备案注销网站还有吗网站建立的公司

SpringMVC是一种基于Java的Web框架,它是Spring框架的一部分。SpringMVC通过使用MVC(Model-View-Controller)设计模式来组织和管理Web应用程序的开发。
在SpringMVC中,Model代表数据模型,View代表用户界面,Controller负责处理用户请求并协调Model和View之间的交互。这种分层架构使得代码更加清晰、可维护和可扩展。
一、项目创建
创建一个Maven项目,项目名称为 : CloudJunzySSM
可以根据我的项目结构进行创建包,配置,接口,类(当然也可以根据自己的习惯创建)
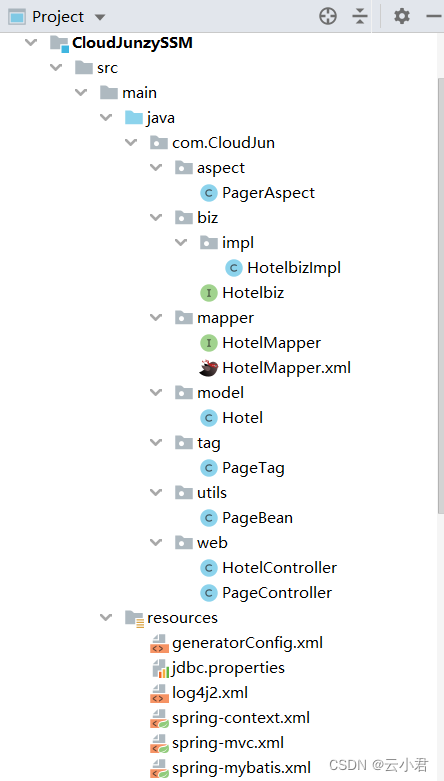
如果不知如何创建,可以关注本人的博客 : IDEA开发工具的安装及使用
二、相关依赖
将所有的引用依赖导入项目中,以下是所有依赖配置
<?xml version="1.0" encoding="UTF-8"?><project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"><modelVersion>4.0.0</modelVersion><groupId>org.example</groupId><artifactId>CloudJunzySSM</artifactId><version>1.0-SNAPSHOT</version><packaging>war</packaging><name>CloudJunzySSM Maven Webapp</name><!-- FIXME change it to the project's website --><url>http://www.example.com</url><properties><project.build.sourceEncoding>UTF-8</project.build.sourceEncoding><maven.compiler.source>1.8</maven.compiler.source><maven.compiler.target>1.8</maven.compiler.target><maven.compiler.plugin.version>3.7.0</maven.compiler.plugin.version><!--添加jar包依赖--><!--1.spring 5.0.2.RELEASE相关--><spring.version>5.0.2.RELEASE</spring.version><!--2.mybatis相关--><mybatis.version>3.4.5</mybatis.version><!--mysql--><mysql.version>5.1.44</mysql.version><!--pagehelper分页jar依赖--><pagehelper.version>5.1.2</pagehelper.version><!--mybatis与spring集成jar依赖--><mybatis.spring.version>1.3.1</mybatis.spring.version><!--3.dbcp2连接池相关 druid--><commons.dbcp2.version>2.1.1</commons.dbcp2.version><commons.pool2.version>2.4.3</commons.pool2.version><!--4.log日志相关--><log4j2.version>2.9.1</log4j2.version><log4j2.disruptor.version>3.2.0</log4j2.disruptor.version><slf4j.version>1.7.13</slf4j.version><!--5.其他--><junit.version>4.12</junit.version><servlet.version>4.0.0</servlet.version><lombok.version>1.18.2</lombok.version><mybatis.ehcache.version>1.1.0</mybatis.ehcache.version><ehcache.version>2.10.0</ehcache.version><redis.version>2.9.0</redis.version><redis.spring.version>1.7.1.RELEASE</redis.spring.version><jackson.version>2.9.3</jackson.version><jstl.version>1.2</jstl.version><standard.version>1.1.2</standard.version><tomcat-jsp-api.version>8.0.47</tomcat-jsp-api.version><commons-fileupload.version>1.3.3</commons-fileupload.version><hibernate-validator.version>5.0.2.Final</hibernate-validator.version><shiro.version>1.3.2</shiro.version></properties><dependencies><!--1.spring相关--><dependency><groupId>org.springframework</groupId><artifactId>spring-core</artifactId><version>${spring.version}</version></dependency><dependency><groupId>org.springframework</groupId><artifactId>spring-beans</artifactId><version>${spring.version}</version></dependency><dependency><groupId>org.springframework</groupId><artifactId>spring-context</artifactId><version>${spring.version}</version></dependency><dependency><groupId>org.springframework</groupId><artifactId>spring-orm</artifactId><version>${spring.version}</version></dependency><dependency><groupId>org.springframework</groupId><artifactId>spring-tx</artifactId><version>${spring.version}</version></dependency><dependency><groupId>org.springframework</groupId><artifactId>spring-aspects</artifactId><version>${spring.version}</version></dependency><dependency><groupId>org.springframework</groupId><artifactId>spring-web</artifactId><version>${spring.version}</version></dependency><dependency><groupId>org.springframework</groupId><artifactId>spring-test</artifactId><version>${spring.version}</version></dependency><!--2.mybatis相关--><dependency><groupId>org.mybatis</groupId><artifactId>mybatis</artifactId><version>${mybatis.version}</version></dependency><!--mysql--><dependency><groupId>mysql</groupId><artifactId>mysql-connector-java</artifactId><version>${mysql.version}</version></dependency><!--pagehelper分页插件jar包依赖--><dependency><groupId>com.github.pagehelper</groupId><artifactId>pagehelper</artifactId><version>${pagehelper.version}</version></dependency><!--mybatis与spring集成jar包依赖--><dependency><groupId>org.mybatis</groupId><artifactId>mybatis-spring</artifactId><version>${mybatis.spring.version}</version></dependency><dependency><groupId>org.springframework</groupId><artifactId>spring-context-support</artifactId><version>${spring.version}</version></dependency><!--mybatis与ehcache整合--><dependency><groupId>org.mybatis.caches</groupId><artifactId>mybatis-ehcache</artifactId><version>${mybatis.ehcache.version}</version></dependency><!--ehcache依赖--><dependency><groupId>net.sf.ehcache</groupId><artifactId>ehcache</artifactId><version>${ehcache.version}</version></dependency><dependency><groupId>redis.clients</groupId><artifactId>jedis</artifactId><version>${redis.version}</version></dependency><dependency><groupId>org.springframework.data</groupId><artifactId>spring-data-redis</artifactId><version>${redis.spring.version}</version></dependency><dependency><groupId>com.fasterxml.jackson.core</groupId><artifactId>jackson-databind</artifactId><version>${jackson.version}</version></dependency><dependency><groupId>com.fasterxml.jackson.core</groupId><artifactId>jackson-core</artifactId><version>${jackson.version}</version></dependency><dependency><groupId>com.fasterxml.jackson.core</groupId><artifactId>jackson-annotations</artifactId><version>${jackson.version}</version></dependency><!--3.dbcp2连接池相关--><dependency><groupId>org.apache.commons</groupId><artifactId>commons-dbcp2</artifactId><version>${commons.dbcp2.version}</version><exclusions><exclusion><artifactId>commons-pool2</artifactId><groupId>org.apache.commons</groupId></exclusion></exclusions></dependency><dependency><groupId>org.apache.commons</groupId><artifactId>commons-pool2</artifactId><version>${commons.pool2.version}</version></dependency><!--springmvc依赖--><dependency><groupId>org.springframework</groupId><artifactId>spring-webmvc</artifactId><version>${spring.version}</version></dependency><!--4.log日志相关依赖--><!-- log4j2日志相关依赖 --><!-- log配置:Log4j2 + Slf4j --><!-- slf4j核心包--><dependency><groupId>org.slf4j</groupId><artifactId>slf4j-api</artifactId><version>${slf4j.version}</version></dependency><dependency><groupId>org.slf4j</groupId><artifactId>jcl-over-slf4j</artifactId><version>${slf4j.version}</version><scope>runtime</scope></dependency><!--核心log4j2jar包--><dependency><groupId>org.apache.logging.log4j</groupId><artifactId>log4j-api</artifactId><version>${log4j2.version}</version></dependency><dependency><groupId>org.apache.logging.log4j</groupId><artifactId>log4j-core</artifactId><version>${log4j2.version}</version></dependency><!--用于与slf4j保持桥接--><dependency><groupId>org.apache.logging.log4j</groupId><artifactId>log4j-slf4j-impl</artifactId><version>${log4j2.version}</version></dependency><!--web工程需要包含log4j-web,非web工程不需要--><dependency><groupId>org.apache.logging.log4j</groupId><artifactId>log4j-web</artifactId><version>${log4j2.version}</version><scope>runtime</scope></dependency><!--需要使用log4j2的AsyncLogger需要包含disruptor--><dependency><groupId>com.lmax</groupId><artifactId>disruptor</artifactId><version>${log4j2.disruptor.version}</version></dependency><!--5.其他--><dependency><groupId>junit</groupId><artifactId>junit</artifactId><version>${junit.version}</version><scope>test</scope></dependency><dependency><groupId>javax.servlet</groupId><artifactId>javax.servlet-api</artifactId><version>${servlet.version}</version><scope>provided</scope></dependency><dependency><groupId>org.projectlombok</groupId><artifactId>lombok</artifactId><version>${lombok.version}</version><scope>provided</scope></dependency><dependency><groupId>jstl</groupId><artifactId>jstl</artifactId><version>${jstl.version}</version></dependency><dependency><groupId>taglibs</groupId><artifactId>standard</artifactId><version>${standard.version}</version></dependency><dependency><groupId>org.apache.tomcat</groupId><artifactId>tomcat-jsp-api</artifactId><version>${tomcat-jsp-api.version}</version></dependency><dependency><groupId>commons-fileupload</groupId><artifactId>commons-fileupload</artifactId><version>${commons-fileupload.version}</version></dependency><dependency><groupId>org.hibernate</groupId><artifactId>hibernate-validator</artifactId><version>${hibernate-validator.version}</version></dependency><!--shiro依赖--><dependency><groupId>org.apache.shiro</groupId><artifactId>shiro-core</artifactId><version>${shiro.version}</version></dependency><dependency><groupId>org.apache.shiro</groupId><artifactId>shiro-web</artifactId><version>${shiro.version}</version></dependency><dependency><groupId>org.apache.shiro</groupId><artifactId>shiro-spring</artifactId><version>${shiro.version}</version></dependency></dependencies><build><finalName>CloudJunzySSM</finalName><resources><!--解决mybatis-generator-maven-plugin运行时没有将XxxMapper.xml文件放入target文件夹的问题--><resource><directory>src/main/java</directory><includes><include>**/*.xml</include></includes></resource><!--解决mybatis-generator-maven-plugin运行时没有将jdbc.properites文件放入target文件夹的问题--><resource><directory>src/main/resources</directory><includes><include>*.properties</include><include>*.xml</include></includes></resource></resources><plugins><plugin><groupId>org.apache.maven.plugins</groupId><artifactId>maven-compiler-plugin</artifactId><version>${maven.compiler.plugin.version}</version><configuration><source>${maven.compiler.source}</source><target>${maven.compiler.target}</target><encoding>${project.build.sourceEncoding}</encoding></configuration></plugin><plugin><groupId>org.mybatis.generator</groupId><artifactId>mybatis-generator-maven-plugin</artifactId><version>1.3.2</version><dependencies><!--使用Mybatis-generator插件不能使用太高版本的mysql驱动 --><dependency><groupId>mysql</groupId><artifactId>mysql-connector-java</artifactId><version>${mysql.version}</version></dependency></dependencies><configuration><overwrite>true</overwrite></configuration></plugin><plugin><artifactId>maven-clean-plugin</artifactId><version>3.1.0</version></plugin><!-- see http://maven.apache.org/ref/current/maven-core/default-bindings.html#Plugin_bindings_for_war_packaging --><plugin><artifactId>maven-resources-plugin</artifactId><version>3.0.2</version></plugin><plugin><artifactId>maven-compiler-plugin</artifactId><version>3.8.0</version></plugin><plugin><artifactId>maven-surefire-plugin</artifactId><version>2.22.1</version></plugin><plugin><artifactId>maven-war-plugin</artifactId><version>3.2.2</version></plugin><plugin><artifactId>maven-install-plugin</artifactId><version>2.5.2</version></plugin><plugin><artifactId>maven-deploy-plugin</artifactId><version>2.8.2</version></plugin></plugins></build>
</project>
其中的项目名称需要根据自己的项目名称进行修改
三、配置文件
将项目中的web.xml配置文件修改为3.1并且增加配置
<?xml version="1.0" encoding="UTF-8"?> <web-app xmlns="http://xmlns.jcp.org/xml/ns/javaee"xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation="http://xmlns.jcp.org/xml/ns/javaee http://xmlns.jcp.org/xml/ns/javaee/web-app_3_1.xsd"version="3.1"><display-name>Archetype Created Web Application</display-name><!-- Spring和web项目集成start --><!-- spring上下文配置文件 --><context-param><param-name>contextConfigLocation</param-name><param-value>classpath:spring-context.xml</param-value></context-param><!-- 读取Spring上下文的监听器 --><listener><listener-class>org.springframework.web.context.ContextLoaderListener</listener-class></listener><!-- Spring和web项目集成end --><!-- 中文乱码处理 --><filter><filter-name>encodingFilter</filter-name><filter-class>org.springframework.web.filter.CharacterEncodingFilter</filter-class><async-supported>true</async-supported><init-param><param-name>encoding</param-name><param-value>UTF-8</param-value></init-param></filter><filter-mapping><filter-name>encodingFilter</filter-name><url-pattern>/*</url-pattern></filter-mapping><!-- Spring MVC servlet --><servlet><servlet-name>SpringMVC</servlet-name><servlet-class>org.springframework.web.servlet.DispatcherServlet</servlet-class><!--此参数可以不配置,默认值为:/WEB-INF/springmvc-servlet.xml--><init-param><param-name>contextConfigLocation</param-name><param-value>classpath:spring-mvc.xml</param-value></init-param><load-on-startup>1</load-on-startup><!--web.xml 3.0的新特性,是否支持异步--><async-supported>true</async-supported></servlet><servlet-mapping><servlet-name>SpringMVC</servlet-name><url-pattern>/</url-pattern></servlet-mapping> </web-app>
以上代码会有部分报出编译错误,无需担心,只要把以下所有配置文件配置完成即可
3.1 generatorConfig.xml
<?xml version="1.0" encoding="UTF-8" ?> <!DOCTYPE generatorConfiguration PUBLIC "-//mybatis.org//DTD MyBatis Generator Configuration 1.0//EN""http://mybatis.org/dtd/mybatis-generator-config_1_0.dtd" > <generatorConfiguration><!-- 引入配置文件 --><properties resource="jdbc.properties"/><!--指定数据库jdbc驱动jar包的位置--><classPathEntry location="D:\\temp\\mvn_repository\\mysql\\mysql-connector-java\\5.1.44\\mysql-connector-java-5.1.44.jar"/><!-- 一个数据库一个context --><context id="infoGuardian"><!-- 注释 --><commentGenerator><property name="suppressAllComments" value="true"/><!-- 是否取消注释 --><property name="suppressDate" value="true"/> <!-- 是否生成注释代时间戳 --></commentGenerator><!-- jdbc连接 --><jdbcConnection driverClass="${jdbc.driver}"connectionURL="${jdbc.url}" userId="${jdbc.username}" password="${jdbc.password}"/><!-- 类型转换 --><javaTypeResolver><!-- 是否使用bigDecimal, false可自动转化以下类型(Long, Integer, Short, etc.) --><property name="forceBigDecimals" value="false"/></javaTypeResolver><!-- 01 指定javaBean生成的位置 --><!-- targetPackage:指定生成的model生成所在的包名 --><!-- targetProject:指定在该项目下所在的路径 --><javaModelGenerator targetPackage="com.CloudJun.model"targetProject="src/main/java"><!-- 是否允许子包,即targetPackage.schemaName.tableName --><property name="enableSubPackages" value="false"/><!-- 是否对model添加构造函数 --><property name="constructorBased" value="true"/><!-- 是否针对string类型的字段在set的时候进行trim调用 --><property name="trimStrings" value="false"/><!-- 建立的Model对象是否 不可改变 即生成的Model对象不会有 setter方法,只有构造方法 --><property name="immutable" value="false"/></javaModelGenerator><!-- 02 指定sql映射文件生成的位置 --><sqlMapGenerator targetPackage="com.CloudJun.mapper"targetProject="src/main/java"><!-- 是否允许子包,即targetPackage.schemaName.tableName --><property name="enableSubPackages" value="false"/></sqlMapGenerator><!-- 03 生成XxxMapper接口 --><!-- type="ANNOTATEDMAPPER",生成Java Model 和基于注解的Mapper对象 --><!-- type="MIXEDMAPPER",生成基于注解的Java Model 和相应的Mapper对象 --><!-- type="XMLMAPPER",生成SQLMap XML文件和独立的Mapper接口 --><javaClientGenerator targetPackage="com.CloudJun.mapper"targetProject="src/main/java" type="XMLMAPPER"><!-- 是否在当前路径下新加一层schema,false路径com.oop.eksp.user.model, true:com.oop.eksp.user.model.[schemaName] --><property name="enableSubPackages" value="false"/></javaClientGenerator><!-- 配置表信息 --><!-- schema即为数据库名 --><!-- tableName为对应的数据库表 --><!-- domainObjectName是要生成的实体类 --><!-- enable*ByExample是否生成 example类 --><!--<table schema="" tableName="t_book" domainObjectName="Book"--><!--enableCountByExample="false" enableDeleteByExample="false"--><!--enableSelectByExample="false" enableUpdateByExample="false">--><!--<!– 忽略列,不生成bean 字段 –>--><!--<!– <ignoreColumn column="FRED" /> –>--><!--<!– 指定列的java数据类型 –>--><!--<!– <columnOverride column="LONG_VARCHAR_FIELD" jdbcType="VARCHAR" /> –>--><!--</table>--><table schema="" tableName="t_hotel" domainObjectName="Hotel"enableCountByExample="false" enableDeleteByExample="false"enableSelectByExample="false" enableUpdateByExample="false"></table></context> </generatorConfiguration>
其中
<table schema="" tableName="t_hotel" domainObjectName="Hotel"
enableCountByExample="false" enableDeleteByExample="false"
enableSelectByExample="false" enableUpdateByExample="false">
</table>tableName="t_hotel"中的t_hotel是数据库的表名称,
domainObjectName="Hotel"中的Hotel是需要自动生成的实体名称。
3.2 jdbc.properties
jdbc.driver=com.mysql.jdbc.Driver jdbc.url=jdbc:mysql://localhost:3306/mybatis_ssm?useUnicode=true&characterEncoding=UTF-8 jdbc.username=root jdbc.password=123456
3.3 log4j2.xml
<?xml version="1.0" encoding="UTF-8"?><!-- status : 指定log4j本身的打印日志的级别.ALL< Trace < DEBUG < INFO < WARN < ERROR < FATAL < OFF。 monitorInterval : 用于指定log4j自动重新配置的监测间隔时间,单位是s,最小是5s. --> <Configuration status="WARN" monitorInterval="30"><Properties><!-- 配置日志文件输出目录 ${sys:user.home} --><Property name="LOG_HOME">/root/workspace/lucenedemo/logs</Property><property name="ERROR_LOG_FILE_NAME">/root/workspace/lucenedemo/logs/error</property><property name="WARN_LOG_FILE_NAME">/root/workspace/lucenedemo/logs/warn</property><property name="PATTERN">%d{yyyy-MM-dd HH:mm:ss.SSS} [%t-%L] %-5level %logger{36} - %msg%n</property></Properties><Appenders><!--这个输出控制台的配置 --><Console name="Console" target="SYSTEM_OUT"><!-- 控制台只输出level及以上级别的信息(onMatch),其他的直接拒绝(onMismatch) --><ThresholdFilter level="trace" onMatch="ACCEPT"onMismatch="DENY" /><!-- 输出日志的格式 --><!-- %d{yyyy-MM-dd HH:mm:ss, SSS} : 日志生产时间 %p : 日志输出格式 %c : logger的名称 %m : 日志内容,即 logger.info("message") %n : 换行符 %C : Java类名 %L : 日志输出所在行数 %M : 日志输出所在方法名 hostName : 本地机器名 hostAddress : 本地ip地址 --><PatternLayout pattern="${PATTERN}" /></Console><!--文件会打印出所有信息,这个log每次运行程序会自动清空,由append属性决定,这个也挺有用的,适合临时测试用 --><!--append为TRUE表示消息增加到指定文件中,false表示消息覆盖指定的文件内容,默认值是true --><File name="log" fileName="logs/test.log" append="false"><PatternLayoutpattern="%d{yyyy-MM-dd HH:mm:ss.SSS} [%t] %-5level %logger{36} - %msg%n" /></File><!-- 这个会打印出所有的info及以下级别的信息,每次大小超过size, 则这size大小的日志会自动存入按年份-月份建立的文件夹下面并进行压缩,作为存档 --><RollingFile name="RollingFileInfo" fileName="${LOG_HOME}/info.log"filePattern="${LOG_HOME}/$${date:yyyy-MM}/info-%d{yyyy-MM-dd}-%i.log"><!--控制台只输出level及以上级别的信息(onMatch),其他的直接拒绝(onMismatch) --><ThresholdFilter level="info" onMatch="ACCEPT"onMismatch="DENY" /><PatternLayoutpattern="%d{yyyy-MM-dd HH:mm:ss.SSS} [%t] %-5level %logger{36} - %msg%n" /><Policies><!-- 基于时间的滚动策略,interval属性用来指定多久滚动一次,默认是1 hour。 modulate=true用来调整时间:比如现在是早上3am,interval是4,那么第一次滚动是在4am,接着是8am,12am...而不是7am. --><!-- 关键点在于 filePattern后的日期格式,以及TimeBasedTriggeringPolicy的interval, 日期格式精确到哪一位,interval也精确到哪一个单位 --><!-- log4j2的按天分日志文件 : info-%d{yyyy-MM-dd}-%i.log --><TimeBasedTriggeringPolicy interval="1"modulate="true" /><!-- SizeBasedTriggeringPolicy:Policies子节点, 基于指定文件大小的滚动策略,size属性用来定义每个日志文件的大小. --><!-- <SizeBasedTriggeringPolicy size="2 kB" /> --></Policies></RollingFile><RollingFile name="RollingFileWarn" fileName="${WARN_LOG_FILE_NAME}/warn.log"filePattern="${WARN_LOG_FILE_NAME}/$${date:yyyy-MM}/warn-%d{yyyy-MM-dd}-%i.log"><ThresholdFilter level="warn" onMatch="ACCEPT"onMismatch="DENY" /><PatternLayoutpattern="%d{yyyy-MM-dd HH:mm:ss.SSS} [%t] %-5level %logger{36} - %msg%n" /><Policies><TimeBasedTriggeringPolicy /><SizeBasedTriggeringPolicy size="2 kB" /></Policies><!-- DefaultRolloverStrategy属性如不设置,则默认为最多同一文件夹下7个文件,这里设置了20 --><DefaultRolloverStrategy max="20" /></RollingFile><RollingFile name="RollingFileError" fileName="${ERROR_LOG_FILE_NAME}/error.log"filePattern="${ERROR_LOG_FILE_NAME}/$${date:yyyy-MM}/error-%d{yyyy-MM-dd-HH-mm}-%i.log"><ThresholdFilter level="error" onMatch="ACCEPT"onMismatch="DENY" /><PatternLayoutpattern="%d{yyyy-MM-dd HH:mm:ss.SSS} [%t] %-5level %logger{36} - %msg%n" /><Policies><!-- log4j2的按分钟 分日志文件 : warn-%d{yyyy-MM-dd-HH-mm}-%i.log --><TimeBasedTriggeringPolicy interval="1"modulate="true" /><!-- <SizeBasedTriggeringPolicy size="10 MB" /> --></Policies></RollingFile></Appenders><!--然后定义logger,只有定义了logger并引入的appender,appender才会生效 --><Loggers><!--过滤掉spring和mybatis的一些无用的DEBUG信息 --><logger name="org.springframework" level="INFO"></logger><logger name="org.mybatis" level="INFO"></logger><!-- 第三方日志系统 --><logger name="org.springframework" level="ERROR" /><logger name="org.hibernate" level="ERROR" /><logger name="org.apache.struts2" level="ERROR" /><logger name="com.opensymphony.xwork2" level="ERROR" /><logger name="org.jboss" level="ERROR" /><!-- 配置日志的根节点 --><root level="all"><appender-ref ref="Console" /><appender-ref ref="RollingFileInfo" /><appender-ref ref="RollingFileWarn" /><appender-ref ref="RollingFileError" /></root></Loggers></Configuration>
3.4 spring-context.xml
<?xml version="1.0" encoding="UTF-8"?> <beans xmlns="http://www.springframework.org/schema/beans"xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans.xsd"><!-- spring框架和mybatis进行整合的配置文件加载到spring的上下文中--> <import resource="classpath:spring-mybatis.xml"></import></beans>
3.5 spring-mybatis.xml
<?xml version="1.0" encoding="UTF-8"?> <beans xmlns="http://www.springframework.org/schema/beans"xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"xmlns:context="http://www.springframework.org/schema/context" xmlns:tx="http://www.springframework.org/schema/tx"xmlns:aop="http://www.springframework.org/schema/aop"xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans.xsd http://www.springframework.org/schema/context http://www.springframework.org/schema/context/spring-context.xsd http://www.springframework.org/schema/tx http://www.springframework.org/schema/tx/spring-tx.xsd http://www.springframework.org/schema/aop http://www.springframework.org/schema/aop/spring-aop.xsd"><!--1. 注解式开发 --><!-- 注解驱动 --><context:annotation-config/><!-- 用注解方式注入bean,并指定查找范围:com.CloudJun及子子孙孙包--><context:component-scan base-package="com.CloudJun"/><context:property-placeholder location="classpath:jdbc.properties"/><bean id="dataSource" class="org.apache.commons.dbcp2.BasicDataSource"destroy-method="close"><property name="driverClassName" value="${jdbc.driver}"/><property name="url" value="${jdbc.url}"/><property name="username" value="${jdbc.username}"/><property name="password" value="${jdbc.password}"/><!--初始连接数--><property name="initialSize" value="10"/><!--最大活动连接数--><property name="maxTotal" value="100"/><!--最大空闲连接数--><property name="maxIdle" value="50"/><!--最小空闲连接数--><property name="minIdle" value="10"/><!--设置为-1时,如果没有可用连接,连接池会一直无限期等待,直到获取到连接为止。--><!--如果设置为N(毫秒),则连接池会等待N毫秒,等待不到,则抛出异常--><property name="maxWaitMillis" value="-1"/></bean><!--4. spring和MyBatis整合 --><!--1) 创建sqlSessionFactory--><bean id="sqlSessionFactory" class="org.mybatis.spring.SqlSessionFactoryBean"><!-- 指定数据源 --><property name="dataSource" ref="dataSource"/><!-- 自动扫描XxxMapping.xml文件,**是任意路径 --><property name="mapperLocations" value="classpath*:com/CloudJun/**/mapper/*.xml"/><!-- 指定别名 --><property name="typeAliasesPackage" value="com/CloudJun/**/model"/><!--配置pagehelper插件--><property name="plugins"><array><bean class="com.github.pagehelper.PageInterceptor"><property name="properties"><value>helperDialect=mysql</value></property></bean></array></property></bean><!--2) 自动扫描com/CloudJun/**/mapper下的所有XxxMapper接口(其实就是DAO接口),并实现这些接口,--><!-- 即可直接在程序中使用dao接口,不用再获取sqlsession对象--><bean class="org.mybatis.spring.mapper.MapperScannerConfigurer"><!--basePackage 属性是映射器接口文件的包路径。--><!--你可以使用分号或逗号 作为分隔符设置多于一个的包路径--><property name="basePackage" value="com/CloudJun/**/mapper"/><property name="sqlSessionFactoryBeanName" value="sqlSessionFactory"/></bean><bean id="transactionManager" class="org.springframework.jdbc.datasource.DataSourceTransactionManager"><property name="dataSource" ref="dataSource" /></bean><tx:annotation-driven transaction-manager="transactionManager" /><aop:aspectj-autoproxy/> </beans>
3.6 spring-mvc.xml
<?xml version="1.0" encoding="UTF-8"?> <beans xmlns="http://www.springframework.org/schema/beans"xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"xmlns:context="http://www.springframework.org/schema/context"xmlns:mvc="http://www.springframework.org/schema/mvc" xmlns:aop="http://www.springframework.org/schema/aop"xsi:schemaLocation="http://www.springframework.org/schema/beanshttp://www.springframework.org/schema/beans/spring-beans.xsdhttp://www.springframework.org/schema/contexthttp://www.springframework.org/schema/context/spring-context-4.3.xsdhttp://www.springframework.org/schema/mvchttp://www.springframework.org/schema/mvc/spring-mvc.xsdhttp://www.springframework.org/schema/aophttp://www.springframework.org/schema/aop/spring-aop-4.3.xsd"><!--1) 扫描com.CloudJun及子子孙孙包下的控制器(扫描范围过大,耗时)--><context:component-scan base-package="com.CloudJun"/><!--2) 此标签默认注册DefaultAnnotationHandlerMapping和AnnotationMethodHandlerAdapter --><mvc:annotation-driven /><!--3) 创建ViewResolver视图解析器 --><bean class="org.springframework.web.servlet.view.InternalResourceViewResolver"><!-- viewClass需要在pom中引入两个包:standard.jar and jstl.jar --><property name="viewClass"value="org.springframework.web.servlet.view.JstlView"></property><property name="prefix" value="/WEB-INF/jsp/"/><property name="suffix" value=".jsp"/></bean><!--4) 单独处理图片、样式、js等资源 --><!-- <mvc:resources location="/css/" mapping="/css/**"/><mvc:resources location="/js/" mapping="/js/**"/><mvc:resources location="WEB-INF/images/" mapping="/images/**"/>--><!-- 处理static包里的所有静态资源 --><mvc:resources location="/static/" mapping="/static/**"/><!--处理controller层发送请求到biz层,会经过切面拦截处理--><aop:aspectj-autoproxy/> </beans>
其中有些会报编译错误,需要将后端代码完成即可
创建名为CloudJun.tld (自定义分页并且配置)的配置文件
<?xml version="1.0" encoding="UTF-8" ?><taglib xmlns="http://java.sun.com/xml/ns/j2ee"xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation="http://java.sun.com/xml/ns/j2ee http://java.sun.com/xml/ns/j2ee/web-jsptaglibrary_2_0.xsd"version="2.0"><description>CloudJun 1.1 core library</description><display-name>CloudJun core</display-name><tlib-version>1.1</tlib-version><short-name>CloudJun</short-name><uri>http://jsp.veryedu.cn</uri><tag><name>page</name><tag-class>com.CloudJun.tag.PageTag</tag-class><body-content>JSP</body-content><attribute><name>pageBean</name><required>true</required><rtexprvalue>true</rtexprvalue></attribute></tag></taglib>
四、后端代码
配置完成,在右侧的maven中找到相应的配置文件进行自动生成接口及实体和配置文件
不知道的可以根据我博客中的进行学习 : mybatis入门的环境搭建
PagerAspect 创建切面类
package com.CloudJun.aspect;import com.CloudJun.utils.PageBean; import com.github.pagehelper.PageHelper; import com.github.pagehelper.PageInfo; import org.aspectj.lang.ProceedingJoinPoint; import org.aspectj.lang.annotation.Around; import org.aspectj.lang.annotation.Aspect; import org.springframework.stereotype.Component;import java.util.List;/*** @author CloudJun* @create 2023-08-25 16:26*/ @Component @Aspect public class PagerAspect {/** * *..*Service.*Pager(..)* * : 任何返回值* *.. : 任何包,不限层级* *biz : 以Biz结尾的类或者接口* *Pager : 以Pager结尾的方法* (..) : 方法里有任意参数* 符合上述条件,即为目标类或者方法*/@Around("execution(* *..*biz.*Page(..))")public Object invoke(ProceedingJoinPoint args) throws Throwable {Object[] params = args.getArgs();PageBean pageBean = null;for (Object param : params) {if(param instanceof PageBean){pageBean = (PageBean)param;break;}}if(pageBean != null && pageBean.isPagination())PageHelper.startPage(pageBean.getPage(),pageBean.getRows());Object list = args.proceed(params);if(null != pageBean && pageBean.isPagination()){PageInfo pageInfo = new PageInfo((List) list);pageBean.setTotal(pageInfo.getTotal()+"");}return list;}}
在自动生成的配置文件 HotelMapper.xml 中增加以下代码
<select id="selectHotelPage" resultType="com.CloudJun.model.Hotel" parameterType="com.CloudJun.model.Hotel" >select * from t_hotel<where><if test="hname != null">and hname like concat('%',#{hname},'%')</if></where></select>在自动生成的接口 HotelMapper 中增加以下代码
List<Hotel> selectHotelPage(Hotel hotel);
在自动生成的实体类中重写ToString方法
在创建一个接口 Hotelbiz
package com.CloudJun.biz;import com.CloudJun.model.Hotel;
import com.CloudJun.utils.PageBean;import java.util.List;public interface Hotelbiz {int deleteByPrimaryKey(Long hid);int insert(Hotel record);int insertSelective(Hotel record);Hotel selectByPrimaryKey(Long hid);int updateByPrimaryKeySelective(Hotel record);int updateByPrimaryKey(Hotel record);List<Hotel> selectHotelPage(Hotel clazz, PageBean pageBean);}自己在项目中共创建一个接口实现类 HotelbizImpl
package com.CloudJun.biz.impl;import com.CloudJun.biz.Hotelbiz;
import com.CloudJun.mapper.HotelMapper;
import com.CloudJun.model.Hotel;
import com.CloudJun.utils.PageBean;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Service;import java.util.List;/*** @author CloudJun* @create 2023-09-07 14:22*/
@Service
public class HotelbizImpl implements Hotelbiz {@Autowiredprivate HotelMapper hotelMapper;@Overridepublic int deleteByPrimaryKey(Long hid) {return hotelMapper.deleteByPrimaryKey(hid);}@Overridepublic int insert(Hotel record) {return hotelMapper.insert(record);}@Overridepublic int insertSelective(Hotel record) {return hotelMapper.insert(record);}@Overridepublic Hotel selectByPrimaryKey(Long hid) {return hotelMapper.selectByPrimaryKey(hid);}@Overridepublic int updateByPrimaryKeySelective(Hotel record) {return hotelMapper.updateByPrimaryKeySelective(record);}@Overridepublic int updateByPrimaryKey(Hotel record) {return hotelMapper.updateByPrimaryKey(record);}@Overridepublic List<Hotel> selectHotelPage(Hotel hotel, PageBean pageBean) {return hotelMapper.selectHotelPage(hotel);}}
PageBean创建一个分页工具类
package com.CloudJun.utils;import javax.servlet.http.HttpServletRequest; import java.io.Serializable; import java.util.Map;public class PageBean implements Serializable {private static final long serialVersionUID = 2422581023658455731L;//页码private int page=1;//每页显示记录数private int rows=10;//总记录数private int total=0;//是否分页private boolean isPagination=true;//上一次的请求路径private String url;//获取所有的请求参数private Map<String,String[]> map;public PageBean() {super();}//设置请求参数public void setRequest(HttpServletRequest req) {String page=req.getParameter("page");String rows=req.getParameter("rows");String pagination=req.getParameter("pagination");this.setPage(page);this.setRows(rows);this.setPagination(pagination);this.url=req.getContextPath()+req.getServletPath();this.map=req.getParameterMap();}public String getUrl() {return url;}public void setUrl(String url) {this.url = url;}public Map<String, String[]> getMap() {return map;}public void setMap(Map<String, String[]> map) {this.map = map;}public int getPage() {return page;}public void setPage(int page) {this.page = page;}public void setPage(String page) {if(null!=page&&!"".equals(page.trim()))this.page = Integer.parseInt(page);}public int getRows() {return rows;}public void setRows(int rows) {this.rows = rows;}public void setRows(String rows) {if(null!=rows&&!"".equals(rows.trim()))this.rows = Integer.parseInt(rows);}public int getTotal() {return total;}public void setTotal(int total) {this.total = total;}public void setTotal(String total) {this.total = Integer.parseInt(total);}public boolean isPagination() {return isPagination;}public void setPagination(boolean isPagination) {this.isPagination = isPagination;}public void setPagination(String isPagination) {if(null!=isPagination&&!"".equals(isPagination.trim()))this.isPagination = Boolean.parseBoolean(isPagination);}/*** 获取分页起始标记位置* @return*/public int getStartIndex() {//(当前页码-1)*显示记录数return (this.getPage()-1)*this.rows;}/*** 末页* @return*/public int getMaxPage() {int totalpage=this.total/this.rows;if(this.total%this.rows!=0)totalpage++;return totalpage;}/*** 下一页* @return*/public int getNextPage() {int nextPage=this.page+1;if(this.page>=this.getMaxPage())nextPage=this.getMaxPage();return nextPage;}/*** 上一页* @return*/public int getPreivousPage() {int previousPage=this.page-1;if(previousPage<1)previousPage=1;return previousPage;}@Overridepublic String toString() {return "PageBean [page=" + page + ", rows=" + rows + ", total=" + total + ", isPagination=" + isPagination+ "]";} }
创建一个分页标签工具类 PageTag
package com.CloudJun.tag;import com.CloudJun.utils.PageBean;import java.io.IOException; import java.util.Map; import java.util.Map.Entry; import java.util.Set;import javax.servlet.jsp.JspException; import javax.servlet.jsp.JspWriter; import javax.servlet.jsp.tagext.BodyTagSupport;public class PageTag extends BodyTagSupport{private PageBean pageBean;// 包含了所有分页相关的元素public PageBean getPageBean() {return pageBean;}public void setPageBean(PageBean pageBean) {this.pageBean = pageBean;}@Overridepublic int doStartTag() throws JspException { // 没有标签体,要输出内容JspWriter out = pageContext.getOut();try {out.print(toHTML());} catch (IOException e) {e.printStackTrace();}return super.doStartTag();}private String toHTML() {StringBuffer sb = new StringBuffer(); // 隐藏的form表单---这个就是上一次请求下次重新发的奥义所在 // 上一次请求的URLsb.append("<form action='"+pageBean.getUrl()+"' id='pageBeanForm' method='post'>");sb.append(" <input type='hidden' name='page'>"); // 上一次请求的参数Map<String, String[]> paramMap = pageBean.getMap();if(paramMap != null && paramMap.size() > 0) {Set<Entry<String, String[]>> entrySet = paramMap.entrySet();for (Entry<String, String[]> entry : entrySet) { // 参数名String key = entry.getKey(); // 参数值for (String value : entry.getValue()) { // 上一次请求的参数,再一次组装成了新的Form表单 // 注意:page参数每次都会提交,我们需要避免if(!"page".equals(key)) {sb.append(" <input type='hidden' name='"+key+"' value='"+value+"' >");}}}}sb.append("</form>");// 分页条sb.append("<ul class='pagination justify-content-center'>");sb.append(" <li class='page-item "+(pageBean.getPage() == 1 ? "disabled" : "")+"'><a class='page-link'");sb.append(" href='javascript:gotoPage(1)'>首页</a></li>");sb.append(" <li class='page-item "+(pageBean.getPage() == 1 ? "disabled" : "")+"'><a class='page-link'");sb.append(" href='javascript:gotoPage("+pageBean.getPreivousPage()+")'><</a></li>");// less than 小于号 // sb.append(" <li class='page-item'><a class='page-link' href='#'>1</a></li>"); // sb.append(" <li class='page-item'><a class='page-link' href='#'>2</a></li>");sb.append(" <li class='page-item active'><a class='page-link' href='#'>"+pageBean.getPage()+"</a></li>");sb.append(" <li class='page-item "+(pageBean.getPage() == pageBean.getMaxPage() ? "disabled" : "")+"'><a class='page-link' href='javascript:gotoPage("+pageBean.getNextPage()+")'>></a></li>");sb.append(" <li class='page-item "+(pageBean.getPage() == pageBean.getMaxPage() ? "disabled" : "")+"'><a class='page-link' href='javascript:gotoPage("+pageBean.getMaxPage()+")'>尾页</a></li>");sb.append(" <li class='page-item go-input'><b>到第</b><input class='page-link'");sb.append(" type='text' id='skipPage' name='' /><b>页</b></li>");sb.append(" <li class='page-item go'><a class='page-link'");sb.append(" href='javascript:skipPage()'>确定</a></li>");sb.append(" <li class='page-item'><b>共"+pageBean.getTotal()+"条</b></li>");sb.append("</ul>");// 分页执行的JS代码sb.append("<script type='text/javascript'>");sb.append(" function gotoPage(page) {");sb.append(" document.getElementById('pageBeanForm').page.value = page;");sb.append(" document.getElementById('pageBeanForm').submit();");sb.append(" }");sb.append(" function skipPage() {");sb.append(" var page = document.getElementById('skipPage').value;");sb.append(" if (!page || isNaN(page) || parseInt(page) < 1 || parseInt(page) > "+pageBean.getMaxPage()+") {");sb.append(" alert('请输入1~"+pageBean.getMaxPage()+"的数字');");sb.append(" return;");sb.append(" }");sb.append(" gotoPage(page);");sb.append(" }");sb.append("</script>");return sb.toString();} }
最后创建一个控制器 HotelController
package com.CloudJun.web;import com.CloudJun.biz.Hotelbiz; import com.CloudJun.model.Hotel; import com.CloudJun.utils.PageBean; import org.springframework.beans.factory.annotation.Autowired; import org.springframework.stereotype.Controller; import org.springframework.web.bind.annotation.RequestMapping;import javax.servlet.http.HttpServletRequest; import java.util.List;/*** @author CloudJun* @create 2023-09-07 14:24*/ @Controller @RequestMapping("/hot") public class HotelController {@Autowiredprivate Hotelbiz hotelbiz;@RequestMapping("/list")public String list(Hotel hotel, HttpServletRequest request){PageBean pageBean = new PageBean();pageBean.setRequest(request);List<Hotel> hotels = hotelbiz.selectHotelPage(hotel, pageBean);request.setAttribute("list",hotels);request.setAttribute("pageBean",pageBean);return "hot/index";}@RequestMapping("/del")public String del(Hotel hotel,HttpServletRequest request){hotelbiz.deleteByPrimaryKey(hotel.getHid());return "redirect:list";}@RequestMapping("/edit")public String edit(Hotel hotel,HttpServletRequest request){hotelbiz.updateByPrimaryKeySelective(hotel);return "redirect:list";}@RequestMapping("/add")public String add(Hotel hotel,HttpServletRequest request){hotelbiz.insertSelective(hotel);return "redirect:list";}@RequestMapping("/revise")public String getHid(Hotel hotel,HttpServletRequest request){if (hotel != null && hotel.getHid() != null && hotel.getHid() != 0){Hotel h = hotelbiz.selectByPrimaryKey(hotel.getHid());request.setAttribute("h",h);}return "hot/edit";}}
五、前端代码
在WEB-INF文件中创建一个static包,以免配置文件报错
再创建一个JSP后台显示界面 名为: index.jsp
<%@ page language="java" contentType="text/html; charset=UTF-8"pageEncoding="UTF-8"%>
<%@ taglib uri="http://jsp.veryedu.cn" prefix="z"%>
<%@ taglib uri="http://java.sun.com/jsp/jstl/core" prefix="c"%>
<!DOCTYPE html PUBLIC "-//W3C//DTD HTML 4.01 Transitional//EN" "http://www.w3.org/TR/html4/loose.dtd">
<html>
<head><meta http-equiv="Content-Type" content="text/html; charset=UTF-8"><linkhref="https://cdn.bootcdn.net/ajax/libs/twitter-bootstrap/4.5.0/css/bootstrap.css"rel="stylesheet"><scriptsrc="https://cdn.bootcdn.net/ajax/libs/twitter-bootstrap/4.5.0/js/bootstrap.js"></script><title>酒店后台管理系统</title><style type="text/css">.page-item input {padding: 0;width: 40px;height: 100%;text-align: center;margin: 0 6px;}.page-item input, .page-item b {line-height: 38px;float: left;font-weight: 400;}.page-item.go-input {margin: 0 10px;}</style>
</head>
<body>
<form class="form-inline"action="${pageContext.request.contextPath }/hot/list" method="post"><div class="form-group mb-2"><input type="text" class="form-control-plaintext" name="hname"placeholder="请输入书籍名称">
<%-- <input name="rows" value="10" type="hidden">--%><!-- 不想分页 -->
<%-- <input name="pagination" value="false" type="hidden">--%></div><button type="submit" class="btn btn-primary mb-2">查询</button><a class="btn btn-primary mb-2" href="${pageContext.request.contextPath }/hot/revise">新增</a>
</form><table class="table table-striped"><thead><tr><th scope="col">房间编号</th><th scope="col">房间名称</th><th scope="col">房间类型</th><th scope="col">操作</th></tr></thead><tbody><c:forEach var="h" items="${list }"><tr><td>${h.hid }</td><td>${h.hname }</td><td>${h.htype }</td><td><a href="${pageContext.request.contextPath }/hot/revise?hid=${h.hid}">修改</a><a href="${pageContext.request.contextPath }/hot/del?hid=${h.hid}">删除</a></td></tr></c:forEach></tbody>
</table>
<!-- 这一行代码就相当于前面分页需求前端的几十行了 -->
<z:page pageBean="${pageBean }"></z:page></body>
</html>创建一个jsp编辑界面,名称为 edit.jsp
<%@ page contentType="text/html;charset=UTF-8" language="java" %>
<%@ taglib uri="http://java.sun.com/jsp/jstl/core" prefix="c"%>
<html>
<head><title>酒店管理编辑界面</title>
</head>
<body>
<form action="${pageContext.request.contextPath }/hot/${empty h ? 'add' : 'edit'}" method="post">房间编号:<input type="text" ${h!=null?'disabled':''} name="hid" value="${h.hid }"><br>房间名称:<input type="text" name="hname" value="${h.hname }"><br>房间类型:<input type="text" name="htype" value="${h.htype }"><br><input type="submit">
</form>
</body>
</html>
六、功能测试
最后开启服务器,在浏览器中请求以下地址( 请求地址是根据自己配置来进行访问的 ): http://localhost:8080/ssm/hot/list
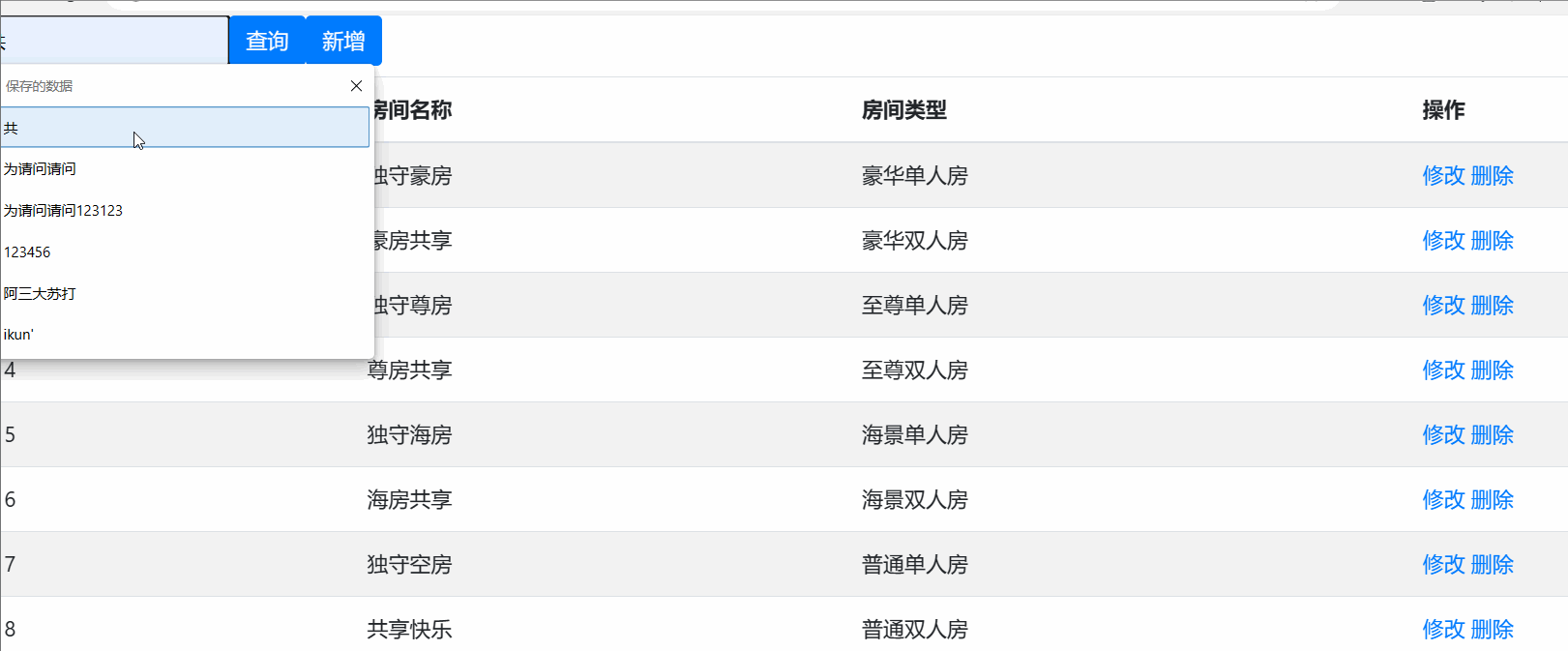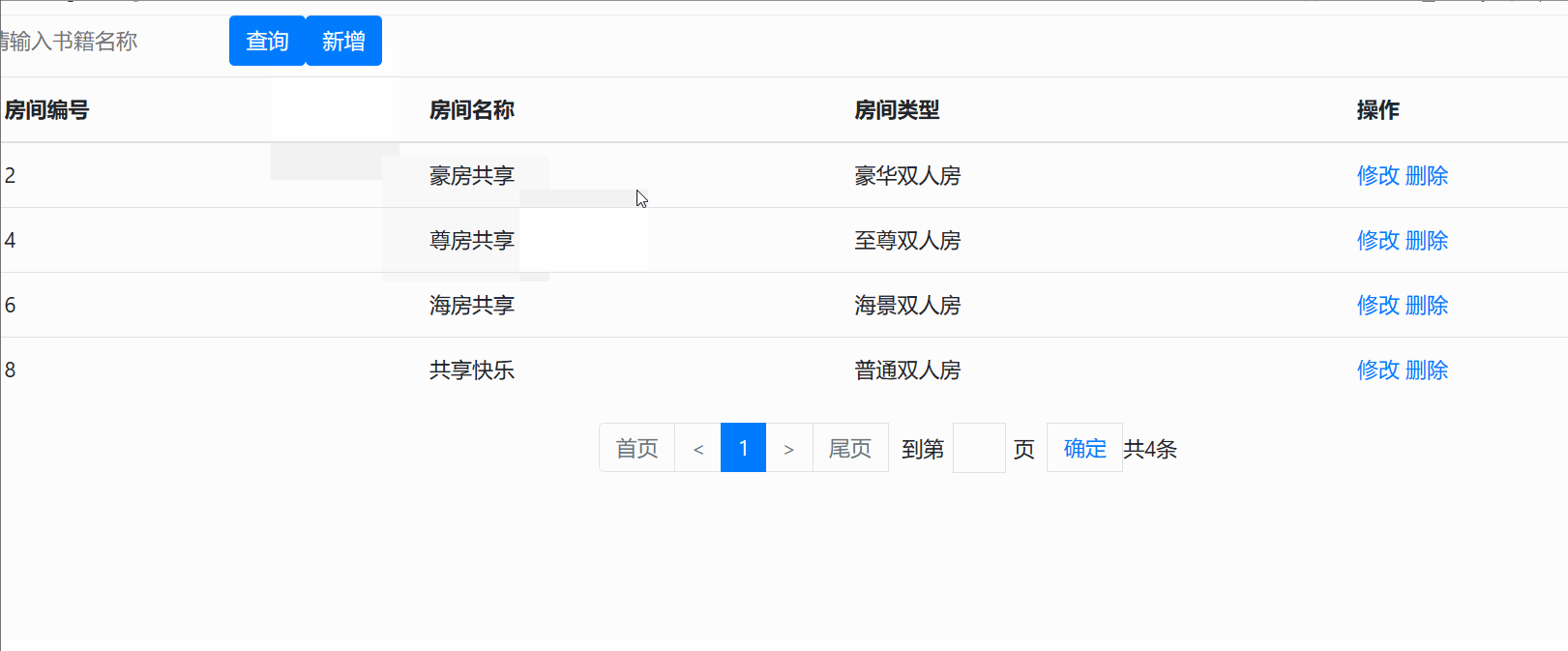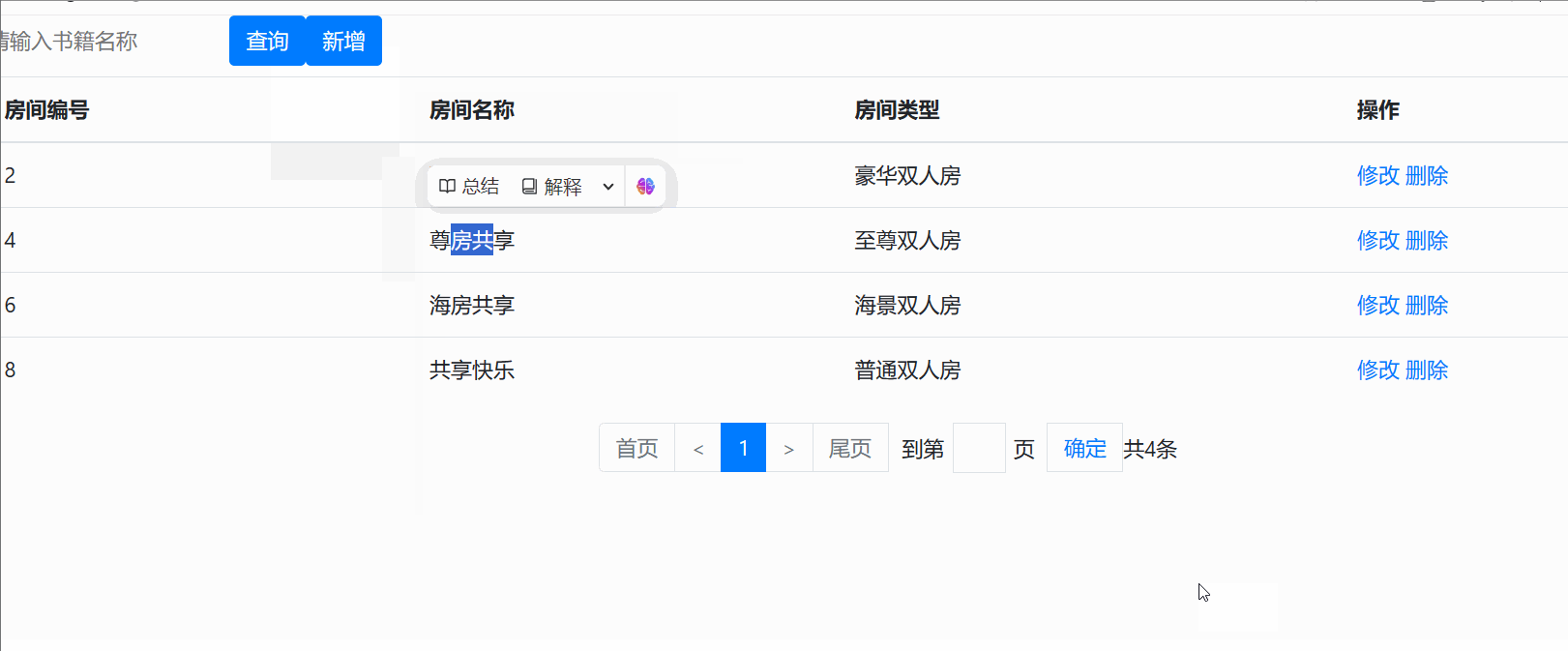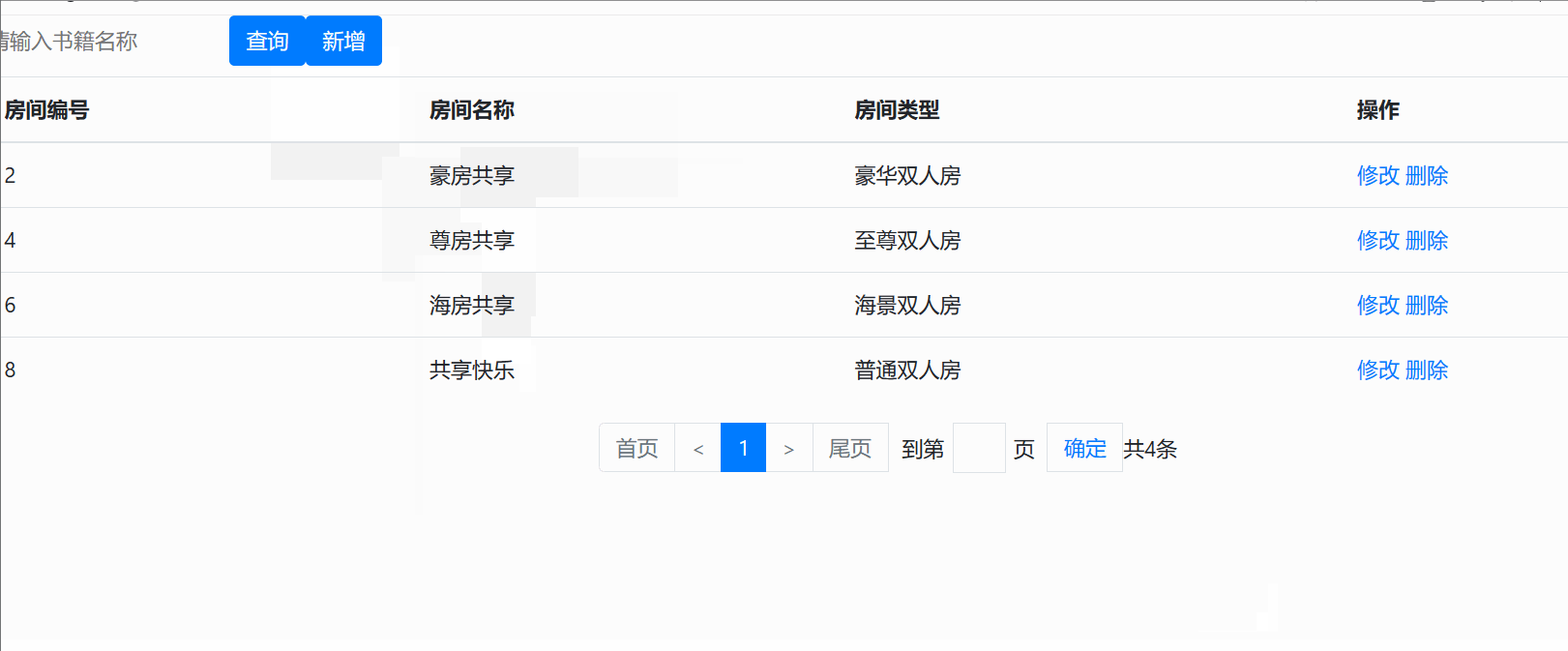
访问后的显示效果为以下界面 :
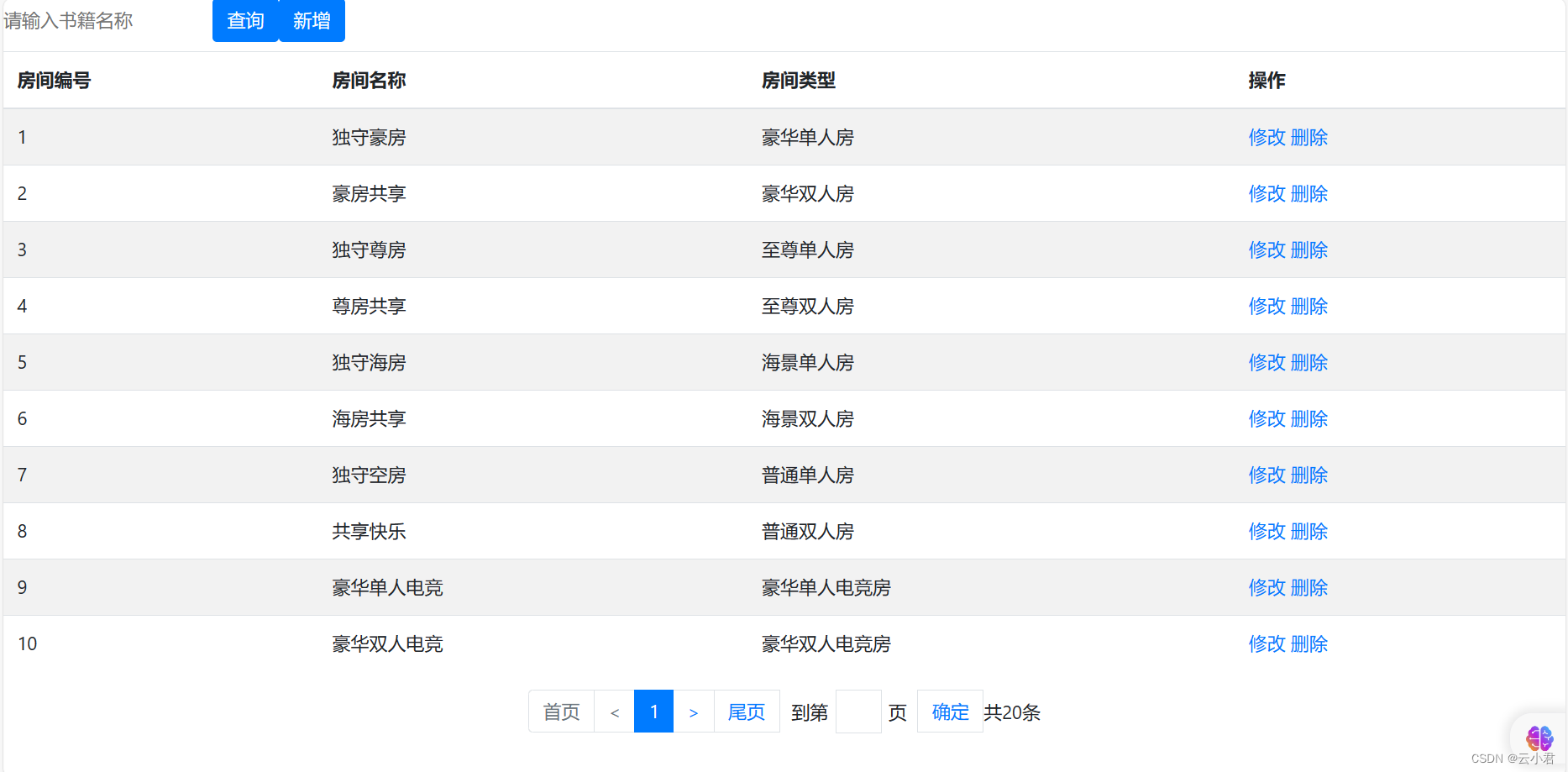
增
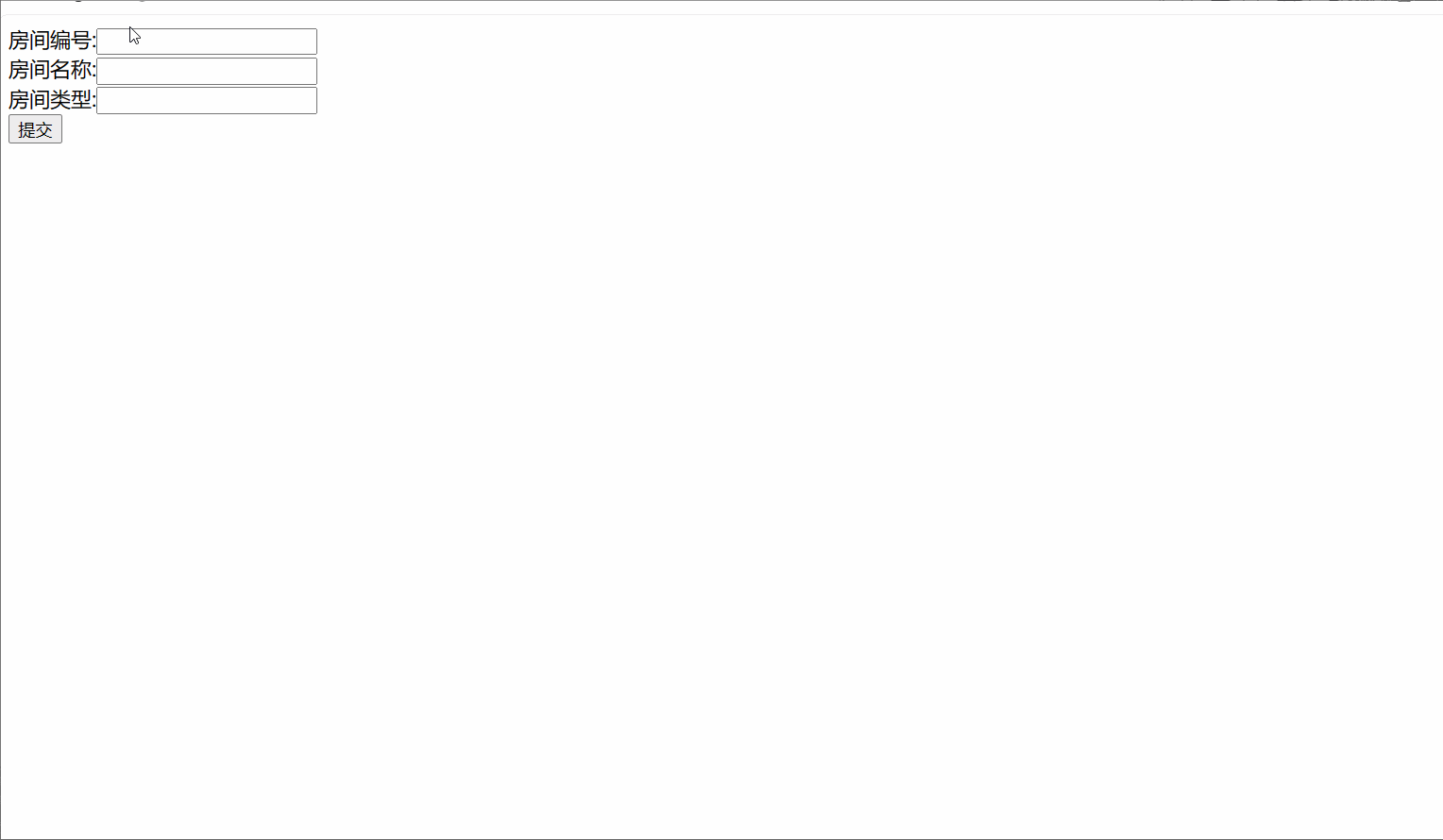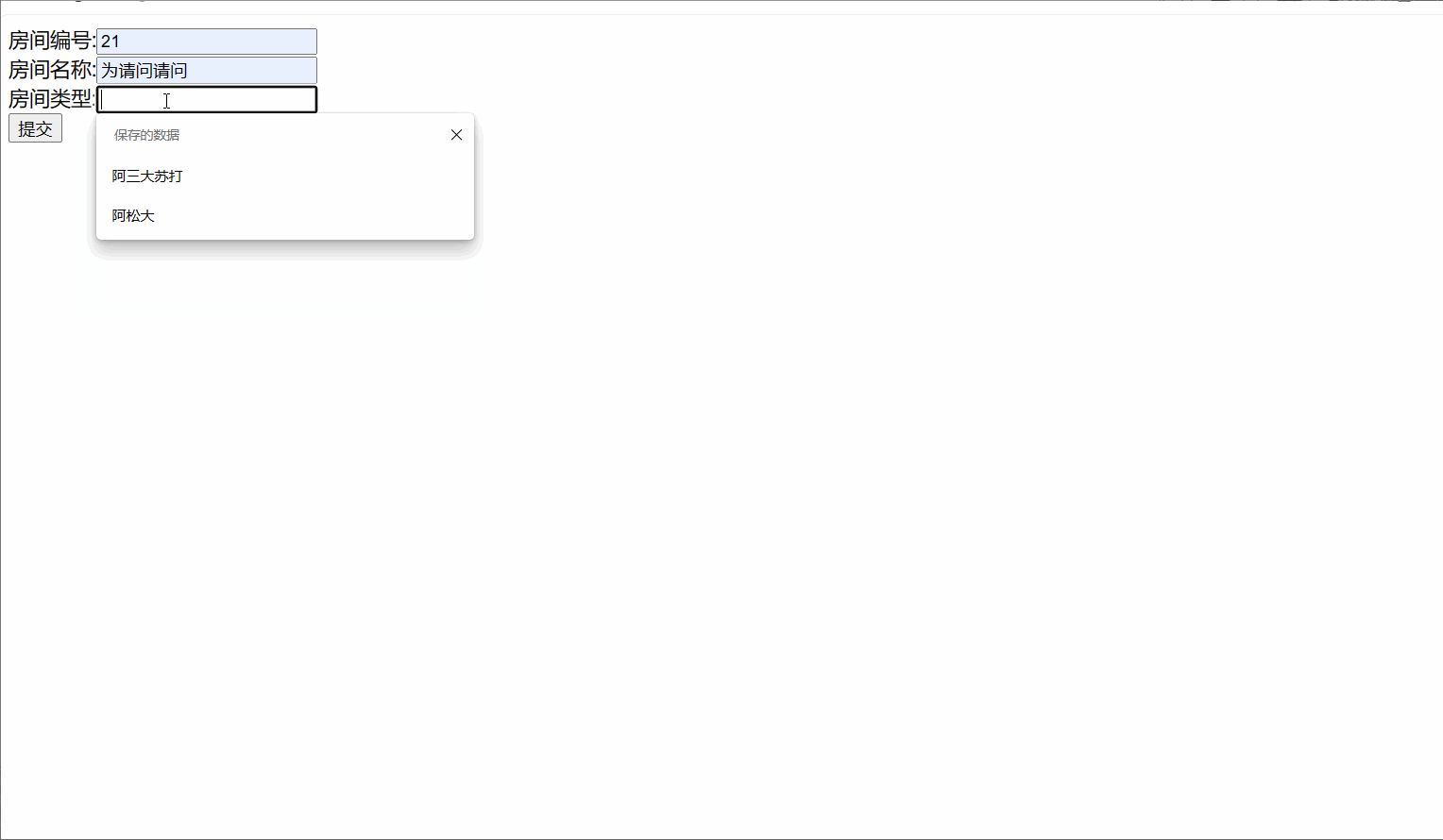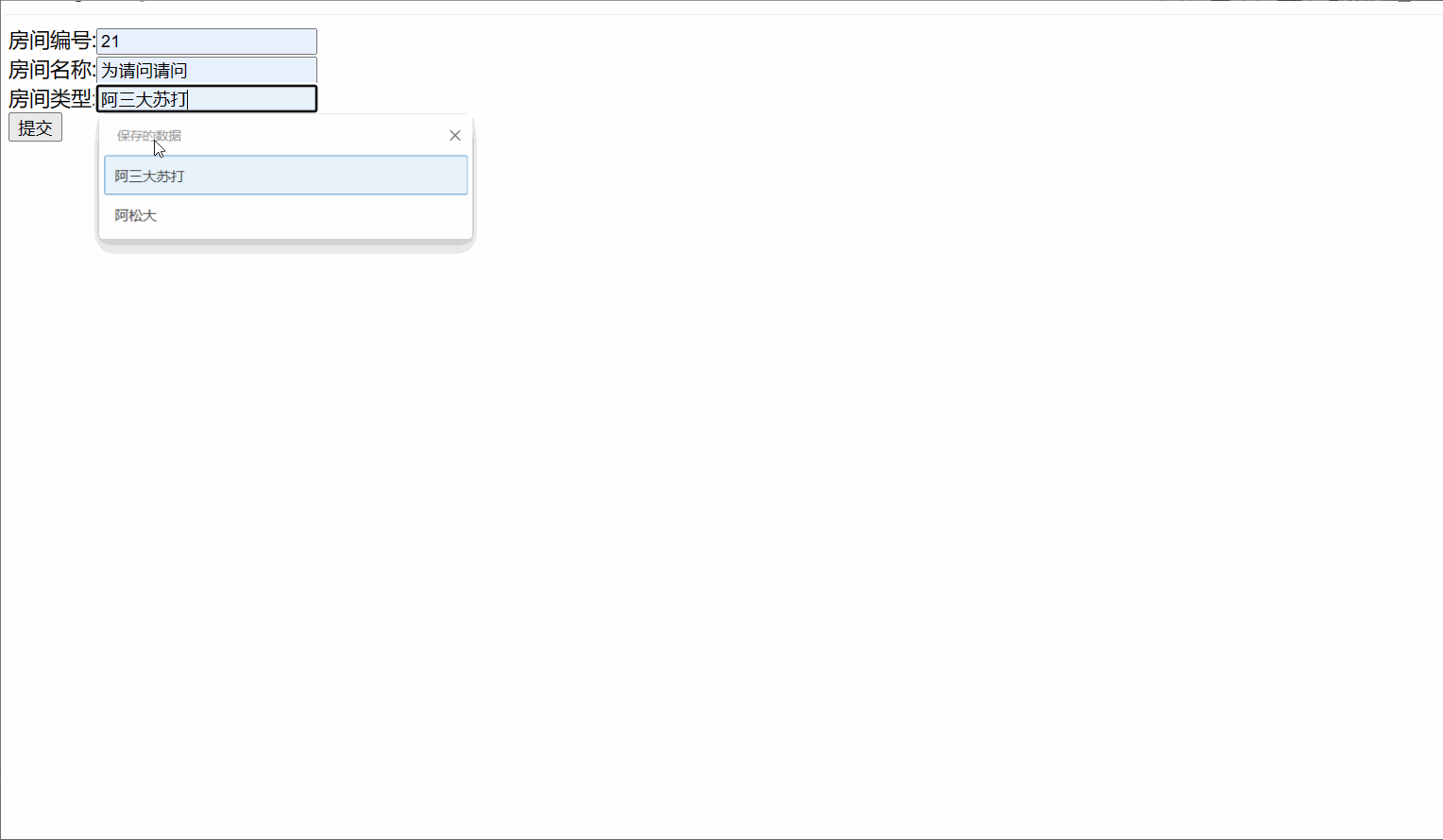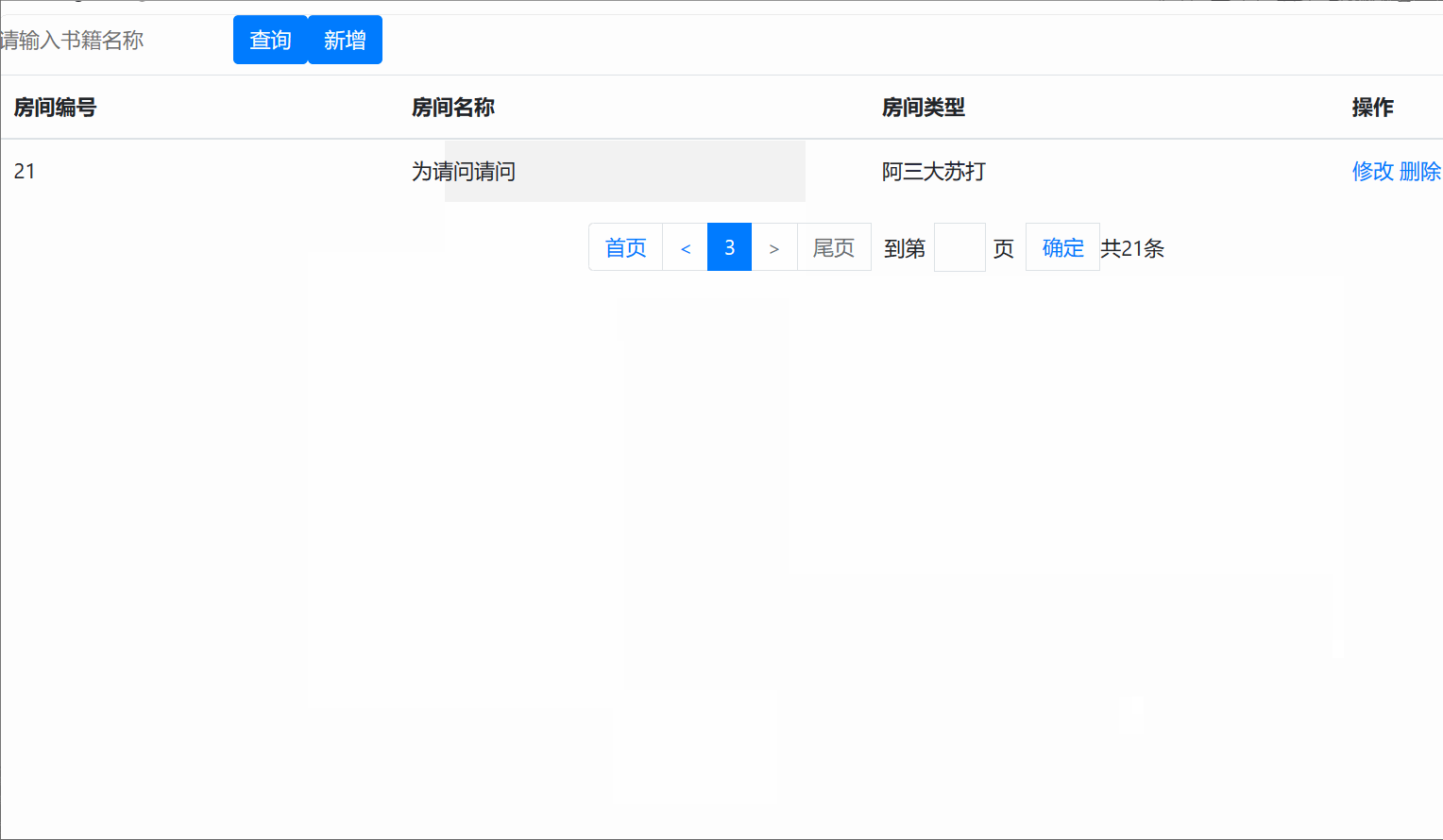
修

删
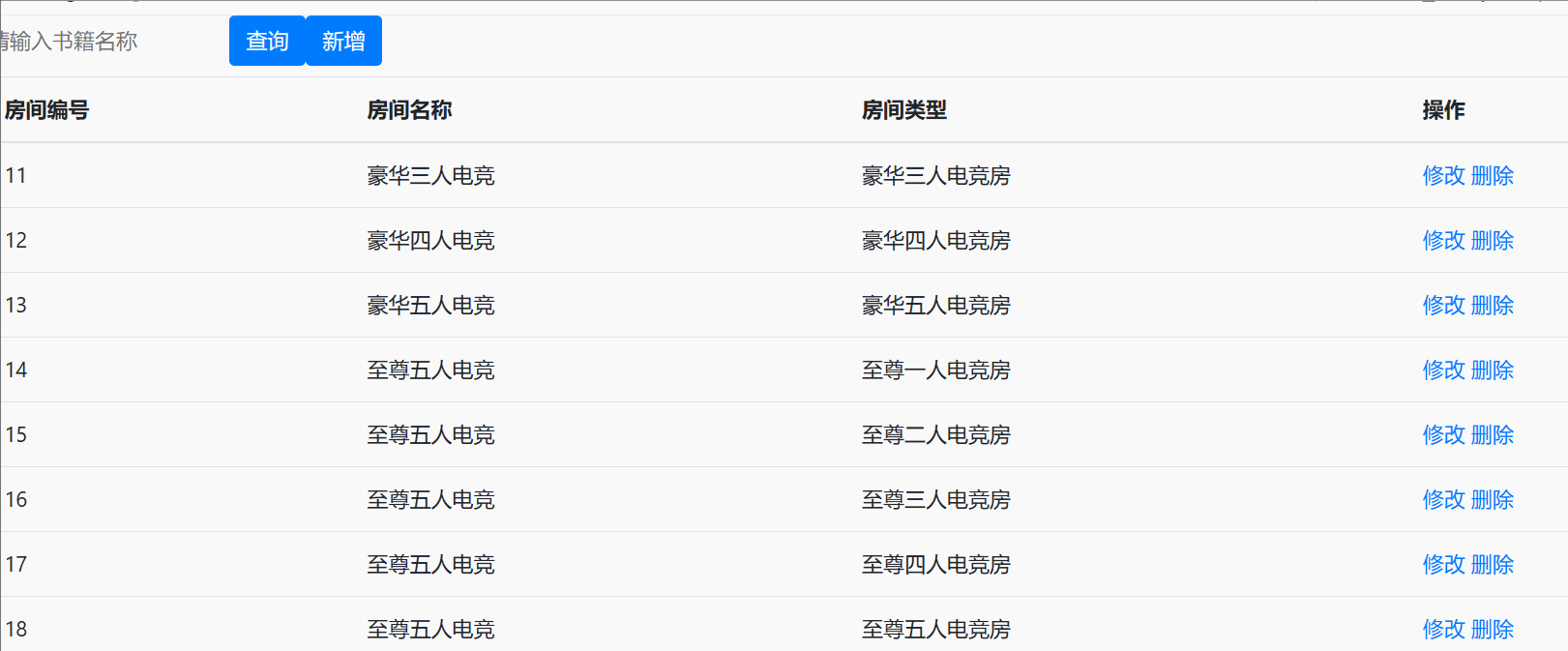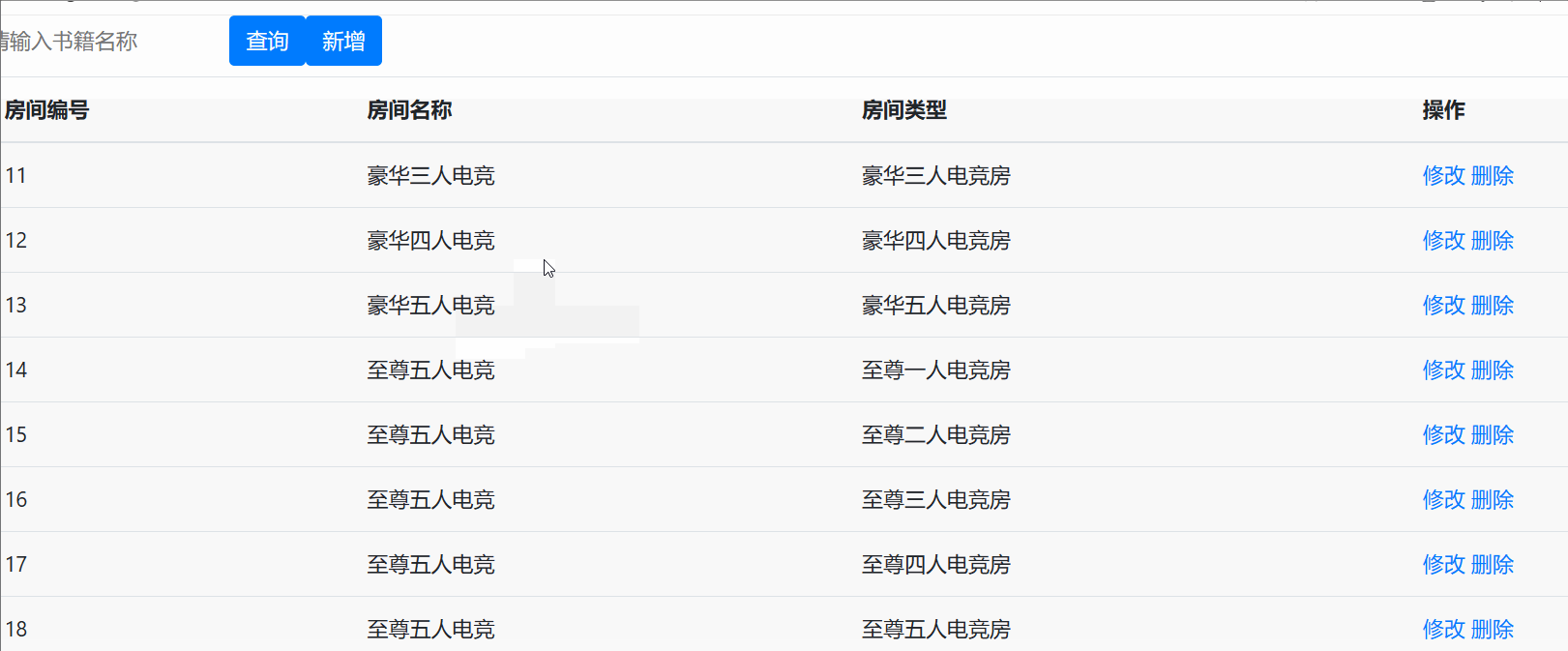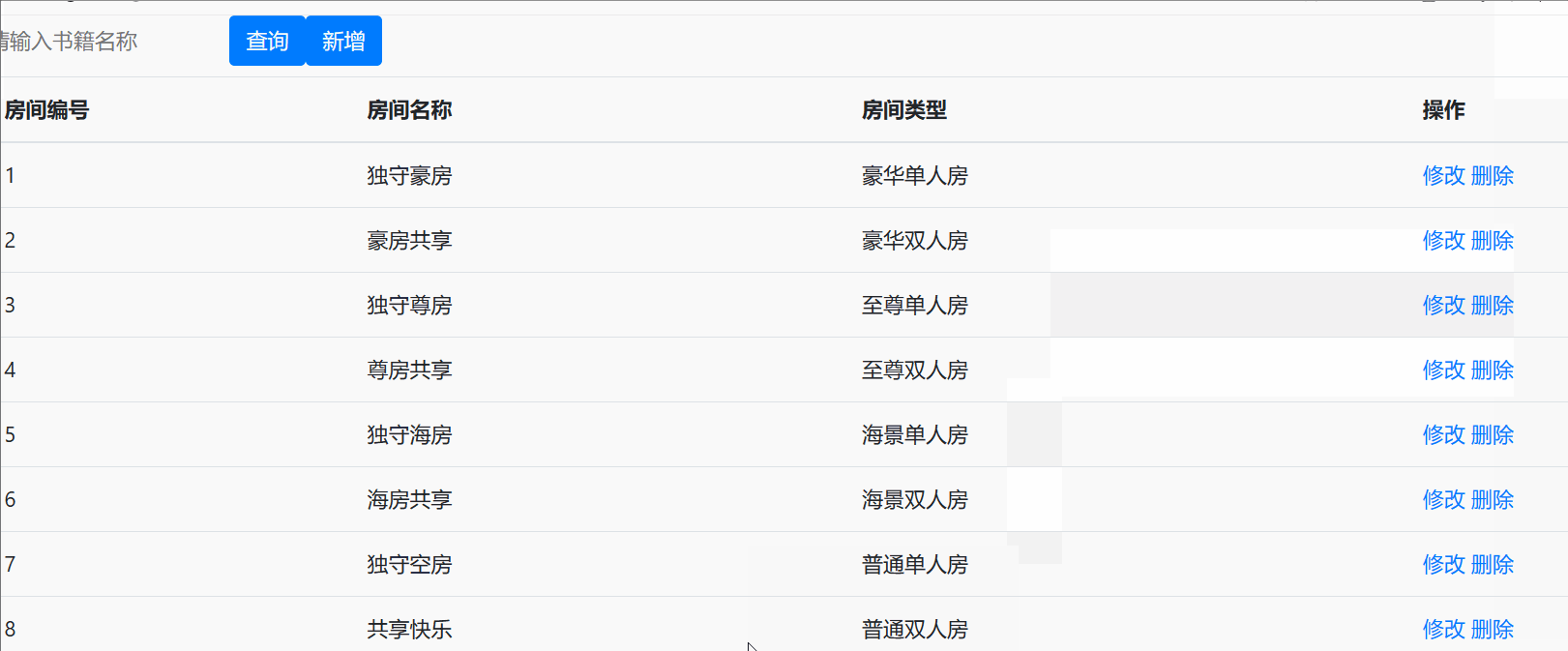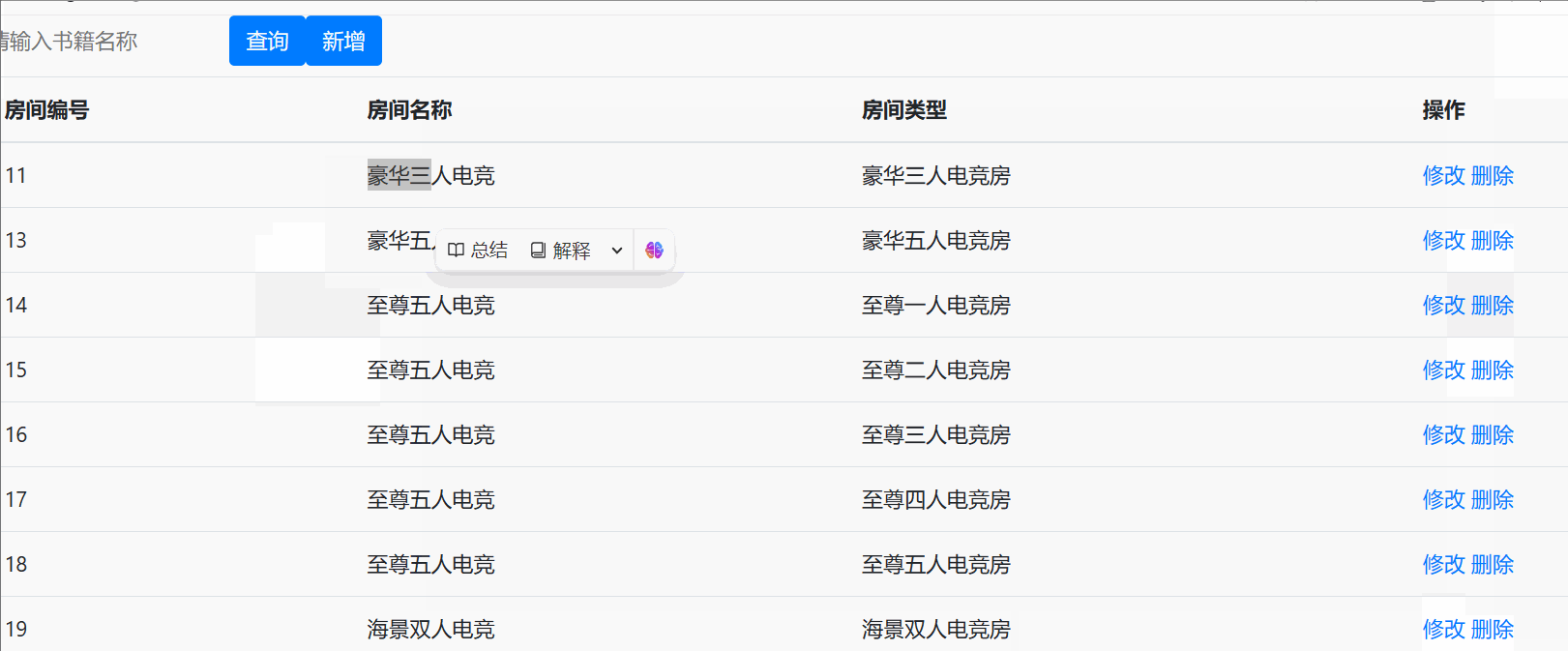
查
给我们带来的收获
学习使用SpringMVC完成CRUD可以给我们带来以下收获:
- 1. 理解MVC架构:SpringMVC是基于MVC(Model-View-Controller)架构的框架,通过学习使用SpringMVC完成CRUD,可以更加深入地理解MVC架构的原理和优势。
- 2. 掌握Web开发的基本原理:SpringMVC是一种用于构建Web应用程序的框架,学习使用SpringMVC完成CRUD可以帮助我们掌握Web开发的基本原理,包括请求-响应模型、URL映射、请求参数处理等。
- 3. 提高代码的可维护性:SpringMVC提供了一套规范和约定,通过学习使用SpringMVC完成CRUD,可以帮助我们编写更加结构化和可维护的代码,提高代码的可读性和可维护性。
- 4. 学习使用Spring框架的其他功能:SpringMVC是Spring框架的一部分,学习使用SpringMVC完成CRUD可以帮助我们了解和使用Spring框架的其他功能,如依赖注入、AOP等。
- 5. 提高开发效率:SpringMVC提供了很多便捷的功能和工具,如数据绑定、表单验证、异常处理等,学习使用SpringMVC完成CRUD可以提高开发效率,减少重复劳动。
总之,学习使用SpringMVC完成CRUD可以帮助我们提升自己的Web开发能力,掌握一种流行的Web框架,并且提高代码的可维护性和开发效率。
