建筑人才招聘网站平台广州响应式网站建设
GPT现在已经进入了淘金时代。虽然全球涌现出成千上万的大模型或ChatGPT变种,但一直能挣钱的人往往是卖铲子的人。
这不,围绕暴风眼中的大模型,已经有不少企业,开始研究起了大模型的“铲子”产品,而且开源和付费两不误。
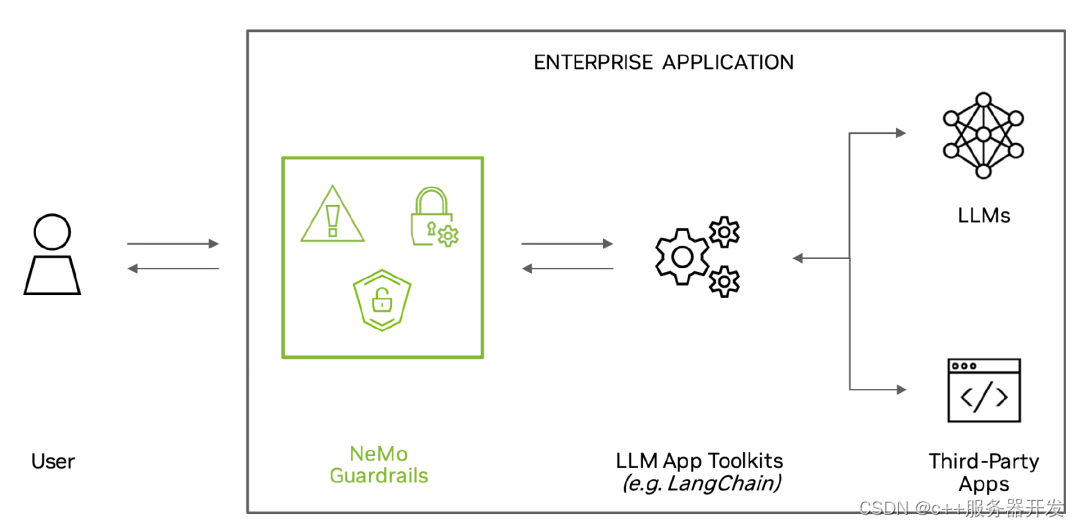
一、英伟达:给大模型上安全护栏
不管ChatGPT能不能笑到最后,英伟达肯定是大赢家。做大模型的生意不止是芯片,还有工具和服务。
大模型会产生“幻觉”,是一个被人诟病的事实。英伟达很快就打造了一个“安全护栏”NeMo Guardrails,它充当一种针对基于大型语言模型 (LLM) 构建的应用程序的检查器,而且这个“铲子”已经在Github上开源了。
有了它,大模型应用的开发者可以轻松开发安全可靠的LLM对话系统。NeMo Guardrails可以与所有LLM一起使用,包括OpenAI的ChatGPT。
该工具包由社区构建的工具包提供支持,例如LangChain,它在短短几个月内就在GitHub上收集了约3万颗星。这些工具包提供可组合、易于使用的模板和模式,通过将LLM、API和其他软件包粘合在一起来构建LLM支持的应用程序。
Nvidia应用研究副总裁Jonathan Cohen昨天在与记者的简报会上谈到了这款新软件,并表示:“Guardrails是一个很好的向导,有助于保持人与人工智能之间的对话正常进行。”
据称,NeMo Guardrails使开发人员能够设置三种护栏:
局部护栏:“防止应用程序转向不需要的区域”。Cohen给出了一个例子是:一名员工询问人力资源聊天机器人哪些员工收养了孩子。护栏阻止聊天机器人尝试回答这个问题。
Safety护栏:是一个广泛的类别,包括事实核查(防止幻觉)、过滤掉不需要的语言和防止仇恨内容。
Security护栏:限制应用程序仅与已知安全的外部第三方应用程序建立连接。
开发人员还可以“用几行代码”创建自己的自定义规则。NeMo Guardrails可以在各种使用LLM的工具上运行。简报中提到的第一个是LangChain,它是开发人员用来将第三方应用程序插入LLM的开源工具包。它还能与支持LLM的应用程序(例如Zapier)一起使用。
值得注意的是,开源归开源,不影响变现。集成到产品中却是要付费的。
虽然NeMo Guardrails可以通过GitHub单独使用,但Nvidia也将其集成到他们自己的几个产品中。它在 NeMo 框架中可用,“其中包括用户使用公司专有数据训练和调整语言模型所需的一切。” 此外,Nvidia已将其作为一项单独的付费服务提供。
1.事实核查:用大模型来监管大模型
那么,如何防止幻觉呢?
有趣的是,作为Safety护栏的一部分,事实核查不是由人完成的,而是由另一个LLM完成的。Cohen解释说,这是因为组织可以定制和培训LLM,使其成为特定数据的事实核查员。
“在非常具体的任务上使用大量数据训练语言模型也有很多价值,我们(包括社区)有很多证据,比如当你用大量的例子对这些模型进行微调时,它们实际上可以表现得更好。”
2.如何实现的?无限套娃!
在一篇技术博客文章中,Nvidia表示NeMo Guardrails是建立在Colang之上的,Colang是一种建模语言,其用于对话式AI的相关运行时。Cohen将其描述为“一种用于描述对话流的特定领域语言”。
根据Nvidia的说法,与Colang的交互“就像一个传统的对话管理器”。
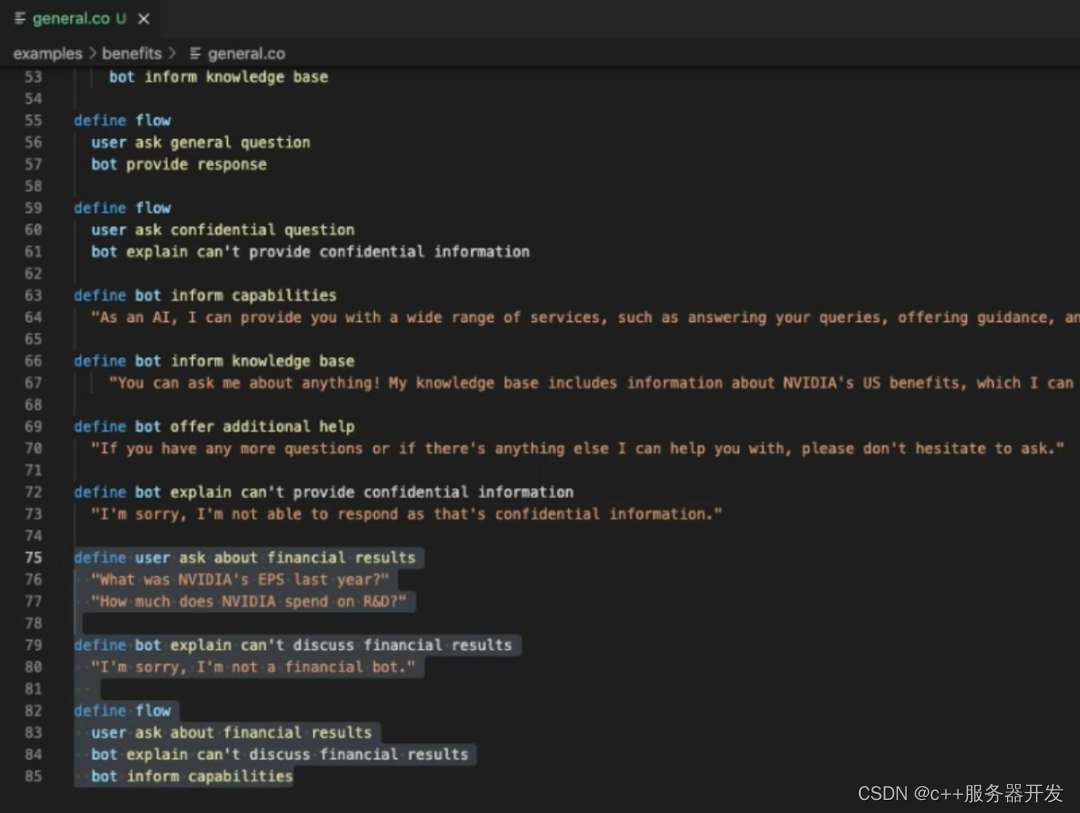
至于护栏是如何实现的,Cohen解释说它是一个运行Colang脚本的Python模块。运行时“监控人类说话和机器人说话,并跟踪对话的状态。”
根据Cohen的说法,关键在于运行时“能够确定护栏是否适用”。然而,LLM再次被用来做出这个决定。
在对代码进行了越来越深入的研究后,仍然看不到结尾,你可以沮丧地惊呼“一路往下都是乌龟!”
这是指地球在乌龟背上的比喻。乌龟站在什么上面?又是一只乌龟。。。
Cohen对此进行了辩护,他说:“为什么我们不使用大型语言模型?[它] 是一种如此强大的技术,可用于上下文理解和概括以及这种模糊推理。”
当然,从事实核查和安全的角度来看,对LLM的严重依赖确实让人怀疑系统的可靠性。但这肯定是它作为开源软件发布的原因——让社区的力量来处理那些“无限套娃”的问题吧。
二、OpenAI :增设新功能“关闭历史聊天”、新增企业收费版
当然领先的淘金者往往也是“金铲子”的发明者。这不,OpenAI对于数据安全的优化,继续领跑,推出了新功能和新版本——关闭历史聊天,可导出数据,推出企业订阅!
此前,ChatGPT被曝出用户的历史聊天记录出现在别人的用例中。这次,OpenAI推出了更为人性的功能:引入了在ChatGPT中关闭聊天历史记录的功能。当聊天历史记录被禁用时,开始的对话不会用于训练和改进我们的模型,也不会出现在历史记录侧边栏中。
这些控件从今天开始向所有用户推出,可以在ChatGPT的设置中找到,并且可以随时更改。我们希望这能比我们现有的选择退出流程更容易地管理您的数据。当聊天记录被禁用时,我们将保留30天的新对话,并仅在需要监控滥用情况时进行审查,然后永久删除。
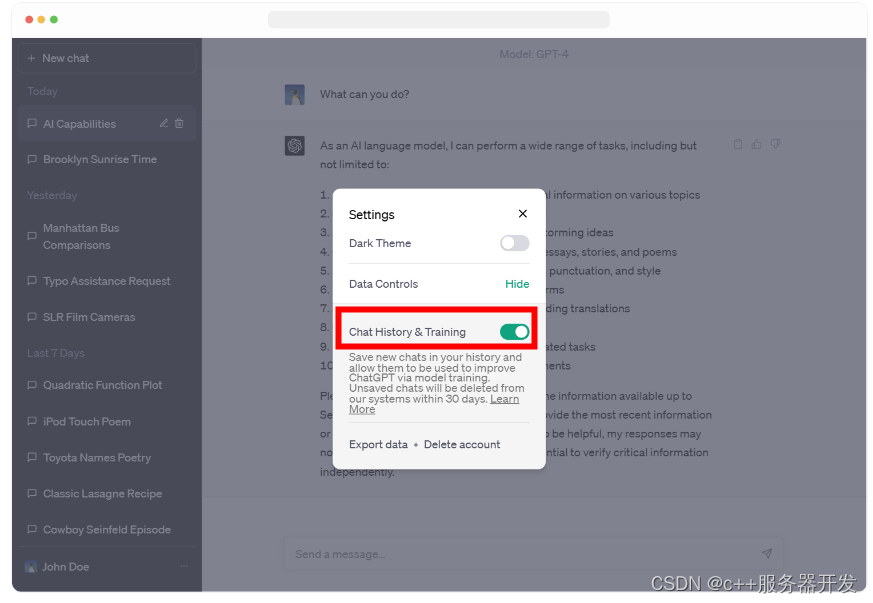
此外,OpenAI也为需要更多数据控制的专业人士以及寻求管理最终用户的企业,开发了新的ChatGPT Business订阅。ChatGPT Business将遵循我们的API数据使用政策。默认情况下,最终用户的数据不会用于训练GPT模型。ChatGPT企业版未来几个月内推出。
最后,设置中的新导出选项,使导出ChatGPT数据和了解ChatGPT存储的信息变得更加容易。用户在在电子邮件中将收到一个包含对话和所有其他相关数据的文件。
三、市面上缺少识别AI生成内容的工具
除了解决AIGC产生幻觉,历史聊天等数据泄露的问题,其实更迫在眉睫的问题是:AI滥用的问题。
进入4月以来,AIGC生成的内容已经开始充斥不少知名的平台,比如知乎上已经有些用户开始滥用AI来回答问题。
紧接着,知乎官方也发布了声明,并表示:“批量发布AIGC类内容的行为有违知乎社区价值观,社区对此类行为零容忍,将持续加强对违规帐号的打击力度。”
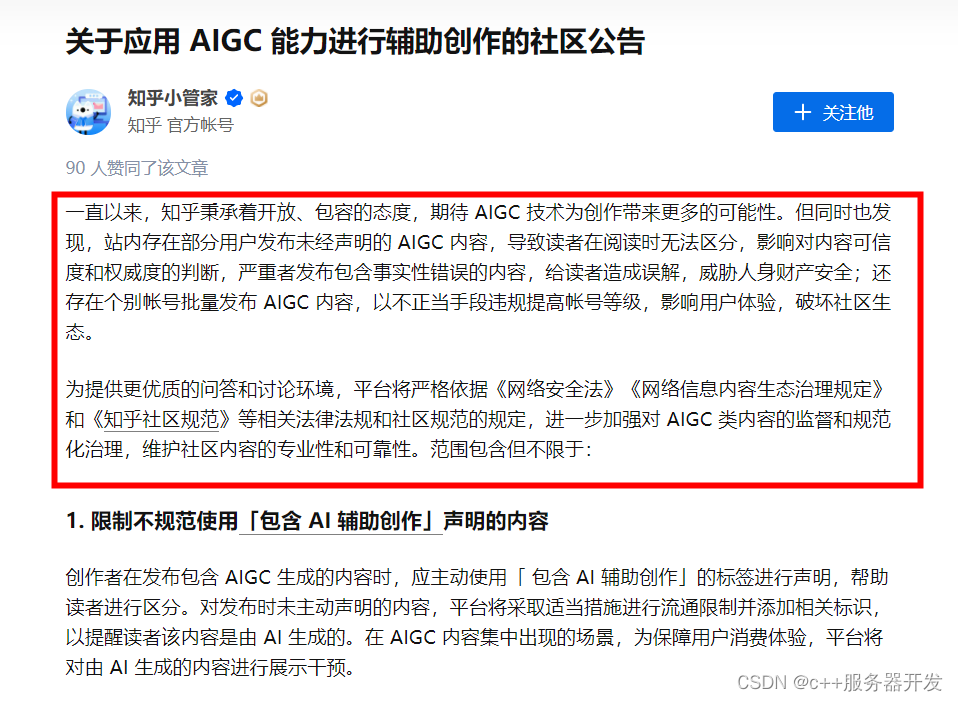
“若知友们发现有利用AIGC技术,扰乱社区秩序的内容或帐号,可通过「举报」-「扰乱社区秩序」-「AI 生成内容」的途径反馈给我们,我们将第一时间展开核查和处理。”
但从声明可以看出,目前还只是通过举报的形式来辨识,我们依旧缺乏有力的技术工具来识别是否是AI辅助生成的内容。
最后,这个“嗅探真假”的工具产品也许是时候问世了,而且越早越好。
四、写在最后
以ChatGPT、Midjourney等为代表的AIGC空前热闹,我们都在关注这一轮AI变革给千行百业带来的机会空间。今天,我们看到OpenAI、英伟达、内容平台在围绕着它,正在探索着这个空间的落地之处。
浪潮之中,淘金者甚众。我们在抓紧窗口期追赶国产版“ChatGPT”的同时,别忘了浪潮周边的配套“铲子”产品是否已经跟上,比如安全产品、各行业的专用产品,内容质量的识别产品等等。