WebSocket 作为实时通信的利器,越来越受到开发者的青睐。然而,为了确保通信的安全性和合法性,鉴权成为不可或缺的一环。本文将深入探讨 WebSocket 的鉴权机制,为你呈现一揽子的解决方案,确保你的 WebSocket 通信得心应手。
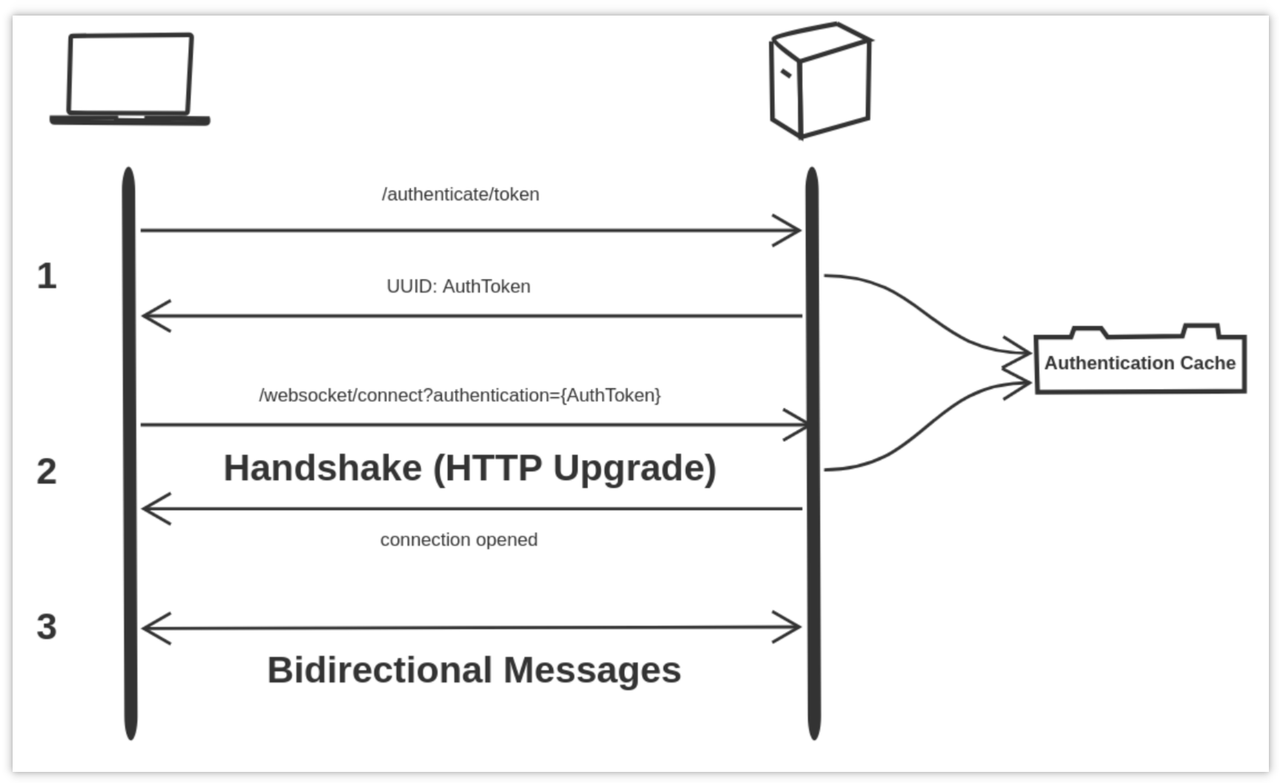
使用场景
WebSocket 鉴权在许多场景中都显得尤为重要。例如,实时聊天应用、在线协作工具、实时数据更新等情境都需要对 WebSocket 进行鉴权,以确保只有合法的用户或服务可以进行通信。通过本文的指导,你将更好地了解在何种场景下使用 WebSocket 鉴权是有意义的。
WebSocket 调试工具
要调试 WebSocket,那就需要一个好的调试工具,这里我比较推荐 Apifox。它支持调试 http(s)、WebSocket、Socket、gRPC、Dubbo 等多种协议的接口,这使得它成为了一个非常全面的接口测试工具!
常见方法
方法 1:基于 Token 的鉴权
WebSocket 鉴权中,基于 Token 的方式是最为常见和灵活的一种。通过在连接时携带 Token,服务器可以验证用户的身份。以下是一个简单的示例:
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 | const WebSocket = require('ws');
const server = new WebSocket.Server({ port: 3000 });
server.on('connection', (socket, req) => {
const token = req.headers['sec-websocket-protocol'];
// 验证token的合法性
if (isValidToken(token)) {
// 鉴权通过,进行后续操作
socket.send('鉴权通过,欢迎连接!');
} else {
// 鉴权失败,关闭连接
socket.close();
}
});
|
方法 2:基于签名的鉴权
另一种常见的鉴权方式是基于签名的方法。通过在连接时发送带有签名的信息,服务器验证签名的合法性。以下是一个简单的示例:
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 | const WebSocket = require('ws');
const crypto = require('crypto');
const server = new WebSocket.Server({ port: 3000 });
server.on('connection', (socket, req) => {
const signature = req.headers['x-signature'];
const data = req.url + req.headers['sec-websocket-key'];
// 验证签名的合法性
if (isValidSignature(signature, data)) {
// 鉴权通过,进行后续操作
socket.send('鉴权通过,欢迎连接!');
} else {
// 鉴权失败,关闭连接
socket.close();
}
});
|
方法 3:基于 IP 白名单的鉴权
在某些情况下,你可能希望限制 WebSocket 连接只能来自特定 IP 地址范围。这时可以使用基于 IP 白名单的鉴权方式。
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 | const WebSocket = require('ws');
const allowedIPs = ['192.168.0.1', '10.0.0.2'];
const server = new WebSocket.Server({ port: 3000 });
server.on('connection', (socket, req) => {
const clientIP = req.connection.remoteAddress;
// 验证连接是否在白名单中
if (allowedIPs.includes(clientIP)) {
// 鉴权通过,进行后续操作
socket.send('鉴权通过,欢迎连接!');
} else {
// 鉴权失败,关闭连接
socket.close();
}
});
|
方法 4:基于 OAuth 认证的鉴权
在需要与现有身份验证系统集成时,OAuth 认证是一种常见的选择。通过在连接时使用 OAuth 令牌,服务器可以验证用户的身份。
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 | const WebSocket = require('ws');
const axios = require('axios');
const server = new WebSocket.Server({ port: 3000 });
server.on('connection', async (socket, req) => {
const accessToken = req.headers['authorization'];
// 验证OAuth令牌的合法性
try {
const response = await axios.get('https://oauth-provider.com/verify', {
headers: { Authorization: `Bearer ${accessToken}` }
});
if (response.data.valid) {
// 鉴权通过,进行后续操作
socket.send('鉴权通过,欢迎连接!');
} else {
// 鉴权失败,关闭连接
socket.close();
}
} catch (error) {
// 验证失败,关闭连接
socket.close();
}
});
|
其他常见方法...
除了以上介绍的方式,还有一些其他的鉴权方法,如基于 API 密钥、HTTP 基本认证等。根据具体需求,选择最适合项目的方式。
实践案例
基于 Token 的鉴权实践
- 在 WebSocket 连接时,客户端携带 Token 信息。
- 服务器接收 Token 信息并验证其合法性。
- 根据验证结果,允许或拒绝连接。
| 1 2 | // 客户端代码
const socket = new WebSocket('ws://localhost:3000', ['Bearer YOUR_TOKEN']);
|
| 1 2 3 4 5 6 7 8 9 10 | // 服务器端代码
server.on('connection', (socket, req) => {
const token = req.headers['sec-websocket-protocol'];
if (isValidToken(token)) {
socket.send('鉴权通过,欢迎连接!');
} else {
socket.close();
}
});
|
基于签名的鉴权实践
- 在 WebSocket 连接时,客户端计算签名并携带至服务器。
- 服务器接收签名信息,验证其合法性。
- 根据验证结果,允许或拒绝连接。
| 1 2 | // 客户端代码
const socket = new WebSocket('ws://localhost:3000', { headers: { 'X-Signature': calculateSignature() } });
|
| 1 2 3 4 5 6 7 8 9 10 11 | // 服务器端代码
server.on('connection', (socket, req) => {
const signature = req.headers['x-signature'];
const data = req.url + req.headers['sec-websocket-key'];
if (isValidSignature(signature, data)) {
socket.send('鉴权通过,欢迎连接!');
} else {
socket.close();
}
});
|
基于 IP 白名单的鉴权实践
- 在 WebSocket 连接时,服务器获取客户端 IP 地址。
- 验证 IP 地址是否在白名单中。
- 根据验证结果,允许或拒绝连接。
| 1 2 3 4 5 6 7 8 9 10 | // 服务器端代码
server.on('connection', (socket, req) => {
const clientIP = req.connection.remoteAddress;
if (allowedIPs.includes(clientIP)) {
socket.send('鉴权通过,欢迎连接!');
} else {
socket.close();
}
});
|
基于 OAuth 认证的鉴权实践
- 在 WebSocket 连接时,客户端携带 OAuth 令牌。
- 服务器调用 OAuth 服务验证令牌的合法性。
- 根据验证结果,允许或拒绝连接。
| 1 2 | // 客户端代码
const socket = new WebSocket('ws://localhost:3000', { headers: { 'Authorization': 'Bearer YOUR_ACCESS_TOKEN' } });
|
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 | // 服务器端代码
server.on('connection', async (socket, req) => {
const accessToken = req.headers['authorization'];
try {
const response = await axios.get('https://oauth-provider.com/verify', {
headers: { Authorization: `Bearer ${accessToken}` }
});
if (response.data.valid) {
socket.send('鉴权通过,欢迎连接!');
} else {
socket.close();
}
} catch (error) {
socket.close();
}
});
|
提示、技巧和注意事项
- 在选择鉴权方式时,要根据项目的实际需求和安全性要求进行合理选择。
- 对于基于 Token 的鉴权,建议使用 JWT(JSON Web Token)来提高安全性。
- 在验证失败时,及时关闭连接,以防止未授权的访问。
在 Apifox 中调试 WebSocket
如果你要调试 WebSocket 接口,并确保你的应用程序能够正常工作。这时,一个强大的接口测试工具就会派上用场。
Apifox 是一个比 Postman 更强大的接口测试工具,Apifox = Postman + Swagger + Mock + JMeter。它支持调试 http(s)、WebSocket、Socket、gRPC、Dubbo 等多种协议的接口,这使得它成为了一个非常全面的接口测试工具,所以强烈推荐去下载体验!
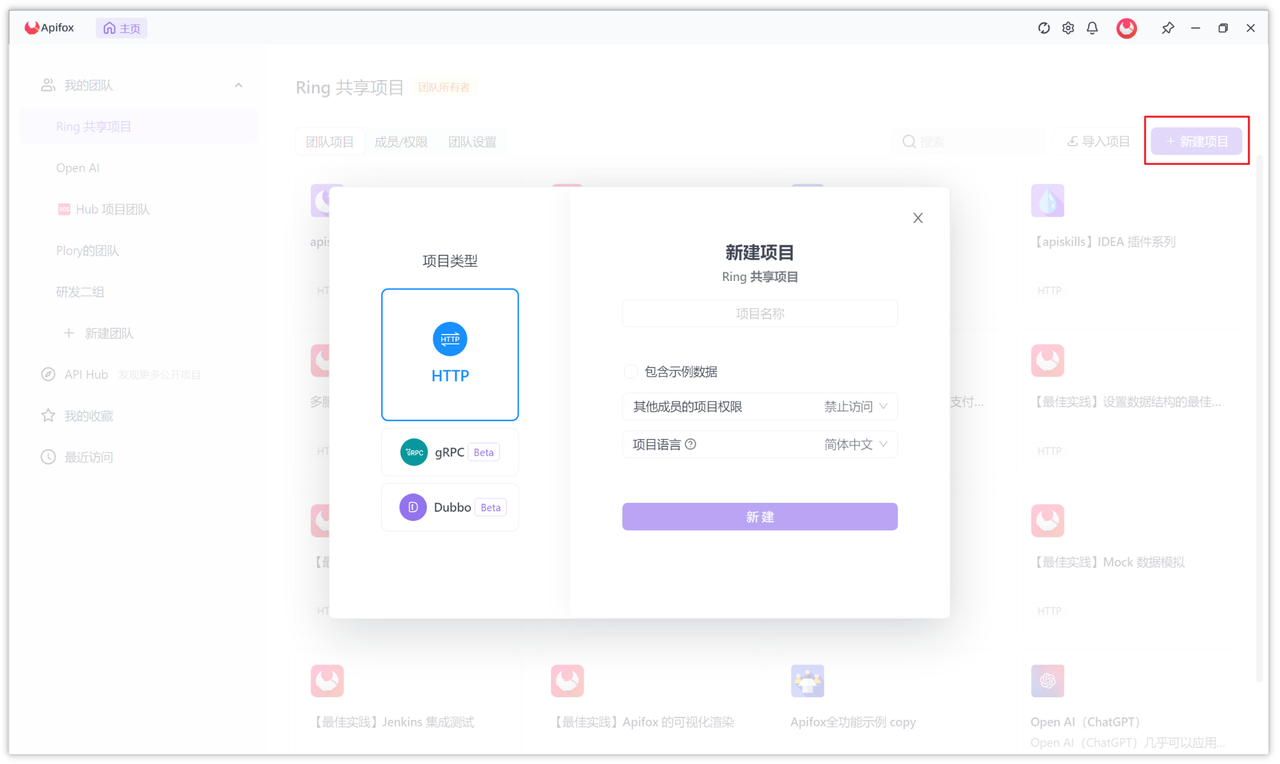
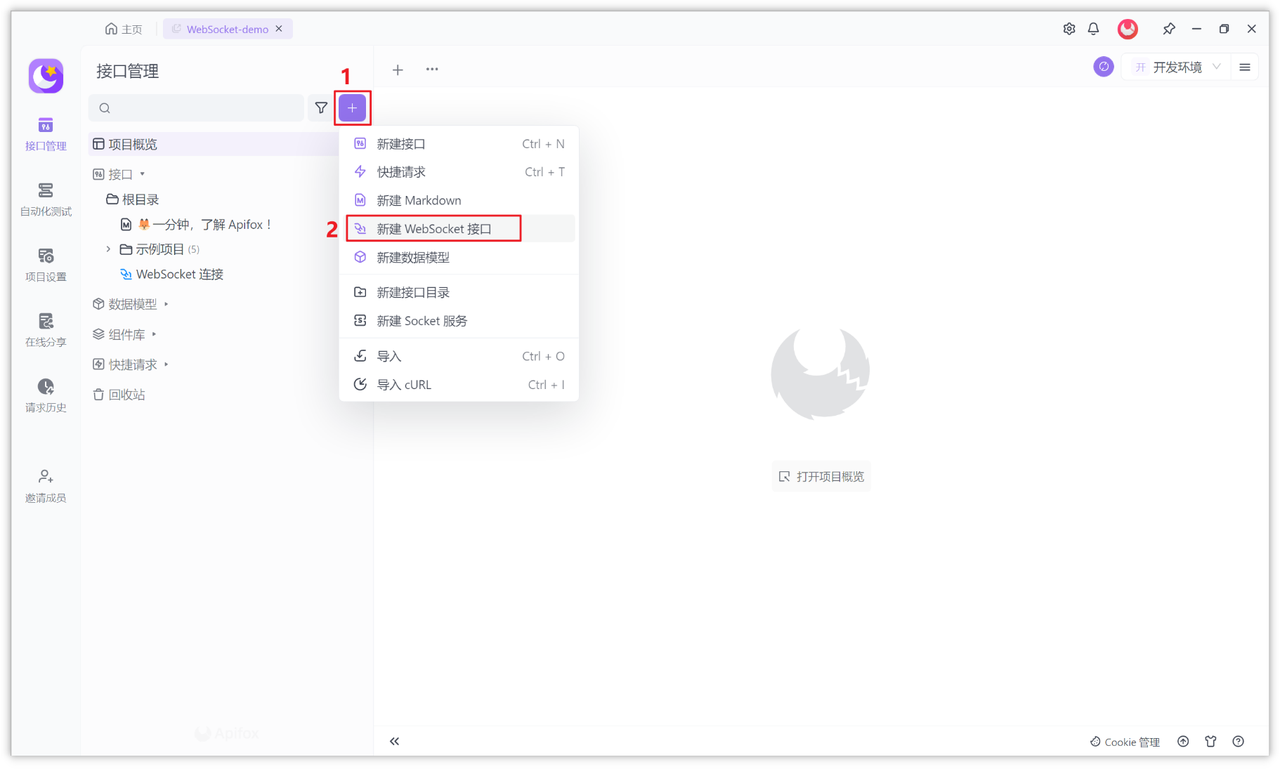
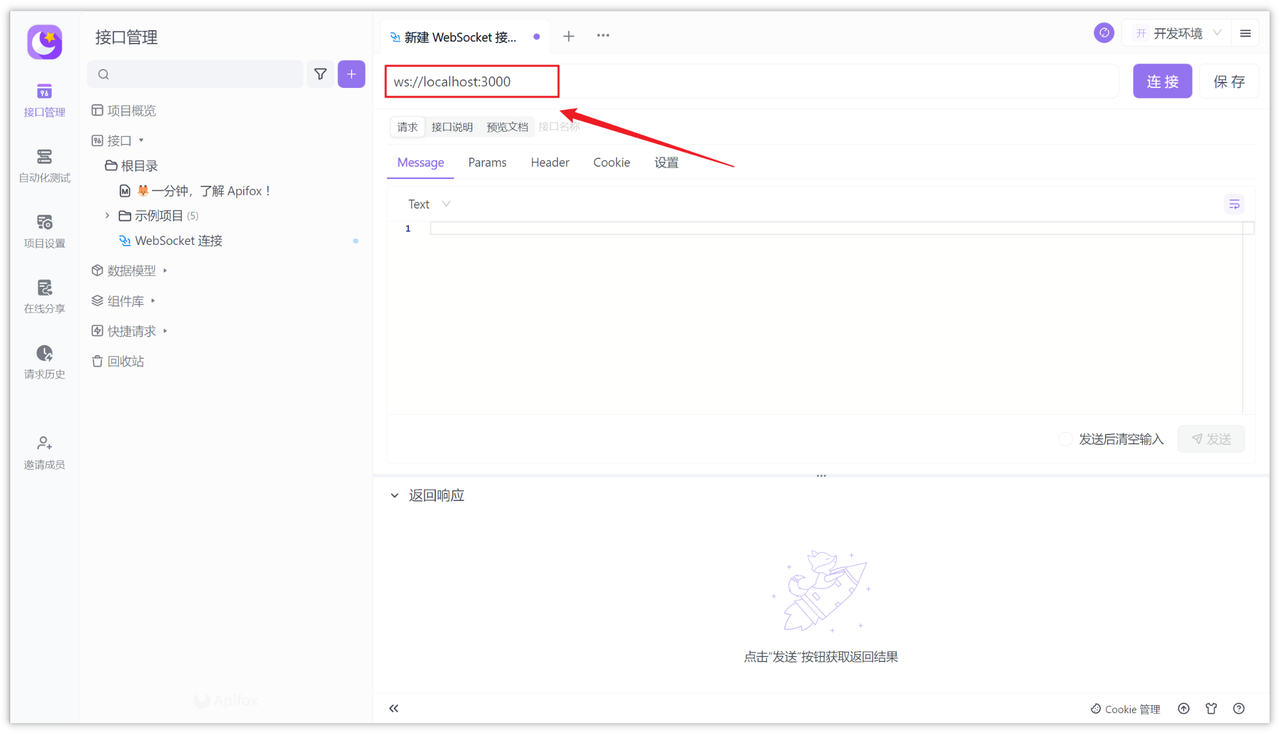
首先在 Apifox 中新建一个 HTTP 项目,然后在项目中添加 WebSocket 接口。
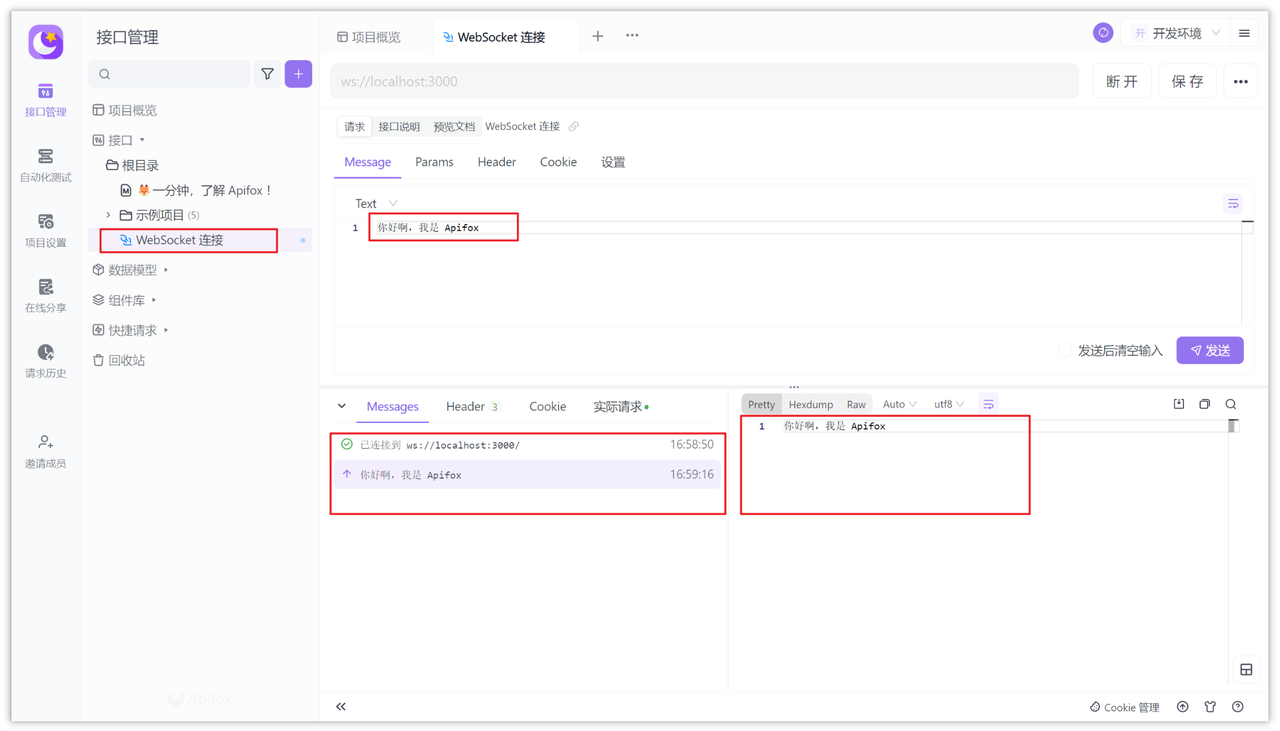
接着输入 WebSocket 的服务端 URL,例如:ws://localhost:3000,然后保存并填写接口名称,然后确定即可。
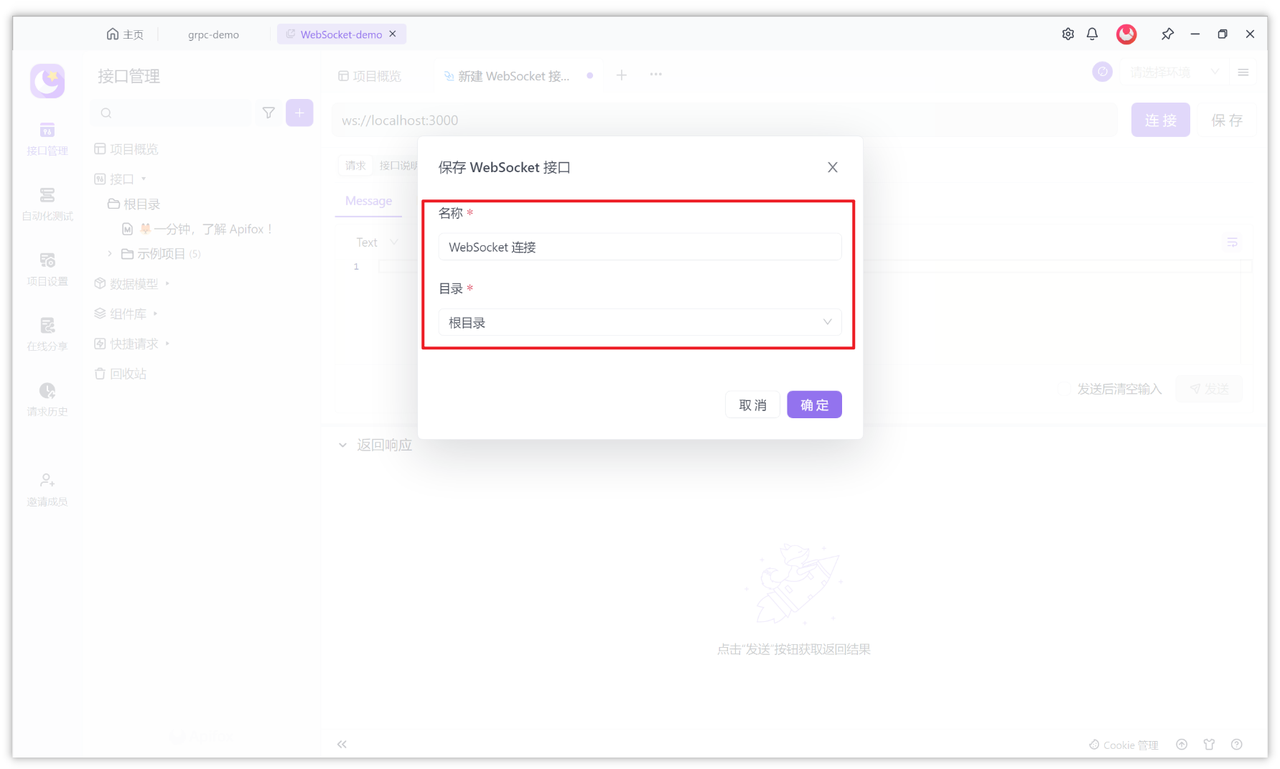
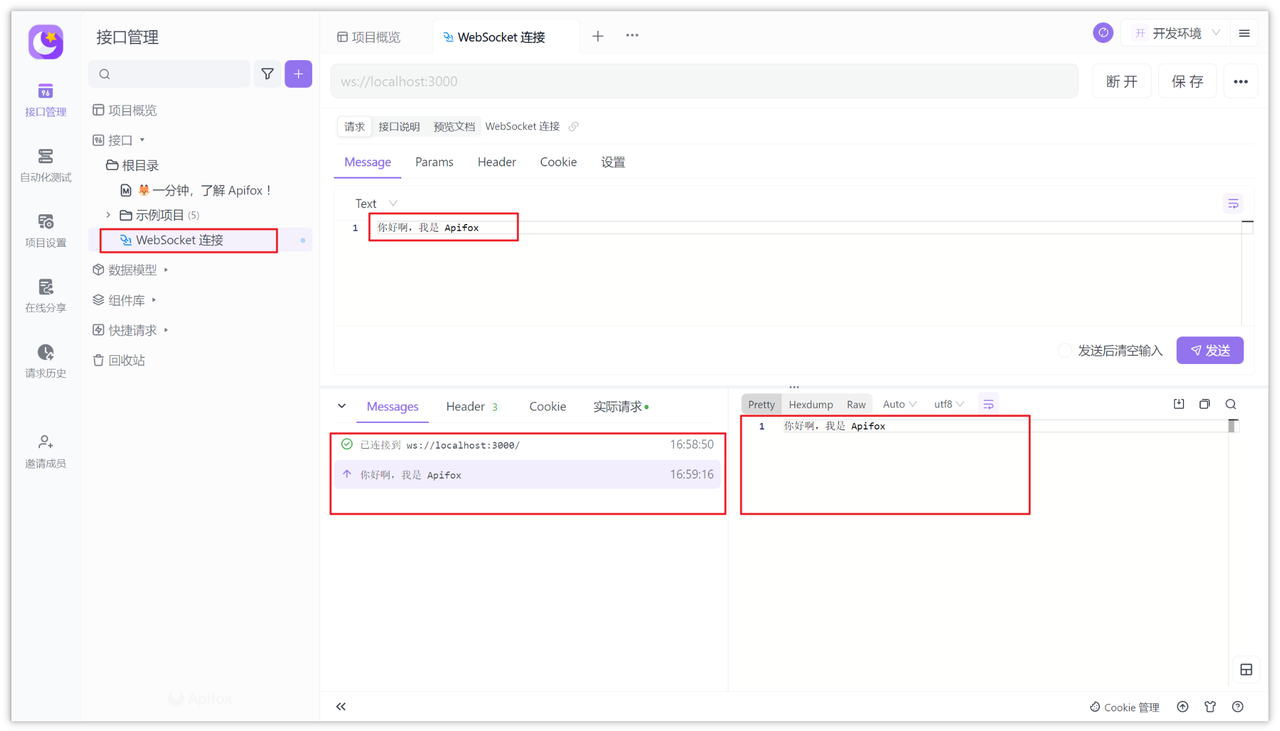
点击“Message 选项”然后写入“你好啊,我是 Apifox”,然后点击发送,你会看到服务端和其它客户端都接收到了信息,非常方便,快去试试吧!
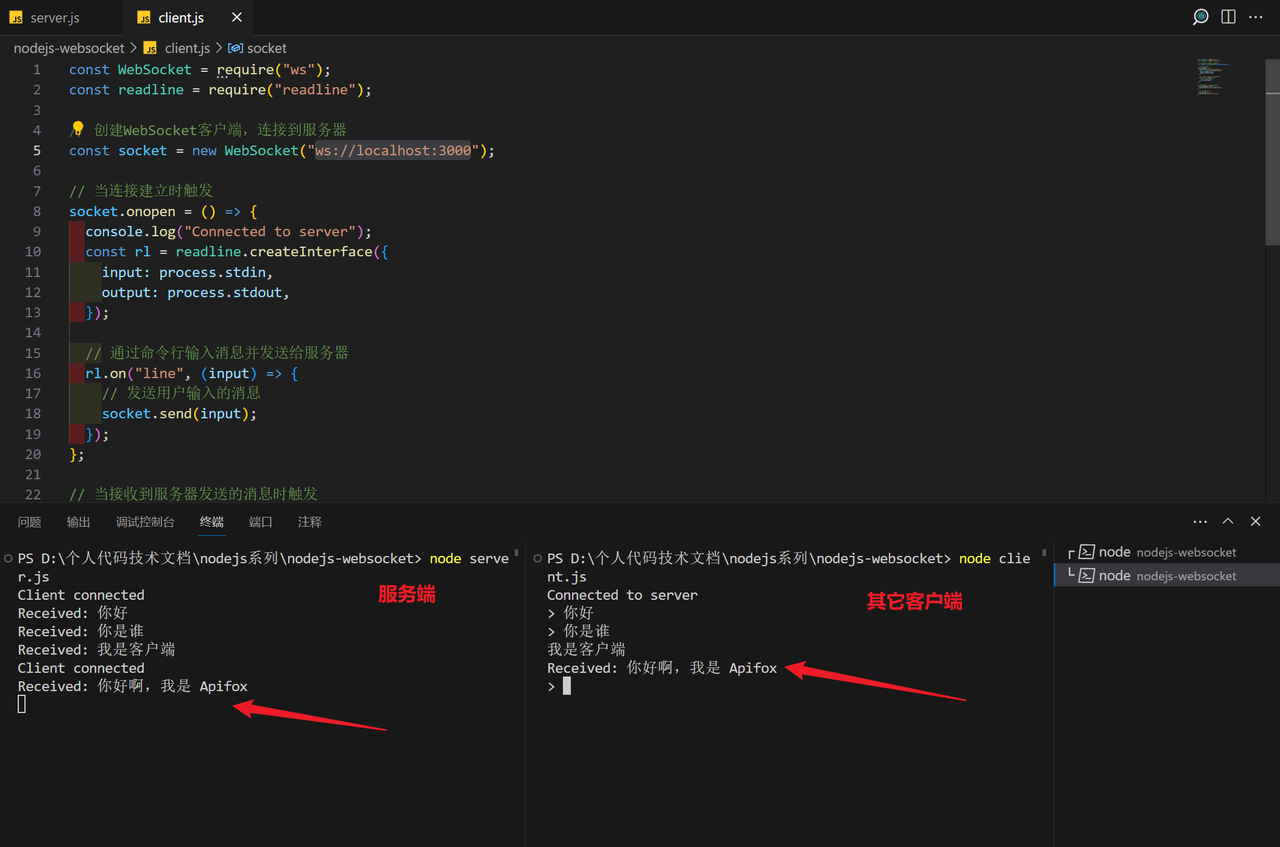
以下用 Node.js 写的 WebSocket 服务端和客户端均收到了消息。
总结
通过本文的介绍,你应该对 WebSocket 鉴权有了更清晰的认识。不同的鉴权方式各有优劣,你可以根据具体情况选择最适合自己项目的方式。在保障通信安全的同时,也能提供更好的用户体验。
参考链接
- MDN Web Docs - WebSocket
- JSON Web Tokens
- OAuth 2.0
学习更多: