团购网站模块自行网站建设费用预算
文章目录
- 限定符 Qualifier
- 第一个常用限定符 ?
- 第二个常用限定符 *
- 第三个常用限定符 +
- 或运算符
- 字符类
- 元字符 Meta-characters
- \d 数字字符
- \w 单词字符
- 空白符 `\s`
- `.`任意字符
- `^` `$` 行首行尾
- 贪婪与懒惰匹配 Greedy vs Lazy Match
- 实例 1 :RGB颜色匹配
- 实例 2 :IPv4地址匹配
- 总结
正则表达式,你可以把它当做是通配符的增强版,它所做的事情呢,就是去帮你匹配指定规则的字符串,而且它在计算机中的应用可能远比你想象的要多得多。
我们平时编译器中的词法分析器会使用正则表达式去匹配代码中的关键字,网站上注册表单或用到正则表达式去判断密码的复杂程度。在爬虫中,我们同样可以使用正则表达式。提取我们需要的信息,
那我们先来介绍一下,今天要用到的一些工具,为了测试你写的正则表达式呢,这里有很多种办法,我们可以使用编辑器内置的搜索工具。比如,在VS code搜索框的最右边,我们可以点选这个图标,
使用正则表达式去搜索字符串。
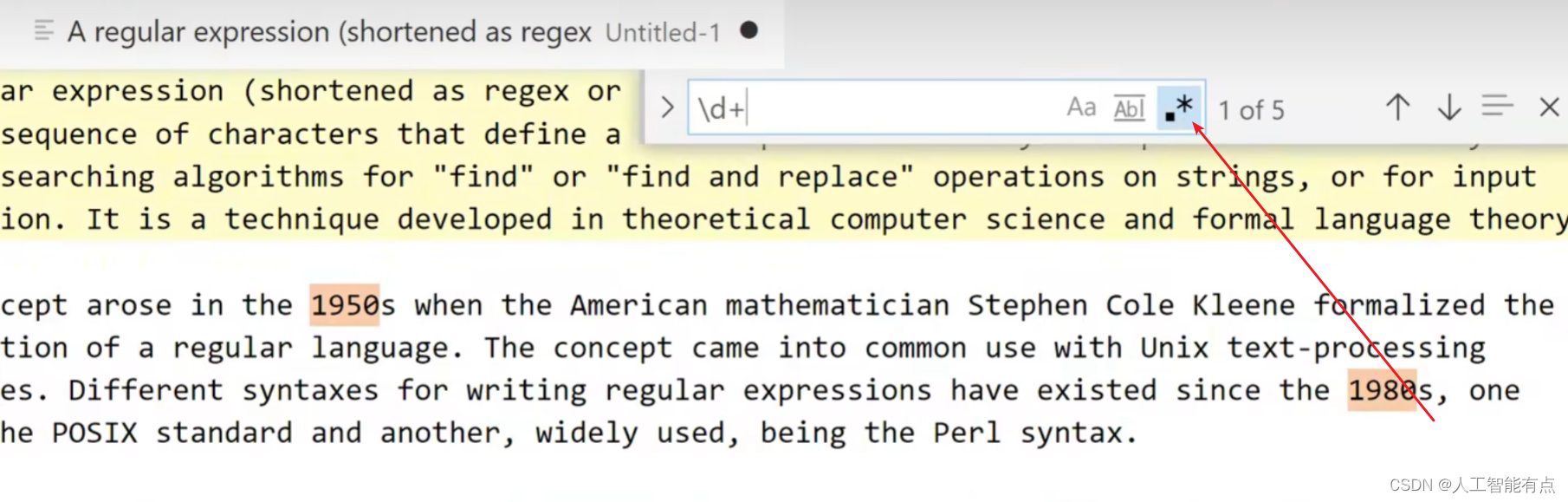
当然,我们也可以在自己熟悉的编程语言中调用函数去测试它。不过这里我推荐一个在线的测试工具,下面是你要测试的文本,上面是正则表达式。左边可以选择正则表达式,在不同语言下的变体,右边是一些帮助信息和参考文档,这里我们随便粘贴一段文字来测试一下,如果我们在上方输入任意表达式。被成功匹配的文本则会以高亮的形式显示出来,那么首先来看一下正则表达式中最基础的用法。
限定符 Qualifier
第一个常用限定符 ?
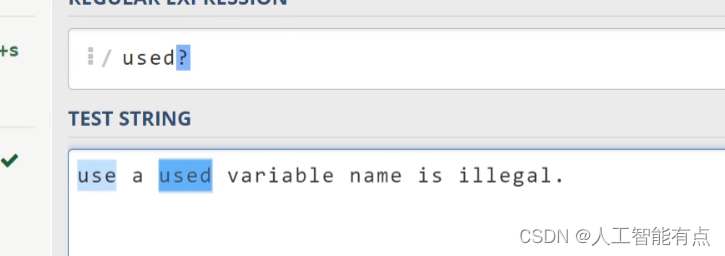
我们现在上方输入我们的第一个正则表达式,** 这里的问号呢?在正则表达式中是一个特殊的字符,它是一个限定符,它代表前面的这个字符d需要出现零次或者一次。 ** 说简单点就是d这个字符可有可无,可以看到我们用这个表达式呢,可以去匹配use这个单词,同样可以去匹配used。
第二个常用限定符 *
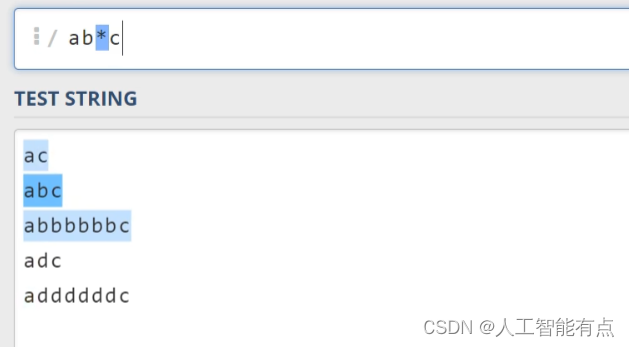
第二个常用到的限定符是星号,它会去匹配零个或者多个字符,比如这里我们输入AB星号c。
星号在这里代表b可以没有,也可以出现多次,那可以看到它成功匹配了下面的ac abc abbbc,但是没有去匹配adc。因为我们表达式中明确规定了a和c中间只能出现零个或者多个b。
第三个常用限定符 +
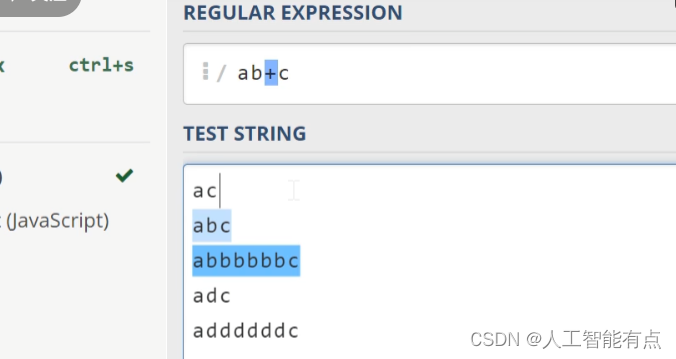
第三个限定符,是我们这里的加号(+)和星号(*)不同的是它会匹配出现一次以上的字符 。如果我们把这里的星号改成加号,可以看到第一个ac就没有被成功匹配了。
如果我们要做到更精确的匹配,比如我们要指定这个。里b出现的次数为六次,我们可以使用花括号,比如这里在花括号里面写上六。
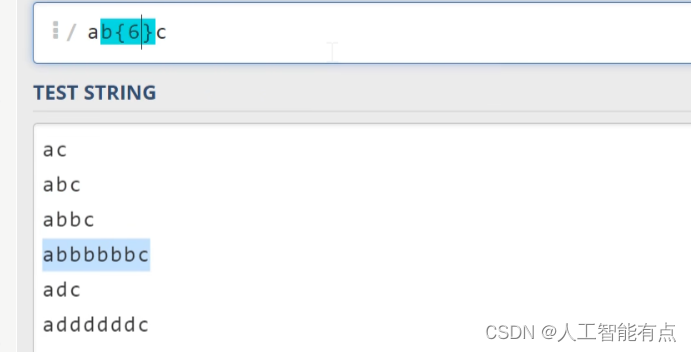
那使用花括号呢,同时允许我们输入一个范围。比如,我们希望字符出现的次数为2到6之间,我们可以写成花括号二,逗号六。
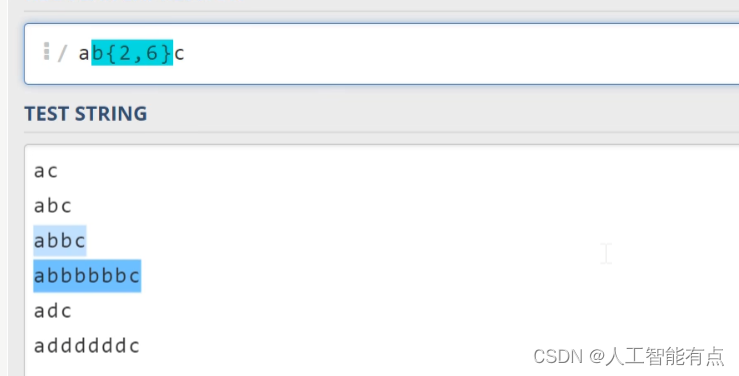
如果我们希望字符出现的次数为两次以上。我们可以直接省略这里的这个六。

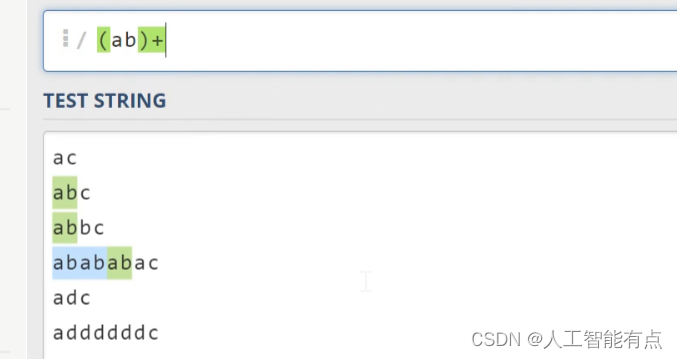
那所有的限定符在这里就讲完了,不过之前限定符的对象是一个字符。如果我们希望去匹配多个字符的重复,那么应该怎么办呢?比如在这个例子中,我们想去匹配中间多次出现的这个ab。我们可以先将ab用括号括起来,然后再在后面添加限定符,可以看到这个正则表达式成功匹配了这里多次ab的出现。
接下来我们来看一下正则表达式中的或运算符。
或运算符
比如这里我们要去匹配a cat或者a dog,我们可以将正则表达式写成这样,那这里前面呢?
会先去匹配a空格,后面括号中内容代表,要么是cat,要么是dog,中间以竖线隔开,并且注意这里的括号是必不可少的,否则就变成了要么是a cat,要么是dog。


字符类
那另一个与运算符相关的是字符类,比如我们想要匹配由ABC这几个字母构成的单词,我们可以写作方括号ABC([abc]),方括号里的内容呢?代表要求匹配的字符只能取自于它们,另外我们可以在方括号里指定字符的范围,比如a杠z([a-z])代表所有的小写英文字符,那大写的a杠z([A-Z])代表所有的大写英文字符。
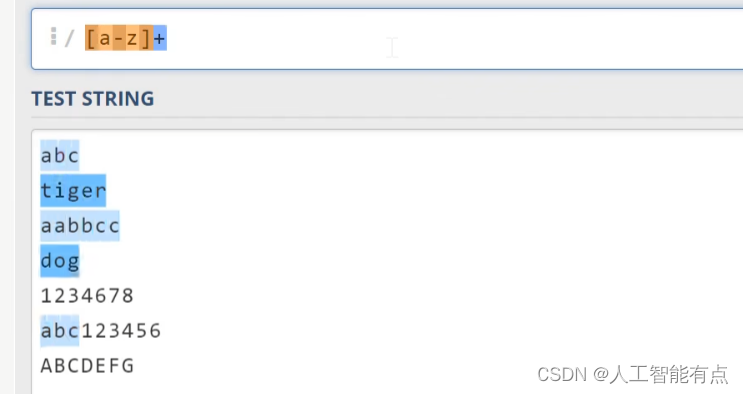
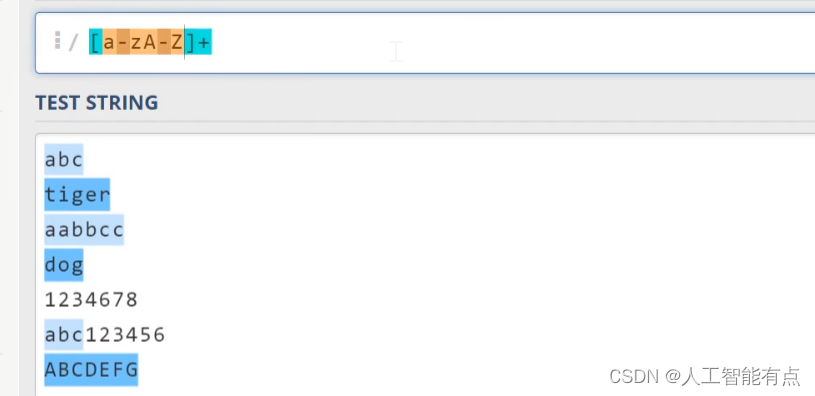
[a-zA-Z0-9]代表所有的英文字符和数字。
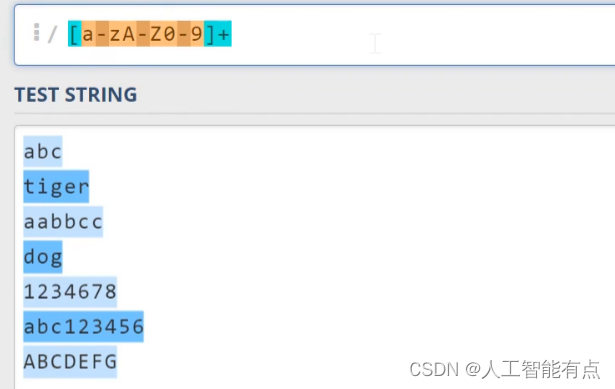
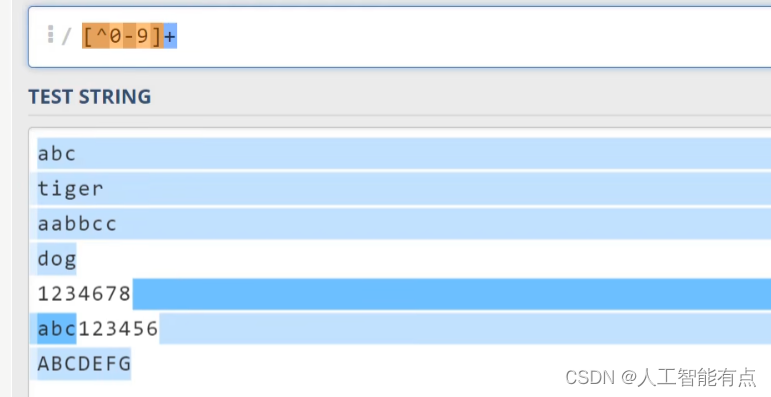
如果在方括号的前面,我们写一个尖号,则代表要求匹配,除了尖号,后面列出的以外的字符,比如[^0-9]。代表所有的非数字字符,但这里面包含换行符。
元字符 Meta-characters
\d 数字字符
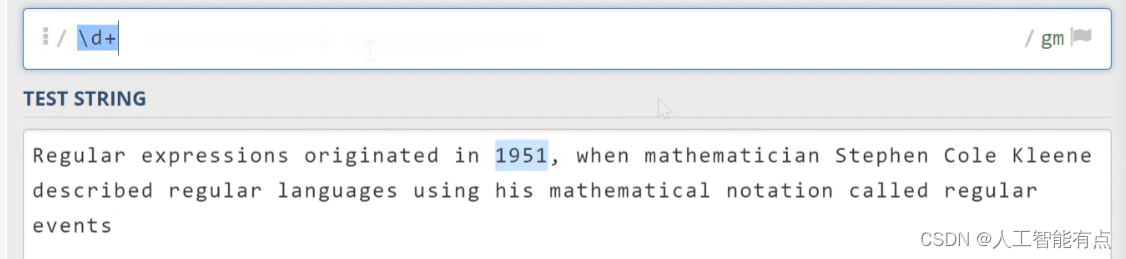
另外正则表达式中其实为我们预先定义好了一系列常用的字符类型,比如数字、空白符、单词开头结尾等等。它们被称作元字符。这个表达式中的大多数元字符都是以反斜杠开头。\d代表数字字符。等同于之前写的[0-9]。
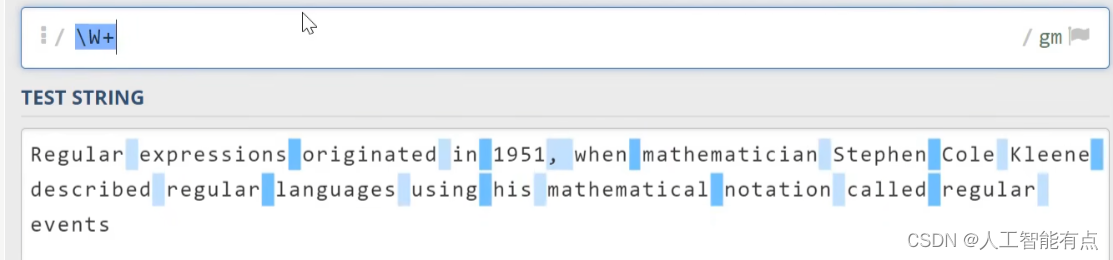
\w 单词字符
\w代表单词字符,也就是所有的英文字符、数字,加上下划线。
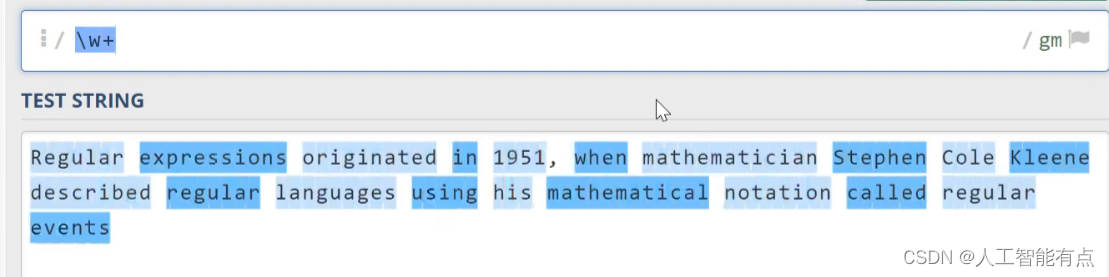
空白符 \s
\s代表空白符,它同时包含tab字符以及换行符。这个需要注意一下。
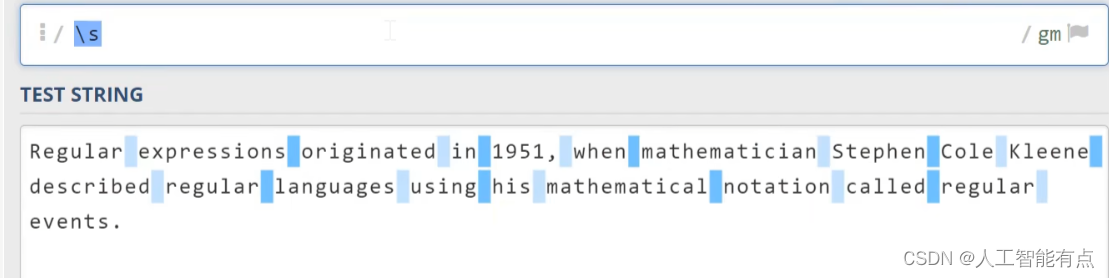
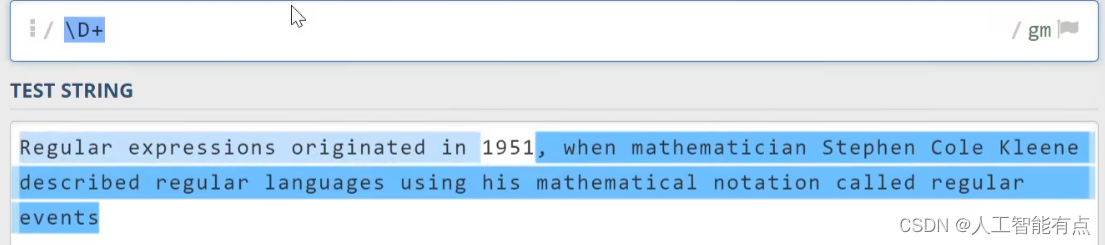
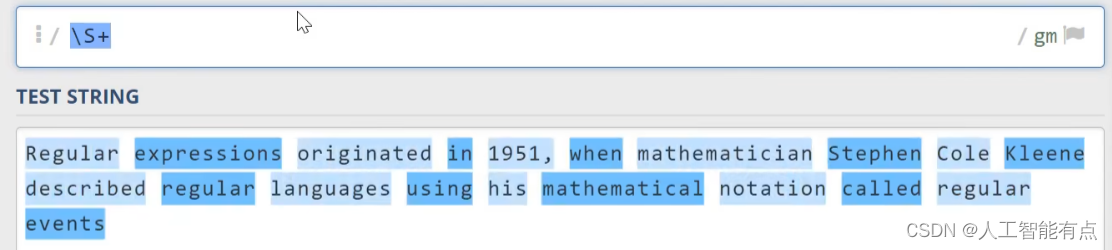
另外,与\d相对应的,大写的\D代表非数字字符。与\w相对应的,大写的\W代表非单次字符。与\s相对应的,大写的\S代表非空白字符
.任意字符
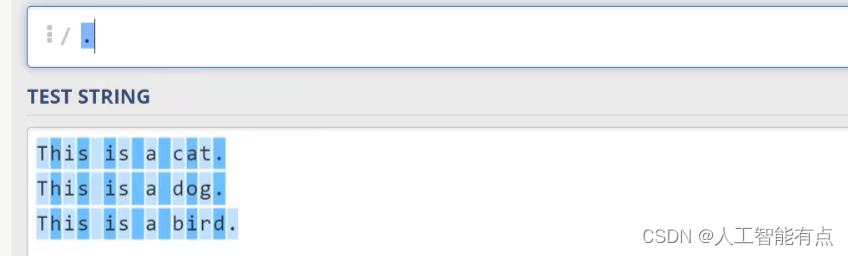
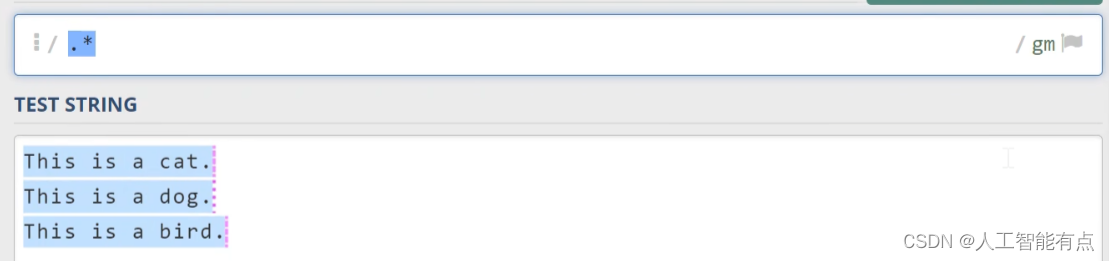
句点呢?在正则表达式中也是一个特殊的字符,它代表任意字符,但不包含换行符。
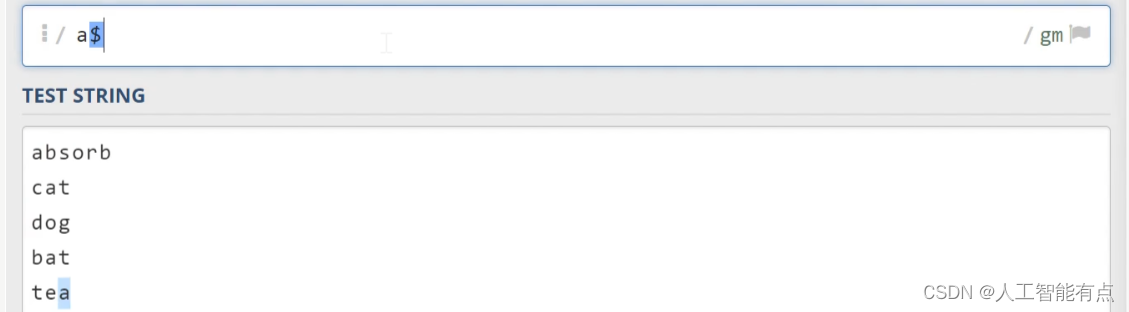
^ $ 行首行尾
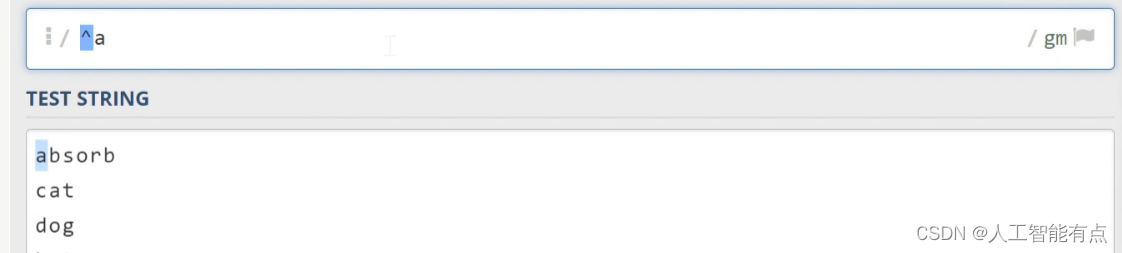
另外,这里呢,还有两个特殊的字符,间号(^)呢,会去匹配行首,美元符号($)会去匹配行尾,比如尖号a(^a)只会去匹配行首的A。A美元符号(a$)只会去匹配行尾的a。
贪婪与懒惰匹配 Greedy vs Lazy Match
接下来我们来介绍一下正则表达式中的一些高级概念。
那之前我们讲到的星号(*)、加号(+),花括号({})在匹配字符串的时候默认会去匹配尽可能多的字符,比如在下面的例子中,我们想去匹配这里面的HTML标签,比如这里的<span>和<b>。我们自然会想到这样的正则表达式,但这里可以看到,这个正则表达式会直接把整个字符串都全部匹配了,原因是因为中间的这个点加号会匹配尽可能多的字符。

我们知道点能代表任意字符。自然也会匹配右尖括号(>),因此才会有这样的结果,但是解决方法也很简单,我们只需要在加号右边加一个问号(?)就好了,它会将正则表达式中默认的贪婪匹配(Greedy Match)切换为懒惰匹配(Lazy Match),这招在实际使用中也会经常被用到。

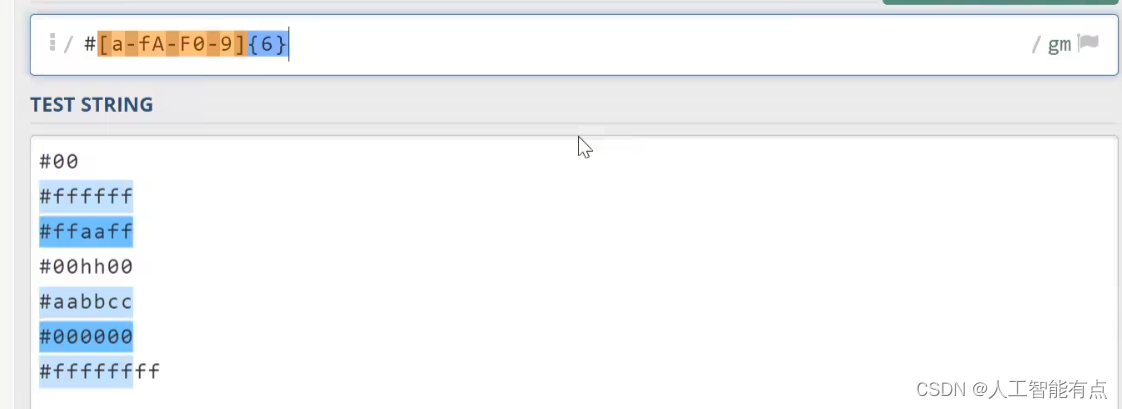
实例 1 :RGB颜色匹配
比如这里我们想要匹配文本中出现的所有16进制的rgb颜色值。我们可以首先去匹配前面的井号,那接下来呢,因为代表每一个颜色值的字符都是16进制,因此它们只能取自于a到f之间或者大写的A到F或者0到9之间。并且字符一定需要出现六次。
最后我们可以在表达式末尾加入杠b(\b)来代表单词字符的边界。这样可以避免这里不符合要求的文本也被识别成rgb颜色值。
实例 2 :IPv4地址匹配
在第二个例子中,我们来讲一下IP地址的匹配IPV 4的地址呢,实际上是由四段数字构成,数字之间由据点隔开。如果要在文本中提取所有出现的IP地址,我们可以直接使用下面这种正则表达式杠d(\d)加号会匹配任何长度大于一的数字。杠句点(\.)代表句点这个字面量,因为句点在正则表达式中是一个特殊的符号,所以我们需要在这里用反斜杠做转义。
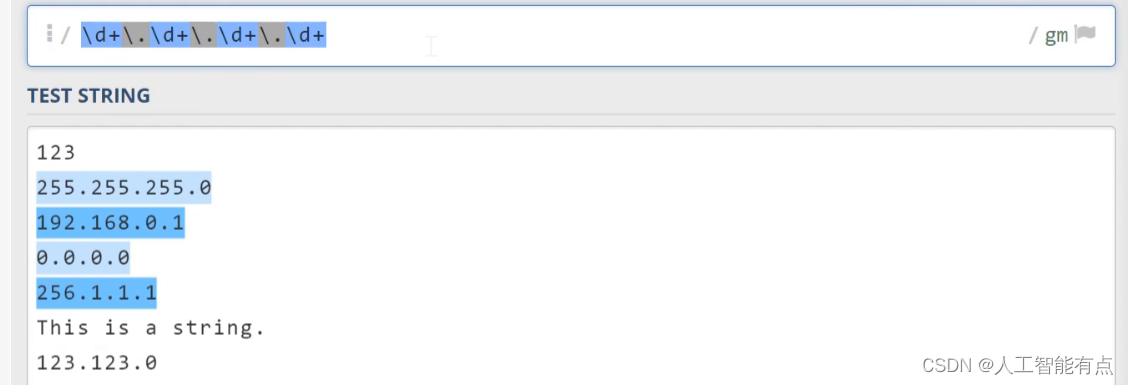
可以看到,这里正在表达式也成功的帮我们匹配了这四个结果。不过,这里有一个问题,我们知道IP地址的每一部分都是八位的数字。也就是说,它的范围介于0到255之间,但这里的这个数字显然已经超出了范围,但是还是被正则表达式成功匹配了。
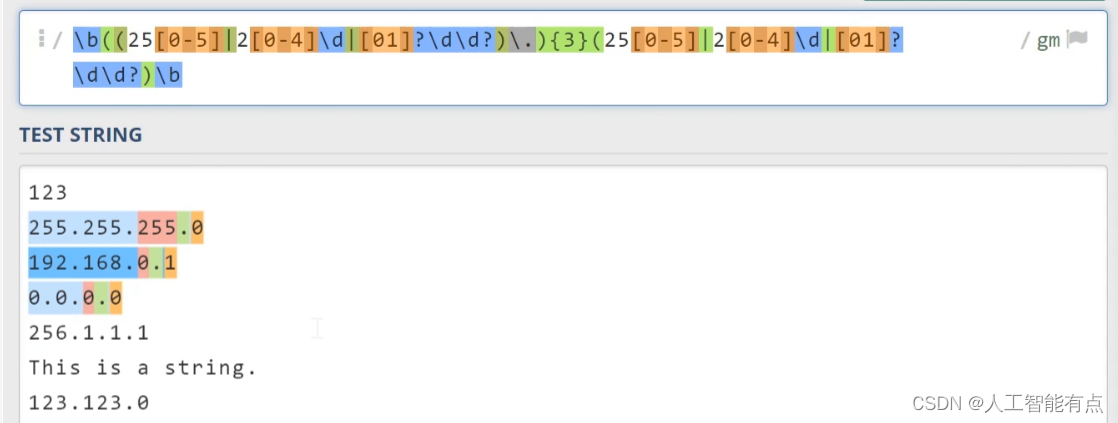
所以如果这里我们要做改良的话呢,我们可以使用下面这段逻辑,我们先来看IP地址被句点隔开的每一部分。
- 如果它的前两位是二五,那么最后一位只能取0到5之间的数字;
- 如果它的第一位是二,第二位是0到4之间的数,那么最后一位可以取0到9之间的任意值。这里用杠d代替;
- 如果它第一位是零或者一,那么最后两位可以取00到99之间的任意数字,我们用杠d(
\d)杠d(\d)代替;- 但是我们也知道IP地址的每一部分呢,也可以由两位数字构成,甚至是一位这样都是合法的,因此呢,我们可以直接将这里的第一个数字和第三个数字后面都加一个问号(
?)。就可以表示这种情况了。数字的部分呢,我们就匹配完了。
- 但是我们也知道IP地址的每一部分呢,也可以由两位数字构成,甚至是一位这样都是合法的,因此呢,我们可以直接将这里的第一个数字和第三个数字后面都加一个问号(
接下来我们来匹配后面的句点之后呢,我们将全部表达式用括号(())括起来。这一段((25[0-5]|2[0-4]\d|[01]?\d\d?)\.)呢,我们要求重复匹配三次,正则的表达式会匹配IP地址的前三段,并且包含每段后面的句点。至于最后面的一段数字,我们只需要将匹配第一段数字的这个部分((25[0-5]|2[0-4]\d|[01]?\d\d?))复制过来即可,最后呢,我们在首尾都加入杠b(\b)来匹配字符的边界。可以看到,经过改良版的正则表达式,可以成功的匹配这里的三个IP地址,并且把不符合要求的这个排除在外了。但这个例子呢,也比较复杂。
最后呢,我列了个表,总结一下讲到的所有要点。但是在正则表达式中,其实还有许多没有讲到的高级概念。比如补货断言递归平衡组等等。
总结
- 限定符
a*:a出现0次或多次a+:a出现1次或多次a?:a出现0次或1次a{6}:a出现6次a{2,6}:a出现2-6次a{2,}:a出现两次以上
- 或运算符
(a|b):匹配a或者b(ab)|(cd):匹配ab或者cd
- 字符类
[abc]:匹配a或者b或者c[a-c]:同上[a-fA-F0-9]:匹配小写+大写因为字符以及数字[^0-9]:匹配非数字字符
- 元字符
\d:匹配数字字符\D:匹配非数字字符\w:匹配单词字符(英文、数字、下划线)\W:匹配非单词字符\s:匹配空白符(包括换行符、Tab)\S:匹配非空白符.:匹配任意字符(换行符除外)\bword\b:\b标注字符的边界^:匹配行首$:匹配行尾
- 贪婪/懒惰匹配
<.+>:默认贪婪匹配“任意字符”<.+?>:懒惰匹配“任意字符”