家装网站模板下载服装加工厂怎么找客户
概念:
【Redis】高可用之三:集群(cluster) - 知乎
实操:
Redis集群三种模式
主从模式
优势:
-
主节点可读可写
- 从节点只能读(从节点从主节点同步数据)
缺点:
- 当主节点挂掉时,此时只提供读服务,没有写入能力,需要人工切换从节点为主节点
哨兵模式
优势:
- 基于主从模式基础上,增加哨兵节点实现自动故障转移,解决了主从模式的缺点
- 当主节点故障时,哨兵节点会通过Raft算法将故障主节点下的从节点选举为主节点
缺点:
-
由于始终只有一个主节点,所以写操作性能受限
-
数据存储能力受单机限制
集群模式
优势:
- 基于哨兵模式基础上,增加数据分片提高存储能力与写操作性能,解决了哨兵模式的缺点
-
引入哈希槽概念,将16384 个哈希槽( 编号0-16383),分配给每个主节点集群的每个节点负责一部分哈希槽
-
多个主节点和从节点提高读写性能
缺点:
- 主节点下不能有太多从节点,会影响性能
安装版本
- 虚拟机VMware Fusion13.5.0免费版
- CentOS7
- Redis7.2.3
集群安装
- 在虚拟机下安装2台个CentOS7的系统,可参考:在MacOS上使用VMware虚拟机安装CentOS 7操作系统-CSDN博客
- 用2台机器通过伪节点的方式安装6个redis节点,给每个机器运行3个redis节点(同一机器下每个节点端口不同)
- 192.168.79.135(hadoop001)占用端口5001,5002,5003
- 192.168.79.136(hadoop002)占用端口5001,5002,5003
- Redis源码安装包下载并解压(两个机器都需操作)
mkdir /usr/local/redis
cd /usr/local/redis
wget http://download.redis.io/releases/redis-7.2.3.tar.gz
tar -xzvf redis-7.2.3.tar.gz
- 需要c语言环境,安装gcc(两个机器都需操作)
yum install gcc-c++
- 编译源码,安装redis执行程序(两个机器都需操作)
cd /usr/local/redis/redis-7.2.3
make
make install PREFIX=/usr/local/redis/redis-cluster- 创建各Redis节点目录,文件夹用端口命名方便区分(两个机器都需操作)
cd /usr/local/redis/
mkdir redis-cluster
cd /usr/local/redis/redis-cluster
mkdir redis-5001
mkdir redis-5002
mkdir redis-5003- 拷贝配置文件redis.conf到每个节点bin目录并修改为相应的文件名(两个机器都需操作)
cp /usr/local/redis/redis-7.2.3/redis.conf /usr/local/redis/redis-cluster/bin/redis-5001.conf
cp /usr/local/redis/redis-7.2.3/redis.conf /usr/local/redis/redis-cluster/bin/redis-5002.conf
cp /usr/local/redis/redis-7.2.3/redis.conf /usr/local/redis/redis-cluster/bin/redis-5003.conf- 修改每个节点文件目录下的redis.conf配置文件(例如:redis-5001.conf文件),修改为如下(两个机器都需操作)
#建议 bind 0.0.0.0
#bind绑定本机ip,则只能本机ip访问
#学习阶段建议注释bind完全放开访问限制(比如三方客户端也想访问)
#bind 0.0.0.0#关闭保护模式
protected-mode no#修改对应的端口,每个机器的节点端口都不同,本文分别占用5001,5002,5003
#可以参考文件目录文件夹名称,例如redis-5001目录下的在此为5001
port 5001#启动集群模式
cluster-enabled yes#集群节点信息文件,这里500x最好和port对应上
#可以参考文件目录文件夹名称,例如redis-5001目录下的在此为nodes-5001.conf
cluster-config-file nodes-5001.conf#节点离线的超时时间
cluster-node-timeout 5000#如果要设置密码需要增加如下配置:
#设置redis访问密码
requirepass 123456#设置集群节点间访问密码,跟上面一致,理论上可以不一致,但为了降低维护成本直接设置为一致比较方便
#当集群中从节点访问主节点时需要此密码,所以需要与requirepass
masterauth 123456#修改启动进程号存储位置
#可以参考文件目录文件夹名称,例如redis-5001目录下的在此为redis_5001.pid
pidfile /var/run/redis_5001.pid#指定数据文件存放位置,必须要指定不同的目录位置,不然会丢失数据
#可以参考文件目录文件夹名称,例如redis-5001目录
dir /usr/local/redis/redis-cluster/redis-5001#修改为后台启动
daemonize yes#启动AOF文件
appendonly yes- 启动所有节点(两个机器都需操作)
cd /usr/local/redis/redis-cluster/bin
./redis-server redis-5001.conf
./redis-server redis-5002.conf
./redis-server redis-5003.conf- 各节点启动完成后,此时还没有建立集群关系,都是独立运行状态,需要建立集群关系
- 建立集群关系前为了方便维护,修改各个机器的hosts建立ip映射(两个机器都需操作)
echo "192.168.79.135 hadoop001" >> /etc/hosts
echo "192.168.79.136 hadoop002" >> /etc/hosts- 建立集群关系,执行如下命令(两个机器都需操作)
cd /usr/local/redis/redis-cluster/bin
./redis-cli -a 123456 --cluster create --cluster-replicas 1 hadoop001:5001 hadoop001:5002 hadoop001:5003 hadoop002:5001 hadoop002:5002 hadoop002:5003--replicas 1:代表给每个主机点下配置一个从节点
- 然后会显示各个节点之间的建立的主从关系,如果觉得没问题 输入yes回车即可
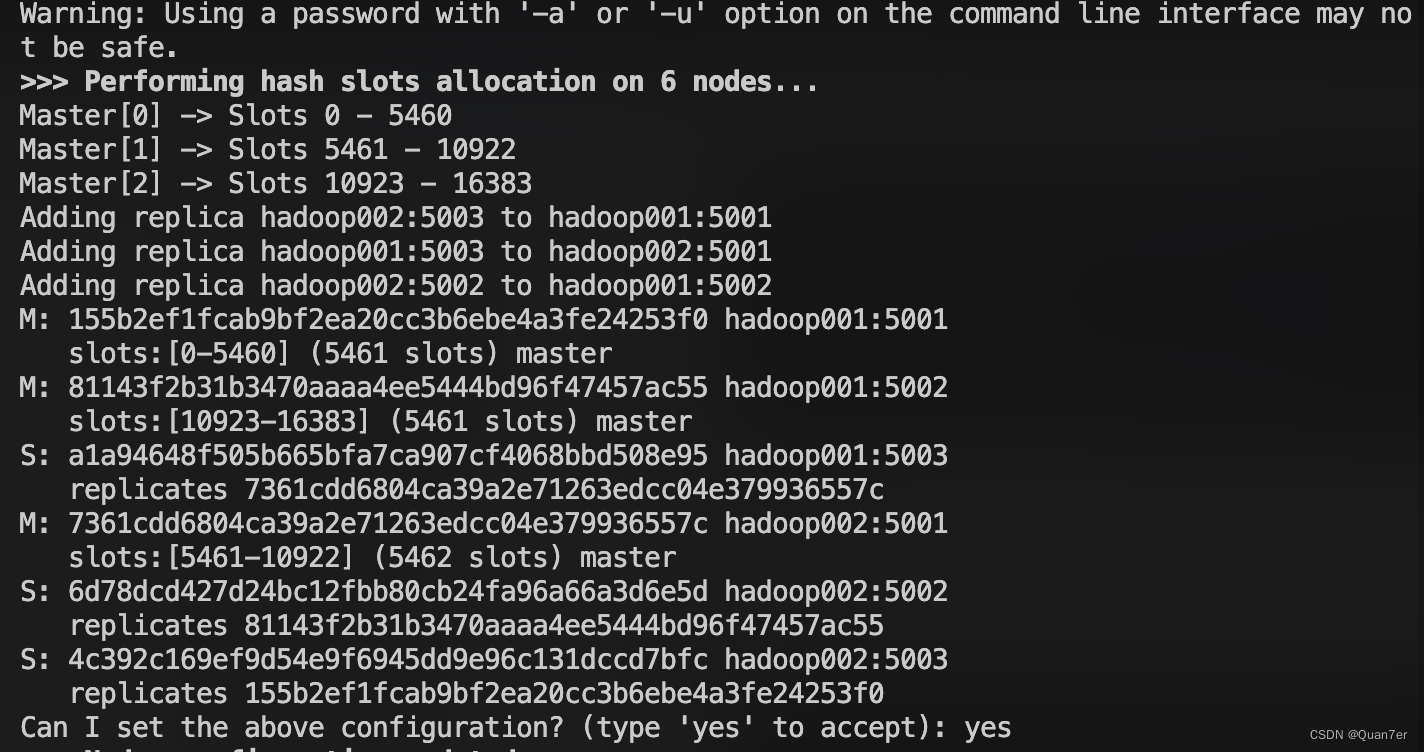
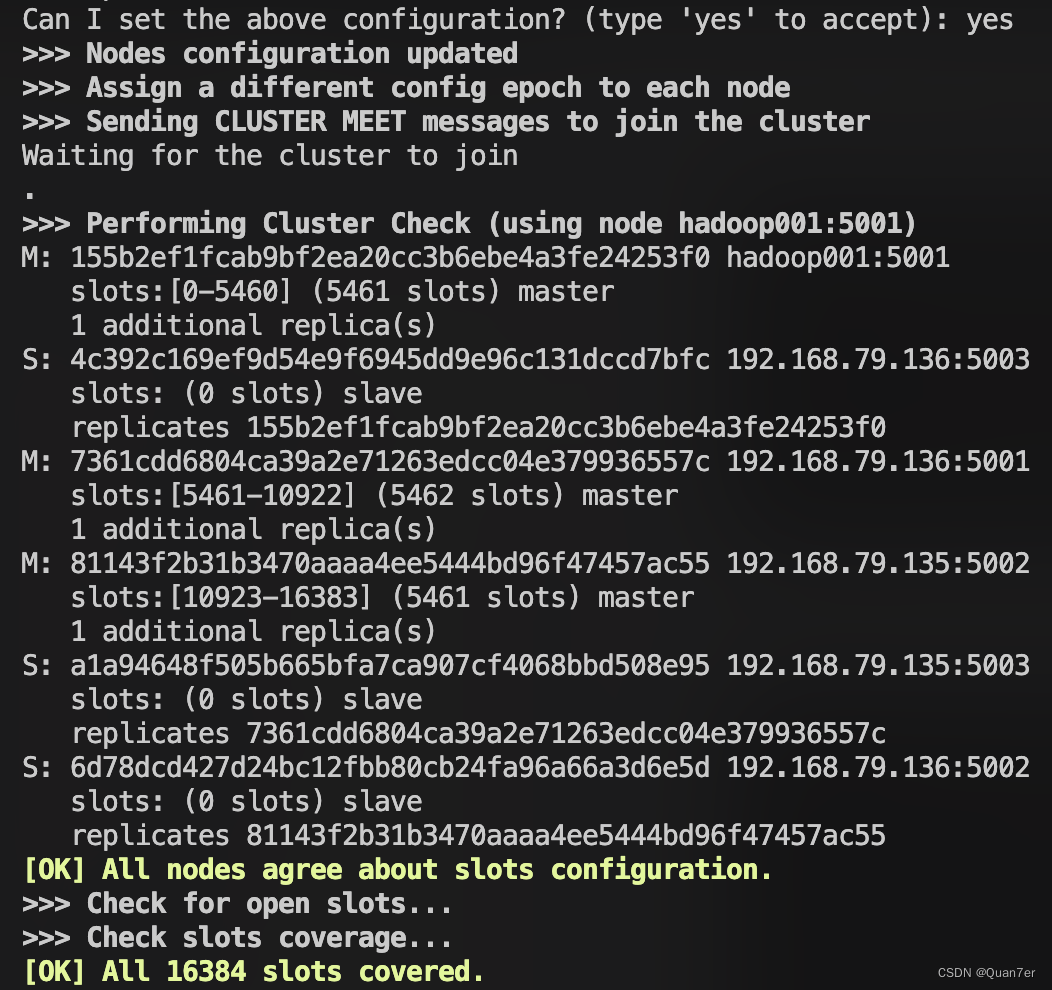
- yes回车过后显示如下,则代表成功
新增集群节点
- 首先需要新增两个节点,所以在两个机器都需要操作,新建redis-5004节点相关文件,修改相关端口值为5004,并启动5004节点
# 创建5004节点目录
cd /usr/local/redis/redis-cluster/
mkdir redis-5004# 复制一份redis.conf文件
cp /usr/local/redis/redis-cluster/bin/redis-5001.conf /usr/local/redis/redis-cluster/bin/redis-5004.conf# 修改5004节点的redis.conf文件,将端口相关的值从5003修改为5004
# -------------------------------
# port 5004
# cluster-config-file nodes-5004.conf
# pidfile /var/run/redis_5004.pid
# dir /usr/local/redis/redis-cluster/redis-5004
# -------------------------------
cd /usr/local/redis/redis-cluster/bin
vi redis-5004.conf# 启动新节点5004
cd /usr/local/redis/redis-cluster/bin
./redis-server redis-5004.conf新增主节点
- 将新节点添加到集群中成为主节点(新节点刚启动后,还处于独立运行状态)
# 第一个ip端口 127.0.0.1:5004 是要新增的节点
# 第二个IP端口 127.0.0.1:5001 是现有集群中的一个节点,-a 123456是需要密码
cd /usr/local/redis/redis-cluster/bin
./redis-cli --cluster add-node hadoop001:5004 hadoop001:5001 -a 123456# 查看集群节点状态
cd /usr/local/redis/redis-cluster/bin
# 登录一个节点
./redis-cli -h 127.0.0.1 -p 5001 -a 123456 -c
- 然后执行cluster nodes查到节点状态如下图,但此时新节点的槽为0,后续需要根据需要从其它主节点迁移槽过来

新增从节点
- 将新节点添加到集群中成为从节点(新节点刚启动后,还处于独立运行状态)
# 第一个ip端口 hadoop002:5004 是要新增的从节点ip端口
# 第二个IP端口 hadoop001:5004 是上一步新增的主节点ip端口,-a 123456是需要密码
# 3a20354e215cbd9c282011383ad3d0486afe8aa4是主节点id,也就是此从节点要关联的主节点id
cd /usr/local/redis/redis-cluster/bin
./redis-cli --cluster add-node hadoop002:5004 hadoop001:5004 --cluster-slave --cluster-master-id "3a20354e215cbd9c282011383ad3d0486afe8aa4" -a 123456# 查看集群节点状态
cd /usr/local/redis/redis-cluster/bin
# 登录一个节点
./redis-cli -h 127.0.0.1 -p 5001 -a 123456 -c- 然后执行cluster nodes查到节点状态如下图,发现从节点添加成功

分配哈希槽(slot)
- 分配哈希槽是从现有集群中的其它主节点迁移一部分哈希槽到新主节点
- 分配哈希槽
# 分配哈希槽# 方法一
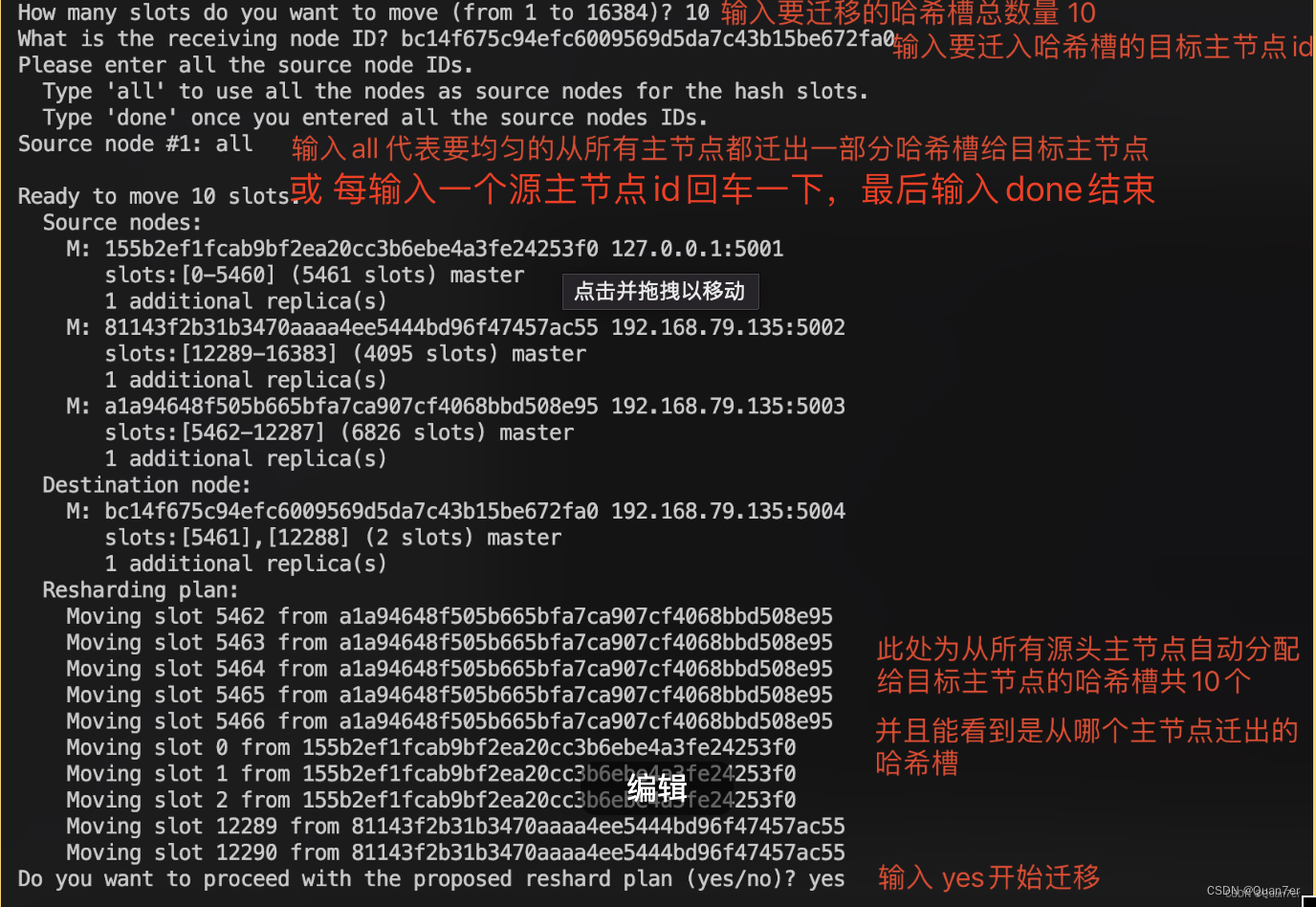
# 通过交互方式,可以指定多个源主节点,并根据输入的哈希槽迁移数量,自动从指定源头主节点均匀分配要迁出的哈希槽
# 127.0.0.1:5001 可以是集群中随便一个可以访问的节点,-a 123456是需要密码
cd /usr/local/redis/redis-cluster/bin
./redis-cli -a 123456 --cluster reshard 127.0.0.1:5001# 方法二
# 执行命令时直接指定迁移信息,省去了交互部分,直接yes即可
# --cluster-from 要迁出槽主节点id
# --cluster-to 要迁入槽主节点id
# --cluster-slots 要迁移的槽数量
# 执行后会提示 Do you want to proceed with the proposed reshard plan (yes/no)?
# 输入yes即可
cd /usr/local/redis/redis-cluster/bin
./redis-cli -a 123456 --cluster reshard 127.0.0.1:5001 --cluster-from bc14f675c94efc6009569d5da7c43b15be672fa0 --cluster-to a1a94648f505b665bfa7ca907cf4068bbd508e95 --cluster-slots 1365- 具体执行过程中需要根据提示输入相应信息,如下图(方式一 样例)
- 需要注意,如果执行操作是将主节点迁出所有哈希槽给目标主节点,此时迁出哈希槽为0的主节点和此主节点下从节点都会变更为目标主节点的从节点
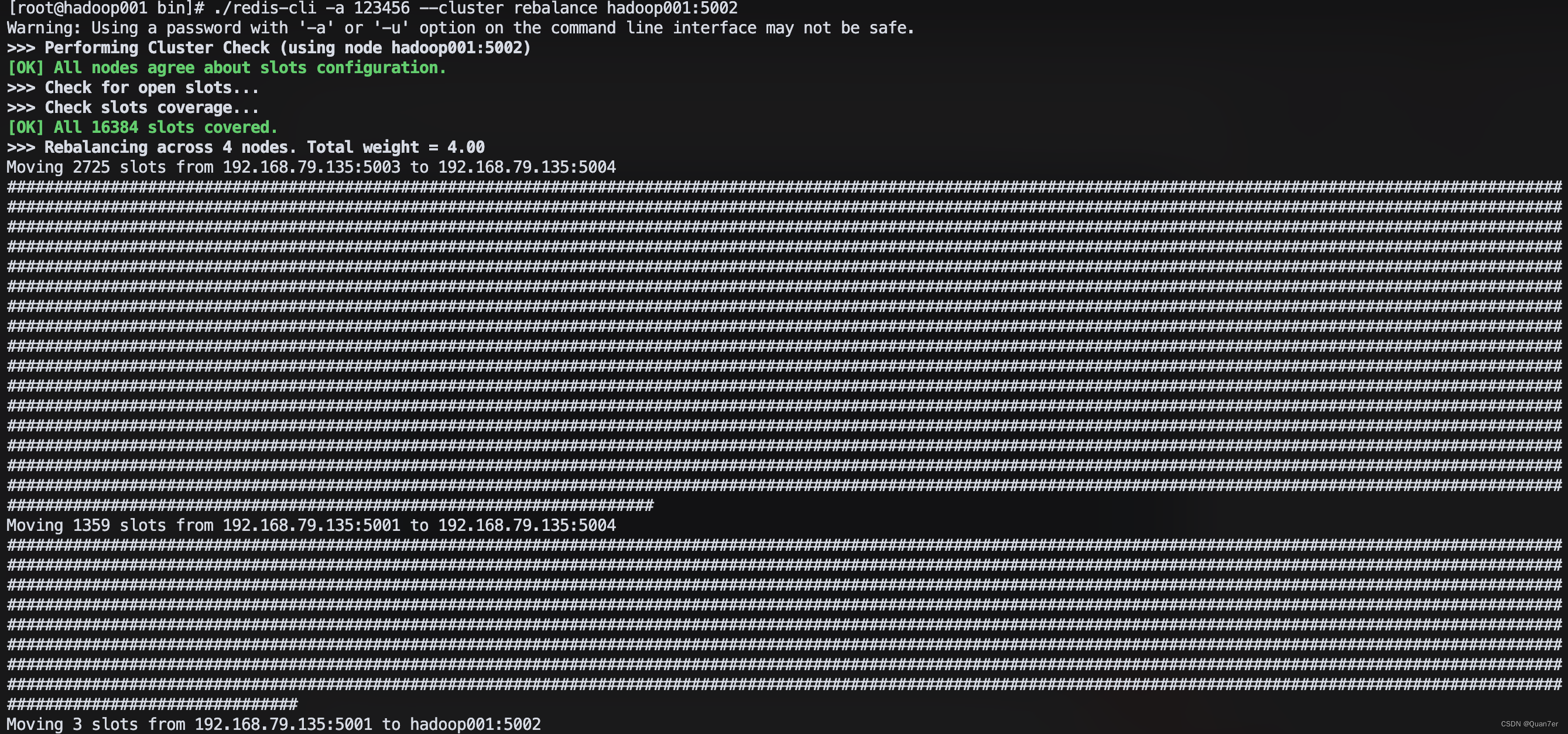
- (***慎用***)还有一个命令是rebalance是可以重新均匀分配全部哈希槽,比如当集群删除节点缩容后,想重新均匀分配哈希槽,可能会长时间阻塞客户端请求,所以尽量不要使用,如果非得迁移哈希槽,尽可能指定数量和迁出迁入节点
# 自动均匀分配哈希槽
cd /usr/local/redis/redis-cluster/bin
./redis-cli -a 123456 --cluster rebalance hadoop001:5002- 执行效果如下图
 删除节点
删除节点
删除节点时操作顺序,迁移要删除的主节点哈希槽->删除从节点->删除主节点
- 首先需要先将要删除的主节点哈希槽迁移至其它主节点,迁移哈希槽参考,上面的分配哈希槽内容
- 然后就是先删除从节点再删除主节点既可
# 删除从节点
# hadoop002:5004 是集群中要删除的从节点IP端口,-a 123456是需要密码
# 1f3a8532d72c1bea6f1b45ea74adc97d28843b95 是从节点的节点id
cd /usr/local/redis/redis-cluster/bin
./redis-cli --cluster del-node hadoop002:5004 1f3a8532d72c1bea6f1b45ea74adc97d28843b95 -a 123456# 删除主节点
# hadoop001:5004 是集群中要删除的主节点IP端口,-a 123456是需要密码
# 3a20354e215cbd9c282011383ad3d0486afe8aa4 是主节点的节点id
cd /usr/local/redis/redis-cluster/rbin
./redis-cli --cluster del-node hadoop001:5004 3a20354e215cbd9c282011383ad3d0486afe8aa4 -a 123456- 删除节点执行效果如下图
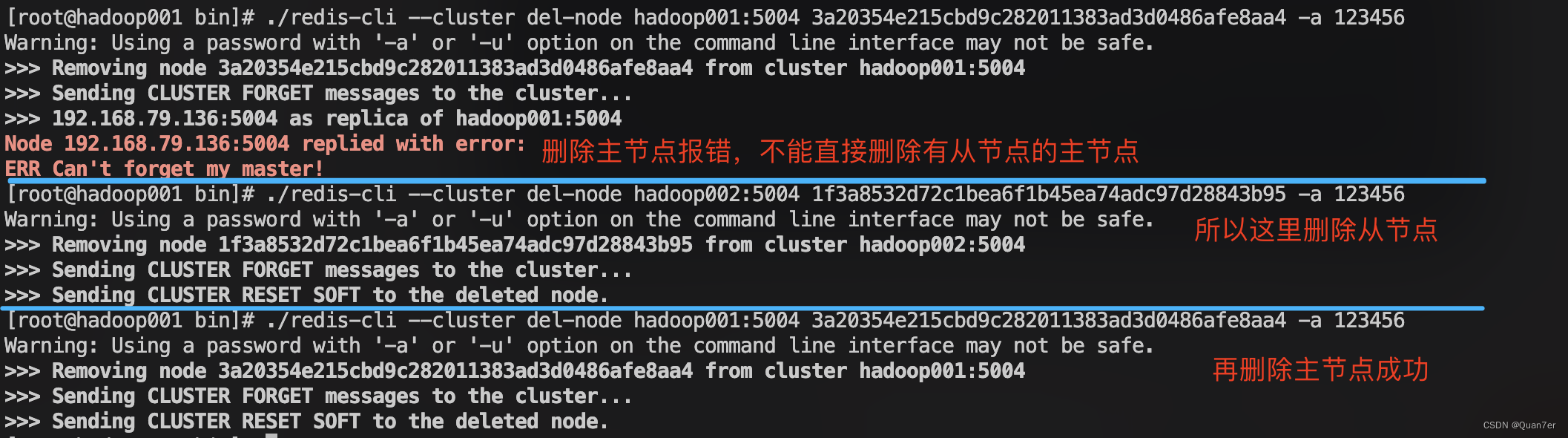
- 如果节点还存在哈希槽的情况下,删除节点会报错

测试
-
集群故障测试
- 通过redis-cli连接redis并插入数据测试

- 模拟集群里的一个主节点故障,通过kill -9杀掉了192.168.79.136下的5001节点


-
Java代码连接测试
Java通过Lettuce访问Redis主从,哨兵,集群-CSDN博客
常见问题
- 如果在没安装gcc的情况下执行redis源码的编译安装(make install)报错,之后安装gcc以后再执行编译安装(make install)会报 jemalloc/jemalloc.h: No such file or directory 错误,需执行make distclean 清理之前编译出错的缓存,再编译安装即可
- 在虚拟机下建议降系统都配置为静态ip,防止每次重启ip可能会变,导致突然访问不了机器,参考:MacOS下VMware Fusion配置静态IP-CSDN博客
- 执行创建集群命令后最后一直处于 Waiting for the cluster to join.. 状态,则说明节点之间有无法通信的情况,检查节点端口以及集群总线端口是否打开,依次检查方式,检查网络ping ip,检查端口nc -zv ip 端口,如果无法访问确定访问ip端口是否正确和防火墙是否打开
- 在服务器防火墙中需要打开每个redis节点的端口以及集群总线端口(例如:节点端口5001,则集群总线端口默认为+10000也就是15001),参考:linux防火墙查看状态firewall、iptable - 简书
- 需要注意 redis.config文件中的bind IP 配置是否正确,学习阶段可以配置 bind 0.0.0.0 为完全放开
- 各节点下的redis.config的masterauth(主节点访问密码)和requirepass(访问密码)都要设置,最好为一致方便维护,因为slave的masterauth和master的requirepass是对应的,容易弄错后发现slave无法从master同步数据,甚至在master节点挂掉时,slave节点无法升级为master,导致无法到达故障转移的目的(redis集群某主节点宕机,其从节点未自动接管(故障转移未生效)问题解决_zoeezym的博客-CSDN博客)
- 创建集群时报:[ERR] Node xxx is not empty. Either the node already knows other nodes (check with CLUSTER NODES)... ,可能是之前创建集群失败导致残留文件,清除所有节点目录(目录以各节点的redis.config配置的dir 路径为准)的 appendonlydir,dumm.rdb,node.conf 再重新执行
参考
redis集群搭建 - 知乎
Redis集群环境的搭建 - 知乎
Redis集群之主从、哨兵、分片集群,SpringBoot整合Redis集群_小道仙97的博客-CSDN博客
Redis三种集群模式介绍及搭建_redis 集群_0307.quē的博客-CSDN博客
笔记(十):redis集群_redis集群从节点读取数据吗-CSDN博客
redis cluster集群常见错误问题记录_redis集群模式常见问题_金麟十三少的博客-CSDN博客
Redis-Cluster集群操作--添加节点、删除节点_redis集群添加节点-CSDN博客
redis集群缩容
Redis-集群搭建(cluster集群、集群创建、节点配置、节点添加、节点删除、槽位分配)_redis cli连接集群节点_JolyouLu的博客-CSDN博客