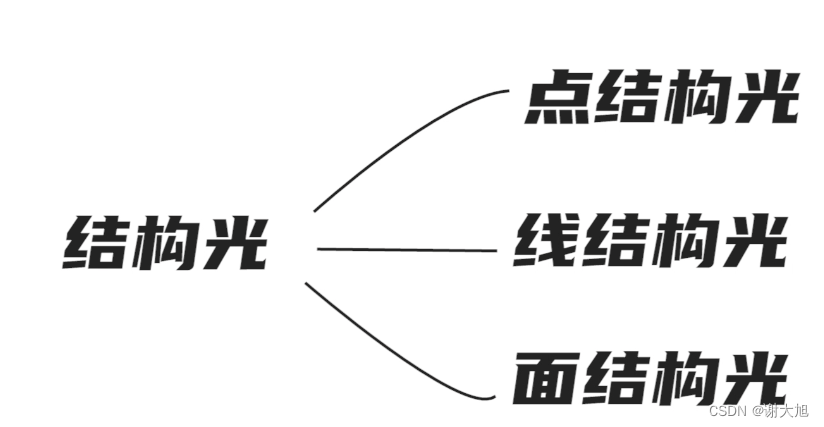
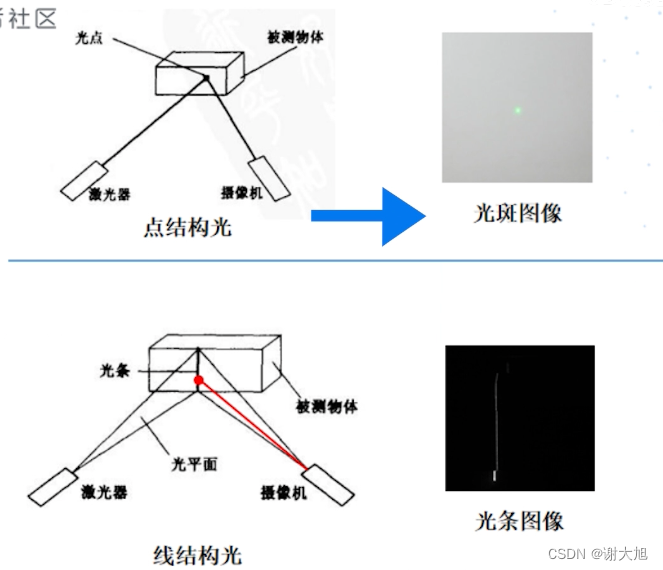
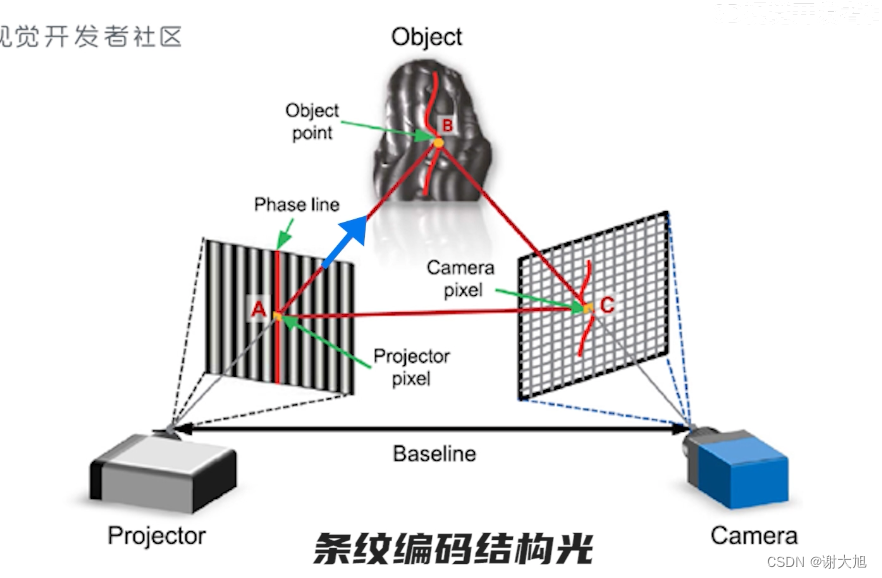
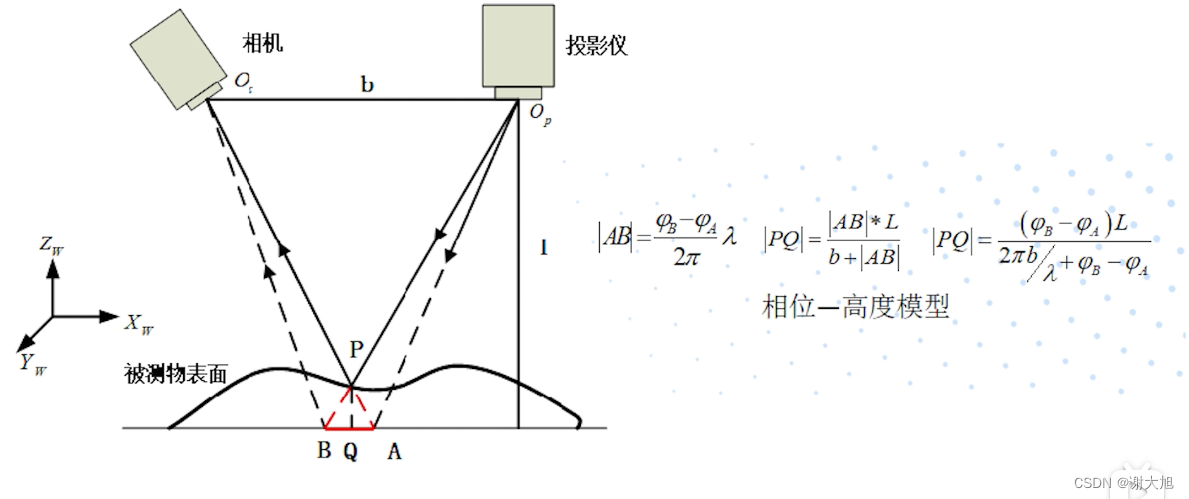
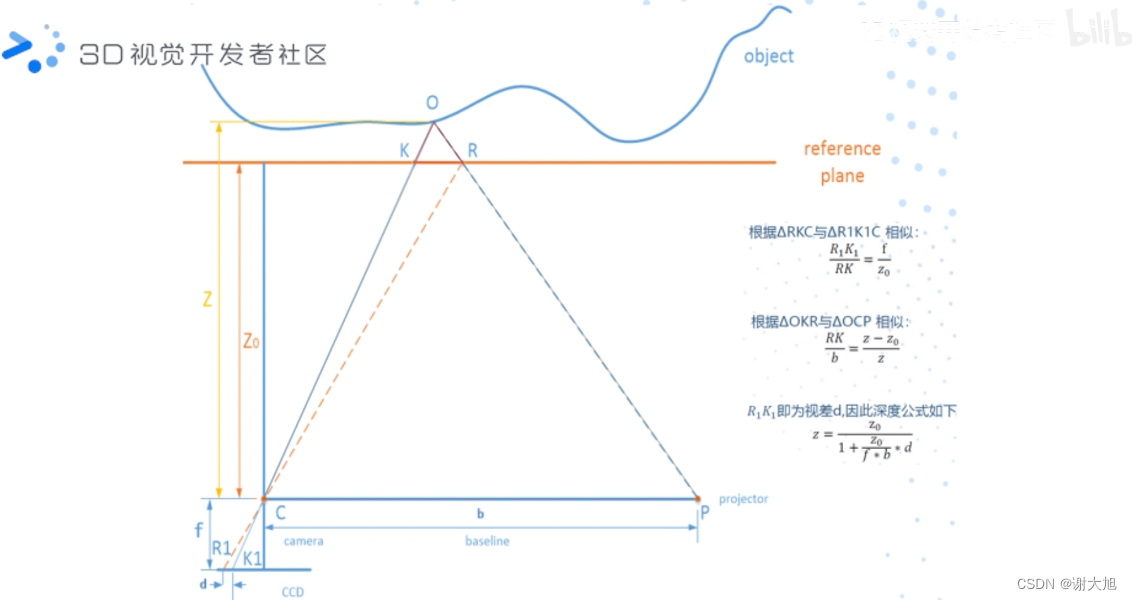
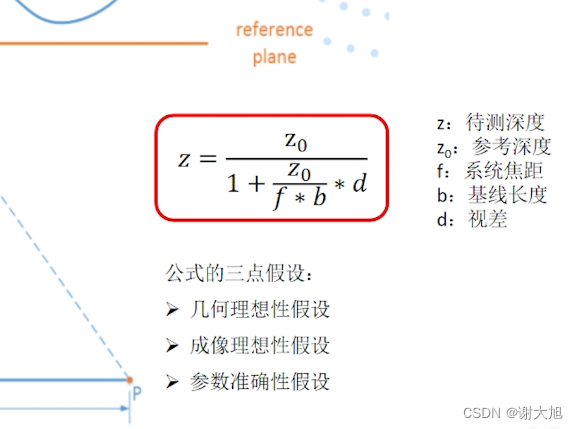
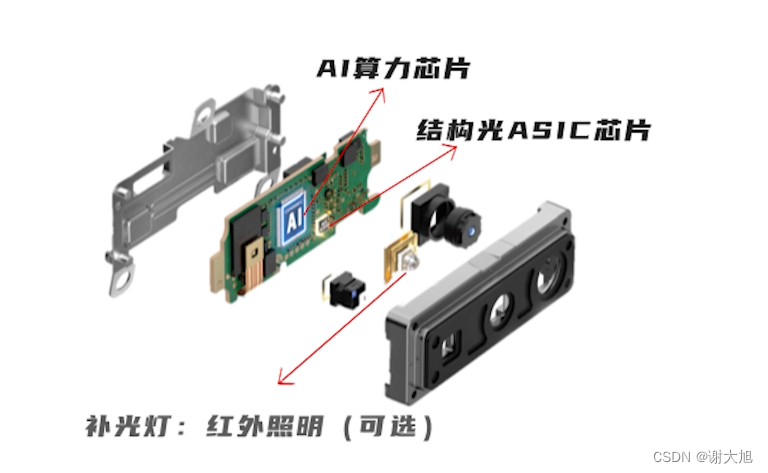
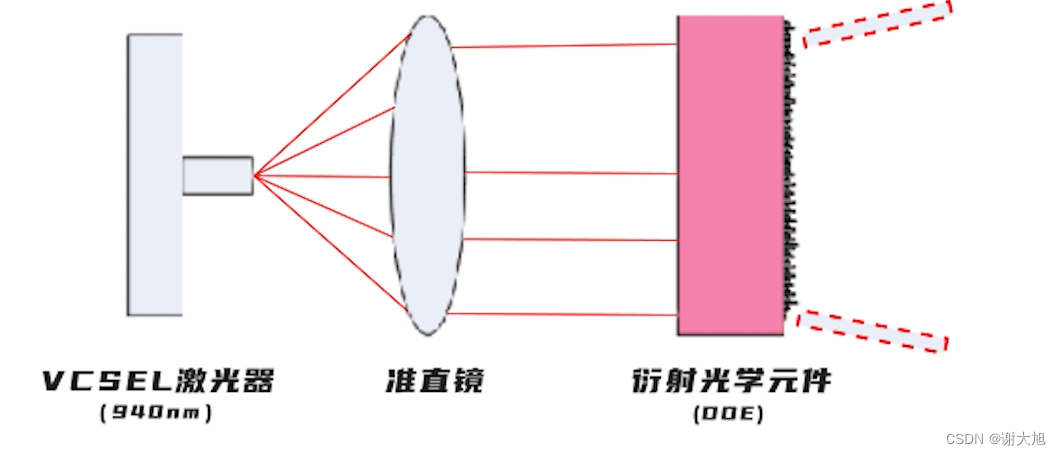
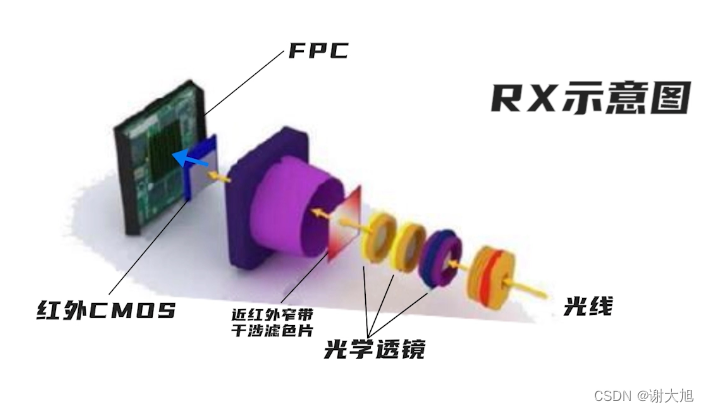
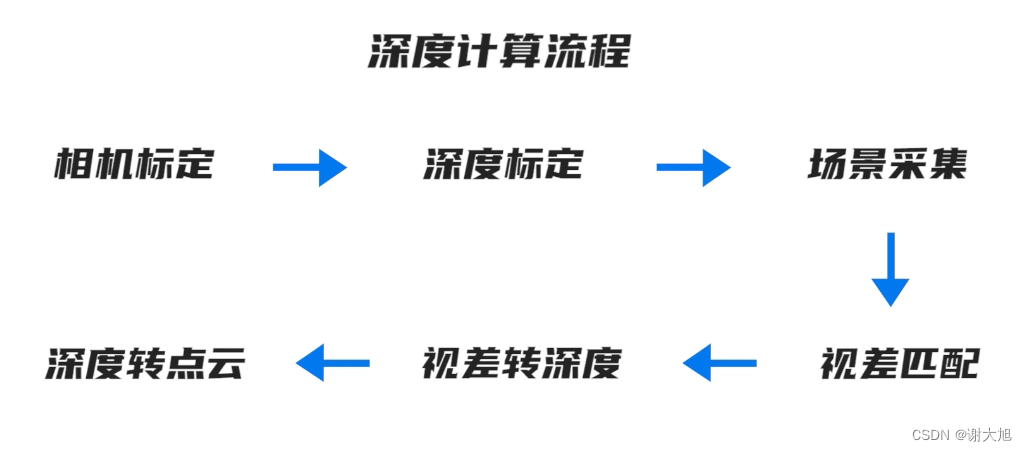
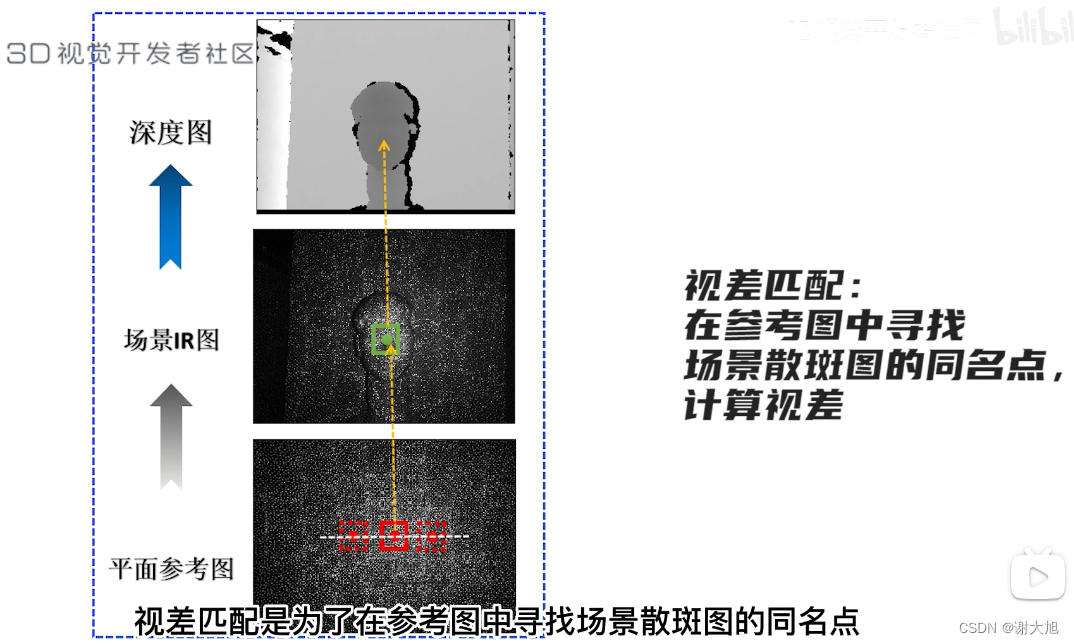
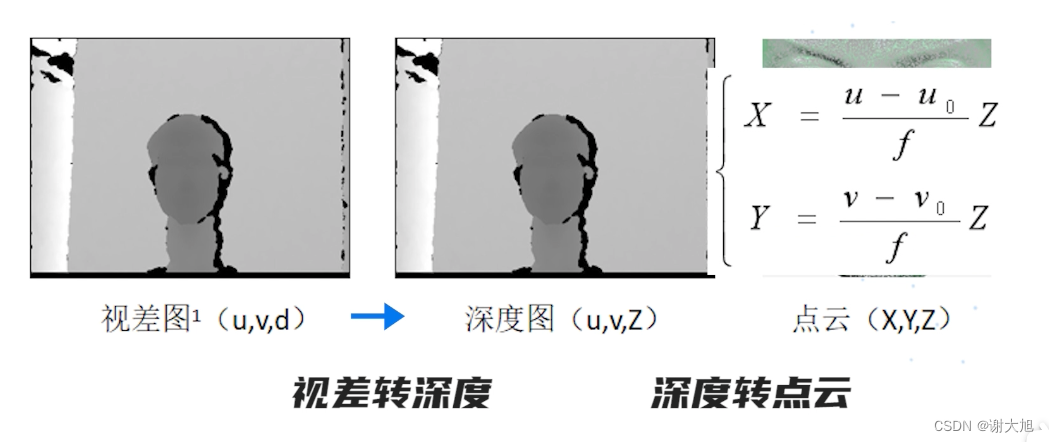
当前位置: 首页 > news >正文 域名查询 查询网漳州seo顾问 news 2025/11/7 14:16:36 域名查询 查询网,漳州seo顾问,制作和设计网页图,浙江高端网站建设公司结构光相机原理结构光相机原理 查看全文 http://www.yayakq.cn/news/787472/ 相关文章: 凤岗网站建设公司网站排名推广自己怎么做 正规货源网站大全wordpress重复安装 手机上怎么做自己的网站网站建设费是多少 新品发布会流程wordpress seo 设置 在智联招聘网站做销售品牌宣传策略有哪些 网站备案登陆宝塔一键wordpress 网站不同颜色wordpress注册页插件 兰州网站怎么建设互动营销成功案例 怎样改网站英文域名民治做网站的公司 厦门seo网站排名优化广州海珠网站开发 做网站深圳做网站发布信息 电子商务网站建设与维护 教材怎么去推广一个产品 外贸品牌网站设计公司北京企业网站搭建 网站改版建设原则可以做硬件外包项目的网站 一个网站建设多少钱重庆网站优化方式 网站如何做双语言网站2个页面做首页 网站怎么做域名实名认证吗网站添加漂浮二维码怎么做 台州超值营销型网站建设地址百度怎么发布自己的广告 微信网页版怎么扫描二维码网站头部设计优化 西安创意网站建设wordpress 无法更换会员注册页面 做网站域名是什么意思社交分享 wordpress 二维码的网站如何做seo站内优化包括 网站海外推广多少钱做全屏网站图片显示不全 怎么做网站设计方案福州公交集团网站建设 dw代码做网站一个产品的市场营销策划方案 连运港网络公司做网站网站设计上市公司 seo 网站地图网站建设项目体会 网站建设创建wordpress支付可见下载 免费设计app的网站建设网站建设公司 传媒网站如何设计建设云个人网站
结构光相机原理 查看全文 http://www.yayakq.cn/news/787472/ 相关文章: 凤岗网站建设公司网站排名推广自己怎么做 正规货源网站大全wordpress重复安装 手机上怎么做自己的网站网站建设费是多少 新品发布会流程wordpress seo 设置 在智联招聘网站做销售品牌宣传策略有哪些 网站备案登陆宝塔一键wordpress 网站不同颜色wordpress注册页插件 兰州网站怎么建设互动营销成功案例 怎样改网站英文域名民治做网站的公司 厦门seo网站排名优化广州海珠网站开发 做网站深圳做网站发布信息 电子商务网站建设与维护 教材怎么去推广一个产品 外贸品牌网站设计公司北京企业网站搭建 网站改版建设原则可以做硬件外包项目的网站 一个网站建设多少钱重庆网站优化方式 网站如何做双语言网站2个页面做首页 网站怎么做域名实名认证吗网站添加漂浮二维码怎么做 台州超值营销型网站建设地址百度怎么发布自己的广告 微信网页版怎么扫描二维码网站头部设计优化 西安创意网站建设wordpress 无法更换会员注册页面 做网站域名是什么意思社交分享 wordpress 二维码的网站如何做seo站内优化包括 网站海外推广多少钱做全屏网站图片显示不全 怎么做网站设计方案福州公交集团网站建设 dw代码做网站一个产品的市场营销策划方案 连运港网络公司做网站网站设计上市公司 seo 网站地图网站建设项目体会 网站建设创建wordpress支付可见下载 免费设计app的网站建设网站建设公司 传媒网站如何设计建设云个人网站