做彩票网站违法的吗宁波市建筑业管理信息网
proxy代理与reflect
在这之前插入一个知识点arguments,每个函数里面都有一个arguments,执行时候不传默认是所有参数,如果传了就是按顺序匹配,箭头函数没有
代理函数
代理对象也就是生成一个替身,然后这个替身处理一切的get跟set
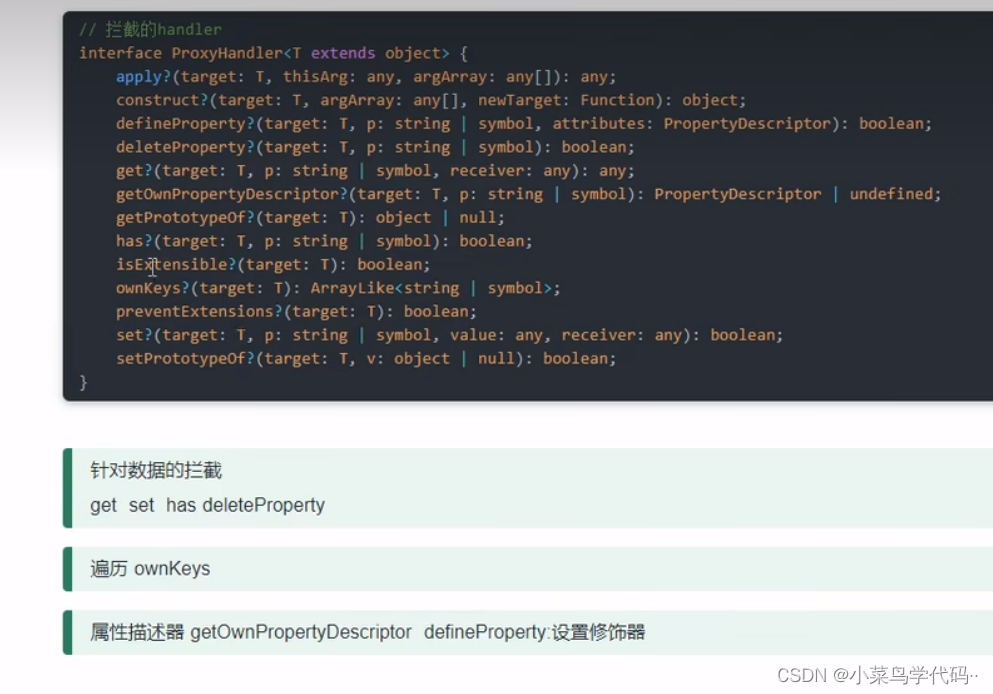
let obj = {name: '张三',age: 18,sex: '男'}let proxy = new Proxy(obj, {get: (target, key, v) => { //读取 1.原对象,2.属性名3.proxy对象if (key === 'age') {return target[key] = '今年108岁'} else {return target[key]}},set: (target, key, v) => { //存储 1.原对象,2.属性名3.修改值if (key == 'name') {target[key] = '你的年龄108岁' //不需要return 直接返回就行} else {target[key] = v}},deleteProperty: (target, key) => { //删除第一个参数对象,第二个属性名return delete target[key]},has: (target, key) => { //包含第一个参数对象,第二个属性名console.log(target, key);return key in target //返回值}})// delete proxy.sex //删除proxy.name = '里斯'console.log('age' in proxy); //包含
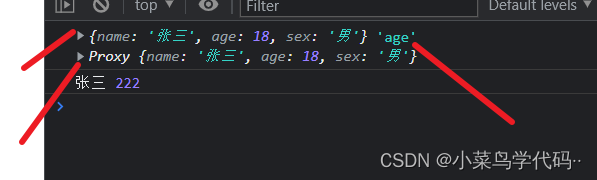
proxy常见的几种方法
- get :获取属性 原始对象,属性名,proxy 对象
- set:修改属性 对象,属性名 没有返回值,直接修改,不过在写的时候常常返回一个Reflect
- deleteProperty:删除属性 对象,删除属性名
- has:包含 对象,包含属性名
-apply :拦截,可以进行函数方法的一个拦截处理,具体看下图
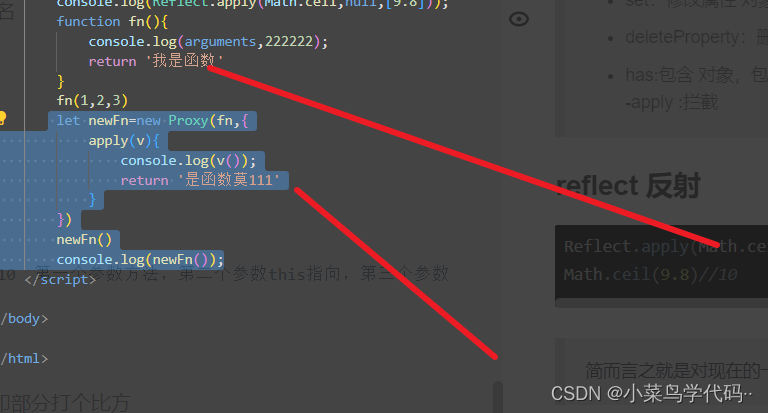
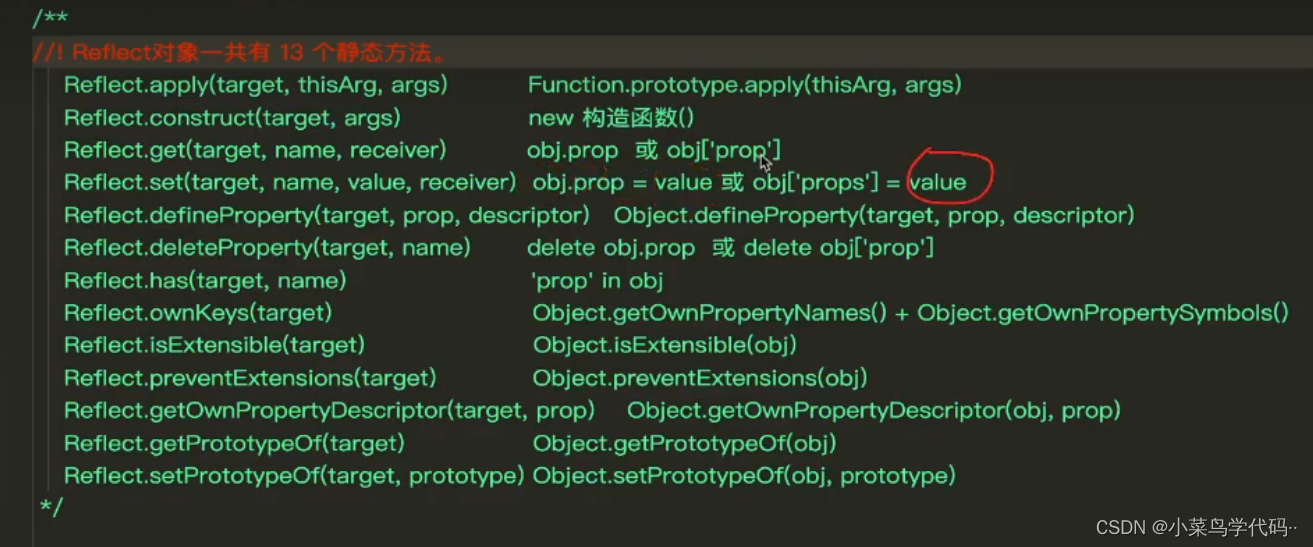
reflect 反射
Reflect.apply(Math.ceil,null,[9.8])//向上取整10 第一个参数方法,第二个参数this指向,第三个参数args参数数组
Math.ceil(9.8)//10
简而言之就是对现在的一个对象或者方法的复印部分打个比方,下面两种方式都能删除也就是es6的一种新语法兼容性并不是很好,现阶段,对象object中的某些方法同时部署在reflect上,也就是说
object约等于reflect并且明确表明会慢慢的往上面迁移,比如object.defineProperty,reflect.defineProperty
let json={a:1,b:2}delete json.aconsole.log(json);//{b:2}Reflect.deleteProperty(json,'a')console.log(json);//{b:2}
最后来一个简单的双向绑定代码
<div><input type="text" id="input"><p id="show"> </p></div><script>let obj = {}const input = document.getElementById('input')const show = document.getElementById('show')let newObj = new Proxy(obj, {get(oldObj, key, proObj) {return Reflect.get(oldObj, key, proObj)},set(oldObj, key, value) {if (key === 'text') {input.innerHTML = valueshow.innerHTML = value}return Reflect.set(oldObj, key, value)}})input.addEventListener('keyup', function (e) {newObj.text = e.target.value})</script>
