哈尔滨做网站哪家好强平价建网站格
一个网友吐槽道:
“ 建站出来了,你们说程序员会失业。
低代码出来了,你们说程序员会失业。
Copilot出来了,你们说程序员会失业。
Chatgpt出来了,你们说程序员会失业······
虽然这只是网友的吐槽,但却引起了小编的好奇。为何程序员那么容易被新技术取代?今天小编打算跟大家好好唠唠这个话题。
失业这些事
首先,我们先来了解下失业这件事。
失业本质就是用人市场的供需不匹配。经济学一般将失业划分为以下四种,即“结构性失业、季节性失业、周期性失业和摩擦性失业”,具体定义如下表:
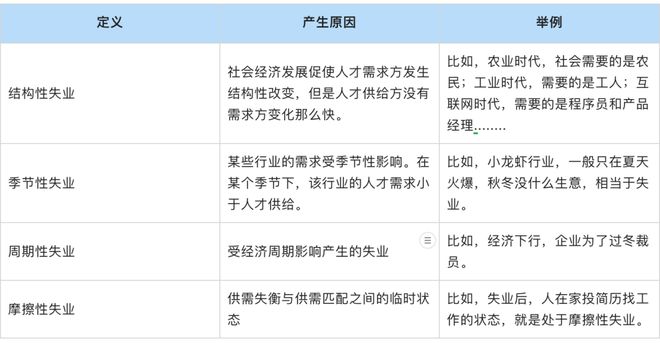
我们在网上常见到的“低代码导致程序员失业”中的失业,其实属于“结构性失业”的一种。人们潜在的逻辑是,程序员干的活,ChatGPT、低代码也能干,甚至能更快更好的完成。所以原本从事程序员工种的人会被淘汰。
但是,人们忽略