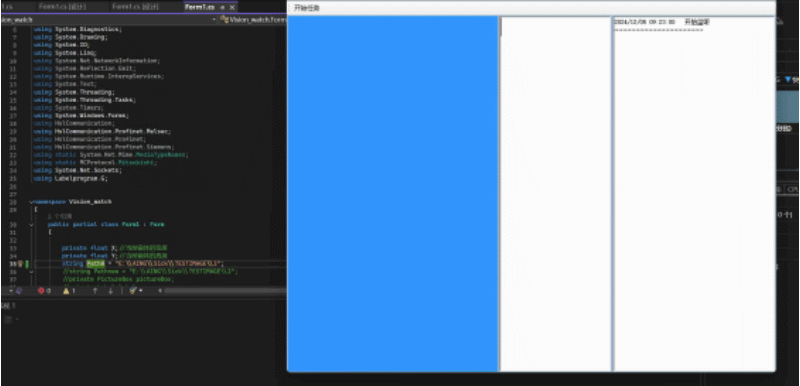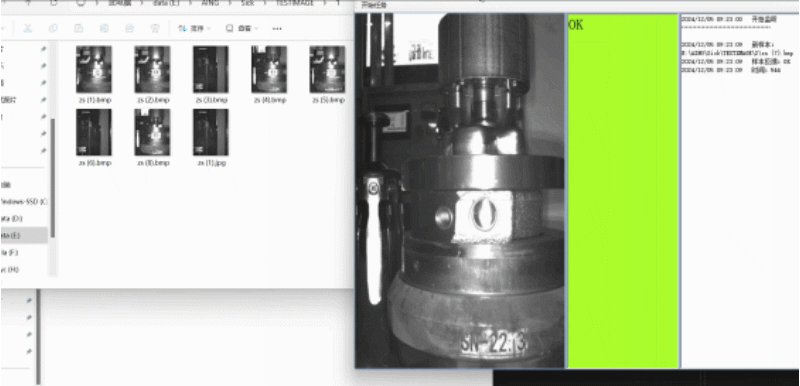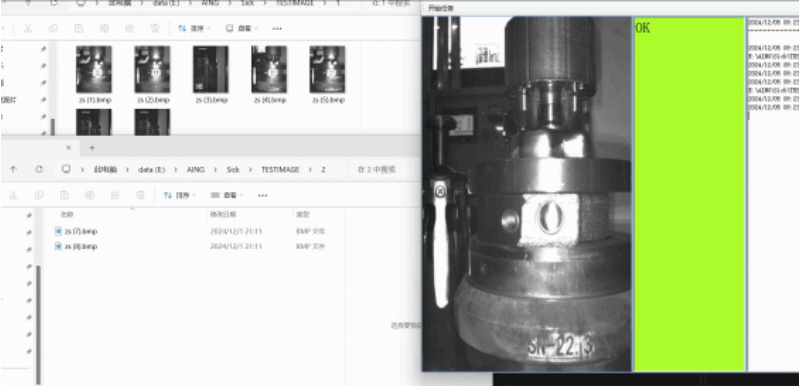
此类原理适用于文件夹中自动生成图片,并提取最新生成的图片将其显示,
如果你是相机采图将其保存到本地,可以用这中方法可视化,并将检测的结果和图片匹配
理论上任何文件都是可以监视并显示的,我这里只是做了一个图片的实例。
用vs2022或者其他的C#编写软件,创建一个winform程序
界面可以随意设计
主流程代码实例参考
private void btnStart_Click1(/*object sender, EventArgs e*/)
{// 创建FileSystemWatchertry{watcher = new FileSystemWatcher{Path = Path0,Filter = "*.bmp", // 可以根据需要修改为其它格式,如 *.pngNotifyFilter = NotifyFilters.FileName | NotifyFilters.LastWrite};//richTextBox2.Text = "开始监听……………………………………\n";log.AddInLog("开始监听……………………………………\n");// 订阅事件watcher.Created += OnNewImageAdded;// 启动监视器watcher.EnableRaisingEvents = true;//this.Load += (s,e) => LoadImages();}catch (Exception){log.AddInLog("请确认输入的图片格式或者读取路径是否有误!!!");}}监视事件并且触发显示样本部分
private void ShowNextImage()
{watch.Restart();if (imageFiles.Length == 0) return;currentIndex = (currentIndex + 1) % imageFiles.Length; // 循环显示图片var imagePath = imageFiles[currentIndex];var latestImage = imageFiles.LastOrDefault();while (true){if (File.Exists(latestImage))//判断文件是否存在 为了保险 实际消息触发文件必存在{long fileSize = new FileInfo(latestImage).Length;Thread.Sleep(20);if (fileSize > 0.02 * 1024 * 1024) //MB转化为字节 判断当前文件大小{Thread.Sleep(500);//在等一会break;}}else{break;}}//await Task.Delay(100);//string ss = "E:\\AING\\Sick\\TESTIMAGE\\1\\1.bmp";Bitmap map = new Bitmap(latestImage);int width1 = 960;int height1 = 1280;Bitmap mapsizes = ResizeImage(map, width1, height1);//mapsizes.Save("E:\\AING\\Sick\\TESTIMAGE\\2\\9.jpg");// 显示最新添加的图片if (!string.IsNullOrEmpty(latestImage)){pictureBox1.Image?.Dispose();pictureBox1.Image = mapsizes; watch.Stop();//ReceiveDataAsync();//if (message == "OK")//{// richTextBox1.Text = message;// richTextBox1.BackColor = Color.GreenYellow;//}//else if (message == "NG")//{// richTextBox1.Text = message;// richTextBox1.BackColor = Color.Red;//}//richTextBox2.Text = watch.ElapsedMilliseconds.ToString() + " ms";//richTextBox2.Text = "最新样本路径: " + latestImage + " \n样本检测反馈结果: \n" + message + "\n\n" + "Time:" + watch.ElapsedMilliseconds.ToString() + " ms";log.AddInLog("新样本:\n" + latestImage);log.AddInLog("样本反馈:" + message);log.AddInLog("时间:" + watch.ElapsedMilliseconds.ToString());}
}链接tcp接收结果字符串部分
private void MCProtocolLibTest()
{try{client = new TcpClient("192.168.0.2", 5000); // 服务器地址和端口stream = client.GetStream();log.AddInLog("192.168.0.2 连接成功…… \n");// 开始接收数据 //Thread.Sleep(1000);ReceiveDataAsync();}catch (Exception){richTextBox2.Text = "192.168.0.2 连接失败…… \n";}
}
private async Task ReceiveDataAsync()
{byte[] buffer = new byte[1024];int bytesRead;try{while ((bytesRead = await stream.ReadAsync(buffer, 0, buffer.Length)) != 0){message = Encoding.UTF8.GetString(buffer, 0, bytesRead);if (message == "OK"){richTextBox1.Text = message;richTextBox1.BackColor = Color.GreenYellow;}else if (message == "NG"){richTextBox1.Text = message;richTextBox1.BackColor = Color.Red;}//message = displayText;//UpdateLabel(message); // 更新Label控件}}catch (Exception ex){richTextBox1.Text = "数据接收出现问题……";//MessageBox.Show("接收数据时出现错误: " + ex.Message);}
}
private void UpdateLabel(string message)
{if (richTextBox2.InvokeRequired){richTextBox2.Invoke(new Action<string>(UpdateLabel), message);}else{richTextBox2.Text += message + Environment.NewLine; // 显示接收到的消息}
}样本多了可能导致内存盘崩盘 所以你可以设置一个每周一提示是否删除文件夹中的所有图片
private void Form1_Load2(/*object sender, EventArgs e*/)
{// 检查当前日期是否为周一if (DateTime.Today.DayOfWeek == DayOfWeek.Monday){// 显示删除确认对话框DialogResult result = MessageBox.Show("今天是周一是否清空文件夹中采集的样本!!!", "删除确认", MessageBoxButtons.YesNo);if (result == DialogResult.Yes){// 指定文件夹路径string folderPath = Path0;// 删除文件夹中的所有图片文件if (Directory.Exists(folderPath)){string[] files = Directory.GetFiles(folderPath, "*.bmp");foreach (string file in files){File.Delete(file);}MessageBox.Show("图片删除成功!");}else{MessageBox.Show("指定文件夹不存在!");}} }