网站优化北京如何联系?学生做网站作品图片
rsync+inotfy实时同步
目录
一、服务器端
二、客户端
一、服务器端
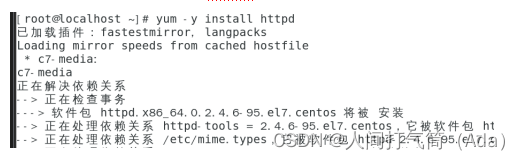
1、安装网站服务,启动,但是不写首页文件
yum -y install httpd
2、安装raync服务
yum -y install rsync

3、修改主配置文件 (/etc/rsyncd.conf)
uid = root
gid = root
[wwwroot]
path = /var/www/html/
comment = backup export area
read only = false
hosts allow = 192.168.50.0/24

二、客户端
1、开发客户端
安装inotify工具
inotify-tools
tar xf inotify-tools-3.14.tar.gz
./configure && make && make install
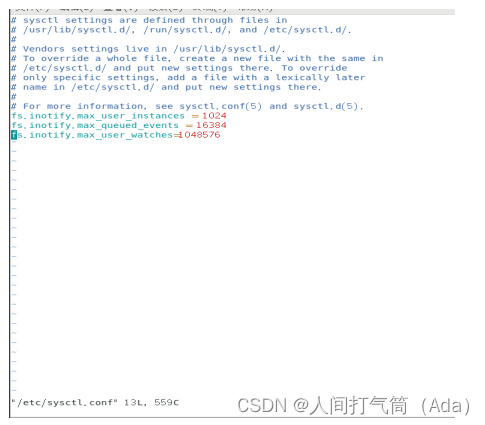
2、配置内核参数
vim /etc/sysctl.conf
fs.inotify.max_user_instances = 1024
fs.inotify.max_queued_events = 16384
fs.inotify.max_user_watches=1048576
sysctl -P
inotifywait -mrq -e modify,create,move,delete /var/www/html
3、编写脚本
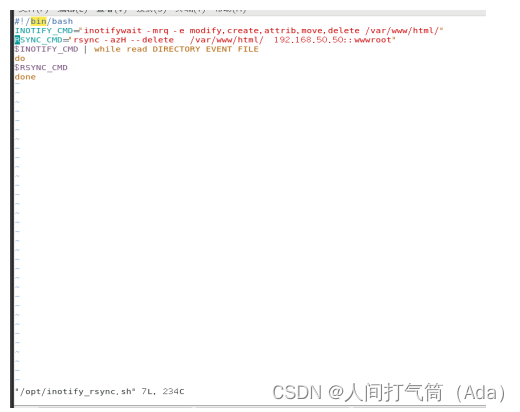
vim /opt/inotify_rsync.sh
#!/bin/bash
INOTIFY_CMD="inotifywait -mrq -e
modify,create,attrib,move,delete /var/www/html"
RSYNC_CMD="rsync-azH--delete /var/www/html
192.168.115.130::wwwroot"
$INOTIFY_CMD | while read DIRECTORY EVENT FILE
do
$RSYNC_CMD
done
4、赋予执行权限
chmod +x inotify_rsync.sh

5、写入文件
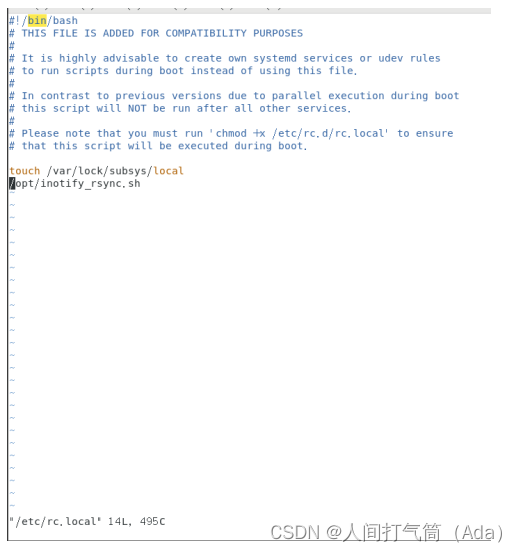
vim /etc/rc.local
/opt/inotify_rsync.sh
6、执行文件
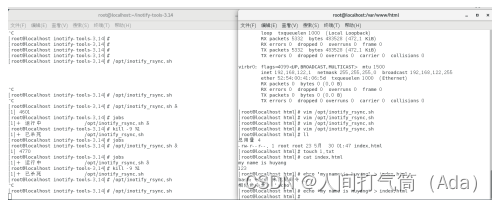
开两个终端
第一个执行/opt/inotify_rsync.sh
第二个cd /var/www/html 新建文件,看第一个终端是否报错,若不报错,则进行下一步
7、修改文件内容
cd /var/www/html
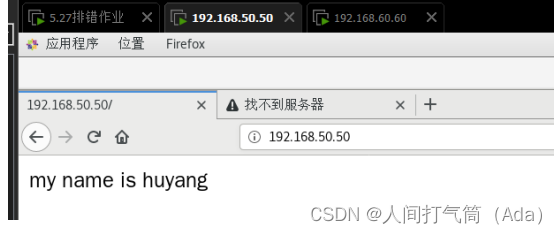
echo "任意内容,便于下步验证” >> index.html
例:

6、修改index.html文件,验证