宿州网站建设价格中国机械加工网站
1.介绍
JSON Web Token(JWT)是为了在网络应用环境间传递声明而执行的一种基于JSON的开放标准。这个规范允许我们使用JWT在用户和服务器之间传递安全可靠的信息。该token被设计为紧凑且安全的,特别适用于分布式站点的单点登录(SSO)场景。
2.Jwt组成

头部(Header)(非敏感)
头部用于描述关于该JWT的最基本的信息,例如其类型以及签名所用的算法等。这也可以被表示成一个JSON对象。
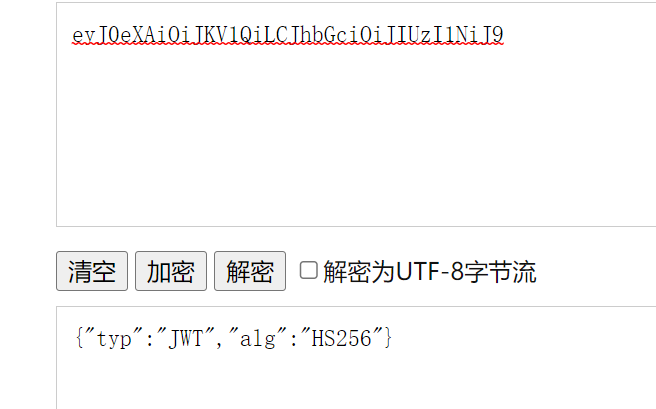
{"typ":"JWT","alg":"HS256"}在头部指明了签名算法是HS256算法。 我们进行BASE64编码https://www.qqxiuzi.cn/bianma/base64.htm,编码后的字符串如下:
eyJ0eXAiOiJKV1QiLCJhbGciOiJIUzI1NiJ9
载荷(playload)(非敏感数据)
载荷就是存放有效信息的地方。该部分的信息是可以自定义的定义一个payload:
{"sub":"1234567890","name":"John Doe","admin":true}然后将其进行base64编码,得到Jwt的第二部分。
eyJzdWIiOiIxMjM0NTY3ODkwIiwibmFtZSI6IkpvaG7CoERvZSIsImFkbWluIjp0cnVlfQ==
签证(signature)
jwt的第三部分是一个签证信息,这个签证信息由三部分组成:
签名算法( header (base64后的).payload (base64后的) . secret )这个部分需要base64加密后的header和base64加密后的payload使用.连接组成的字符串,然后通过header中声明的加密方式进行加盐secret秘钥组合加密,然后就构成了jwt的第三部分。TJVA95OrM7E2cBab30RMHrHDcEfxjoYZgeFONFh7HgQ
将这三部分用.连接成一个完整的字符串,构成了最终的jwt:
eyJ0eXAiOiJKV1QiLCJhbGciOiJIUzI1NiJ9.eyJzdWIiOiIxMjM0NTY3ODkwIiwibmFtZSI6IkpvaG7CoERvZSIsImFkbWluIjp0cnVlfQ==.TJVA95OrM7E2cBab30RMHrHDcEfxjoYZgeFONFh7HgQ
3.入门
<dependencies><dependency><groupId>io.jsonwebtoken</groupId><artifactId>jjwt</artifactId><version>0.9.1</version></dependency><dependency><groupId>junit</groupId><artifactId>junit</artifactId><version>4.12</version><scope>test</scope></dependency>
</dependencies>
3.1 生成令牌
@Test
public void testGenerate(){String compact = Jwts.builder().setId(UUID.randomUUID().toString())//设置唯一标识.setSubject("TEST") // 设置主题.claim("name", "赵金麦") //自定义信息.claim("age", 26) //自定义信息//.setExpiration(new Date()) //设置过期时间.setIssuedAt(new Date()) //令牌签发时间.signWith(SignatureAlgorithm.HS256, "HELLOWORLD").compact();//签名算法, 秘钥System.out.println(compact);
}
打印消息如下:
eyJhbGciOiJIUzI1NiJ9.eyJqdGkiOiI2ZjNkOGQxMi1lMTUzLTQ5MzctYTRmMi0wNjY0ZTE0ZDBjYWUiLCJzdWIiOiJURVNUIiwibmFtZSI6Iui1temHkem6piIsImFnZSI6MjYsImlhdCI6MTY4NDAzMzA2NH0.DDYMtiVZBnicaZqbnwl-MvfZK5xhGu6hkJKGgKqc2Ik
注意:
//如果 SignatureAlgorithm.HS256 报红。
//请检查下 SignatureAlgorithm 导包是否正确:
import io.jsonwebtoken.SignatureAlgorithm;
3.2 校验令牌
@Test
public void testVerify(){String jwt = "eyJhbGciOiJIUzI1NiJ9.eyJqdGkiOiI2ZjNkOGQxMi1lMTUzLTQ5MzctYTRmMi0wNjY0ZTE0ZDBjYWUiLCJzdWIiOiJURVNUIiwibmFtZSI6Iui1temHkem6piIsImFnZSI6MjYsImlhdCI6MTY4NDAzMzA2NH0.DDYMtiVZBnicaZqbnwl-MvfZK5xhGu6hkJKGgKqc2Ik
";Claims claims = Jwts.parser().setSigningKey("HELLOWORLD").parseClaimsJws(jwt).getBody();System.out.println(claims);
}
解析结果如下:

当我们对令牌进行任何部分(header , payload , signature)任何部分进行篡改, 都会造成令牌解析失败 ;
LocalStorage :
<script>localStorage.setItem("name", "ithiema");alert(localStorage.getItem("name"))localStorage.removeItem("name");
</script>
4 JWT 原理
- 在服务器身份验证之后,将生成一个JSON对象并将其发送回用户,示例如下:{“UserName”: “Chongchong”,“Role”:
- “Admin”,“Expire”: “2018-08-08 20:15:56”} 之后,当用户与服务器通信时,客户在请求中发回JSON对象
- 为了防止用户篡改数据,服务器将在生成对象时添加签名,并对发回的数据进行验证
5 JWT的验证过程
它验证的方法其实很简单,只要把header做base64url解码,就能知道JWT用的什么算法做的签名,然后用这个算法,再次用同样的逻辑对header和payload做一次签名,并比较这个签名是否与JWT本身包含的第三个部分的串是否完全相同,只要不同,就可以认为这个JWT是一个被篡改过的串,自然就属于验证失败了。接收方生成签名的时候必须使用跟JWT发送方相同的密钥。
注1:在验证一个JWT的时候,签名认证是每个实现库都会自动做的,但是payload的认证是由使用者来决定的。因为JWT里面可能会包含一个自定义claim,所以它不会自动去验证这些claim,以jjwt-0.7.0.jar为例:A 如果签名认证失败会抛出如下的异常:io.jsonwebtoken.SignatureException: JWT signature does not match locally computed signature. JWT validity cannot be asserted and should not be trusted.即签名错误,JWT的签名与本地计算机的签名不匹配B JWT过期异常io.jsonwebtoken.ExpiredJwtException: JWT expired at 2017-06-13T11:55:56Z. Current time: 2017-06-13T11:55:57Z, a difference of 1608 milliseconds. Allowed