百度如何把网站做链接建立大数据平台
文章目录
- 操作系统和shell外壳
- Linux用户
- 普通用户的创建和删除
- 用户的切换
- Linux 权限
- Linux 权限分类
- 文件访问权限
- 修改文件的权限
- 权限掩码
- 粘滞位
大家好,我是纪宁。
这篇文章将介绍 Linux的shell外壳程序,Linux用户切换机Linux权限的内容。
操作系统和shell外壳
Linux严格意义上说的是一个操作系统,我们称之为“核心(kernel)“ ,但我们一般用户,不能直接使用kernel。
而是通过kernel的“外壳”程序,也就是所谓的shell。
Linux用户态与内核态图
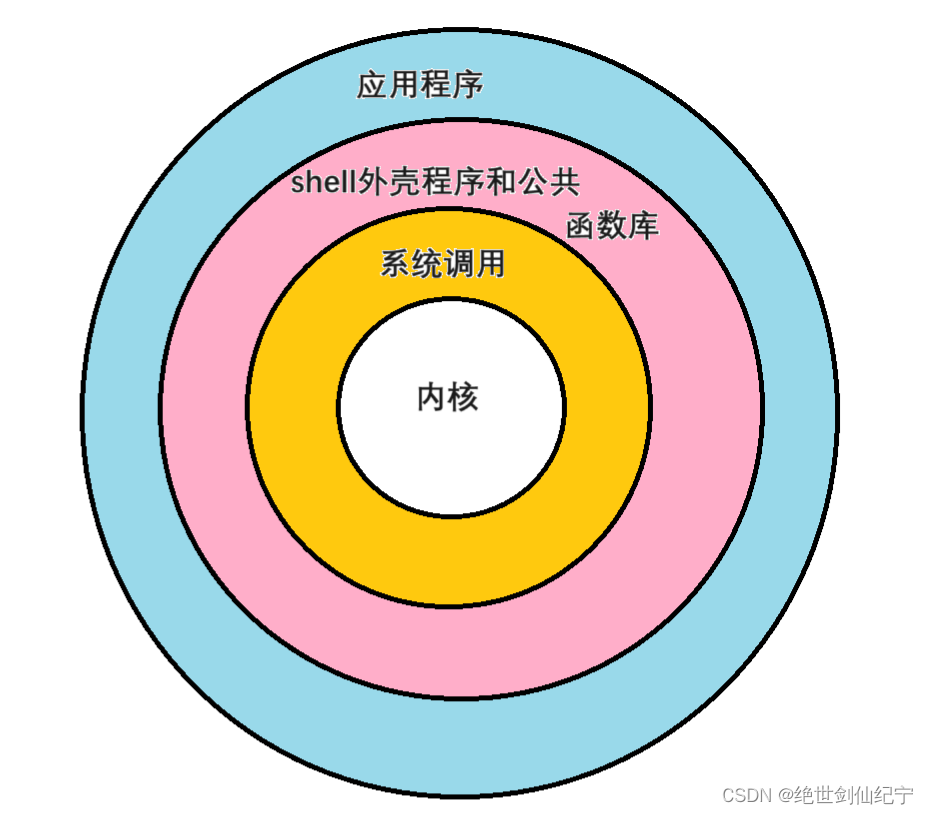
操作系统内核和shell外壳是两个不同的组件,但它们之间有密切的关系。
操作系统内核是操作系统的核心部分,它管理计算机硬件和软件资源,并提供计算机系统的基本服务,如进程管理、内存管理、I/O管理、文件系统等。操作系统内核是操作系统的基石,没有它,操作系统无法正常运行。
Shell外壳是用户与操作系统内核交互的主要接口。Shell可以理解为命令解释器,它接受用户输入的命令,并调用相应的内核服务执行。Shell提供了一组命令和脚本语言,可以让用户方便地访问操作系统内核的服务和操作文件系统等资源。
在操作系统中,Shell作为系统用户和内核的一个交互接口,通过命令行或图形界面的形式传递用户的请求和指令,内核接收到指令后,执行相应的操作,并把结果返回给Shell。Shell与内核之间的交互可以通过系统调用实现。
那么总结shell外壳的作用是:将使用者的命令翻译给内核并进行处理,同时将内核的处理结果翻译给使用者。
shell外壳一定会对用户输入的指令做处理吗?
答案是不一定的。为了操作系统的安全性及易用性考虑,用户要通过shell程序输入指令,而不是直接访问操作系统。但 shell 程序在进行指令处理的时候,对于有风险的指令,shell 程序会创建一个子进程,让子进程去执行有风险的指令(一般是用户自定义的指令)。
创建子进程可以将指令执行过程隔离在一个独立的进程空间中,这样,即使执行出现错误或意外,也不会影响到shell本身及其他进程;其次,shell 可以通过控制子进程的进程状态和资源使用情况,来限制指令的影响范围,减少风险,极大的保证了系统的安全性和稳定性。
杀掉一个进程的指令:
kill -9 进程编号
Linux用户
Linux系统的用户分为 root 用户 和 非root 用户,root 用户是超级管理员,拥有系统的最高权限;而普通用户可以在自己的系统中干大部分的事,我们使用 windows 系统可以做的事基本普通用户都可以做,而对于系统软件安装和删除、修改系统配置等却只有root用户才可以干。
普通用户的创建和删除
在一台Linux系统中,只能有一个root用户,但可以有多个普通用户,各普通用户之间的资源不共享。
创建新用户 xxx为要创建的用户名
adduser xxx
为用户设置密码 xxxxx为密码(终端不显示输入的密码,但会进行二次确认)
passwd xxxxx
删除用户名和密码
userdel xxx
删除用户数据
userdel rm -r xxx
用户的切换
切换为root用户
su - #以root身份再登录一次
su #切换为root身份
以上两种切换方式都需要再次输入root账号密码
logout # 退回到普通用户的账号
切换为普通用户
su xxx
root账号切换不需要输入密码,普通账号需要输入切换账号的密码
exit
退出切换过来的普通账号
如何不切换为root账号,还能以root账号的权限,执行一条命令
sudo 指令
但是使用 sudo 指令需要以root身份将普通用户将普通用户添加至白名单之后才可使用 sudo。
sudo指令白名单教程
首先,先将用户切换至 root 账号,在root账号下运行如下指令
vim /etc/sudoers
进入 vim 后找到 %whell ALL=(ALL) ALL 这句指令
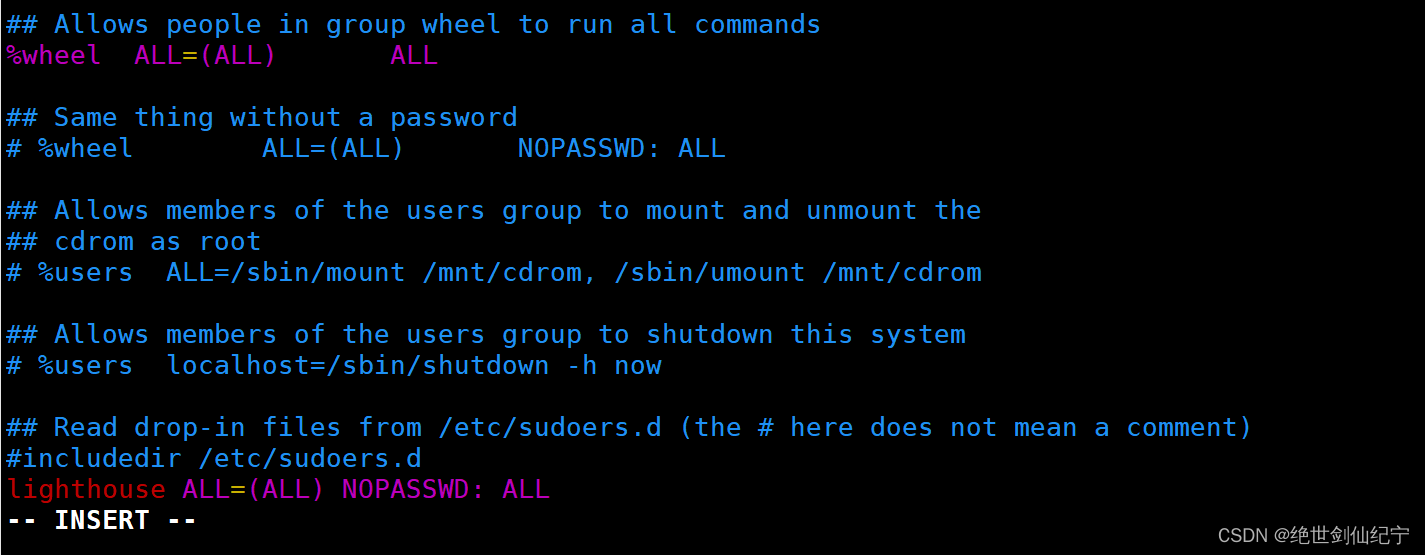
将这句指令复制一份,在下面紧接着将whell改为你要添加白名单的用户名

进入底行模式模式后,先按 w! 强制保存,q! 强制退出。以后Zyb这个账户在使用 sudo 指令的时候,在短期内只需要输入一次 Zyb 账号的密码即可。
Linux 权限
Linux 权限分类
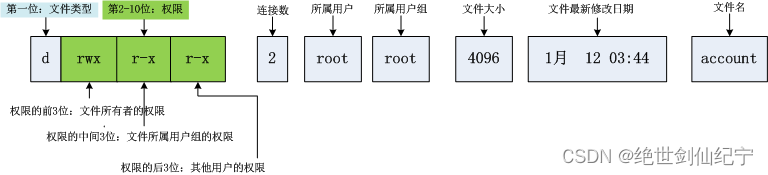
文件的权限属性:r(读)w(写) x(执行)
Linux文件权限角色群体:拥有者、所属组、other
文件所有者: 文件所有者是在创建文件时指定的用户,通常是创建该文件的用户。文件所有者具有对文件的所有权和完全访问权限,包括读取、写入和删除操作。
文件所属组: 文件所属组指定文件所属的组。在创建文件时,文件所属组通常被设置为创建用户所属的主组(“建个群”)。文件所属组的用户可以访问该文件,但没有所有权。
文件的other:它代表了其他所有用户或者组,即不是该文件的拥有者或所属组的用户或组。
如何对权限进行修改?
修改文件的拥有者和所属组需要root权限或者当前用户是该文件的原拥有者。可以使用指令 chown,newuser和newgroup是文件的新拥有者和新所属组。
修改文件的拥有者
chown newuser file.txt
修改文件的所属组
chgrp newgroup file.txt
同时修改文件的拥有者和所属组
chown newuser:newgroup file.txt
文件访问权限
在命令行中输入 ll,查看文件详细信息。
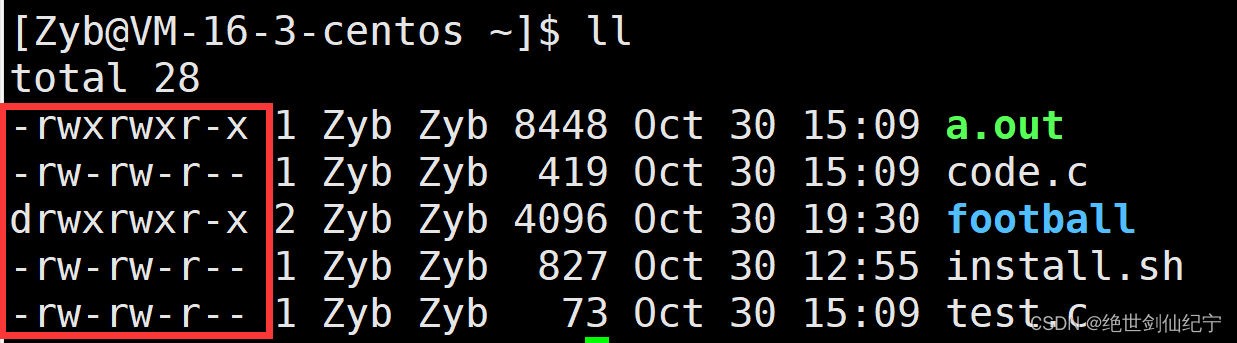
红色框中的就是文件角色的详细权限信息。
修改文件的权限
chomd ugoa +/- rwx 文件名
解释:u代表文件的拥有者 user ,g代表文件的所属组 group ,o 代表文件的 other ,a 代表操作文件的所有人;+ 代表增加某个权限,- 代表去掉某个权限;r w x 则分别代表文件的权限属性:读、写、执行,支持连续操作。
举例1:如我要去掉文件 test.txt 拥有者的读权限
chomd u-r test.txt
举例2:如果我要去掉文件 test.c 拥有者的读权限,增加所属组的写权限,other 的读权限,指令如下:
chomd u-r,g+w,o+r test.c
注意:必须是文件或目录的拥有者或超级用户(root)才有修改权限,拥有者要修改文件属性还要对改文件有写权限。无论是什么权限,在root账号下都形同虚设!
权限掩码
文件掩码可以定制一个文件被被创造时候的默认权限。
一个目录文件,被创建时理论上都拥有读写权和执行权(进入一个文件需要 x 权限),但有时候却不是全部有,同理,一个普通文件被创建时,至少应该拥有读写权。
将有该权限计为1,无该权限计为0
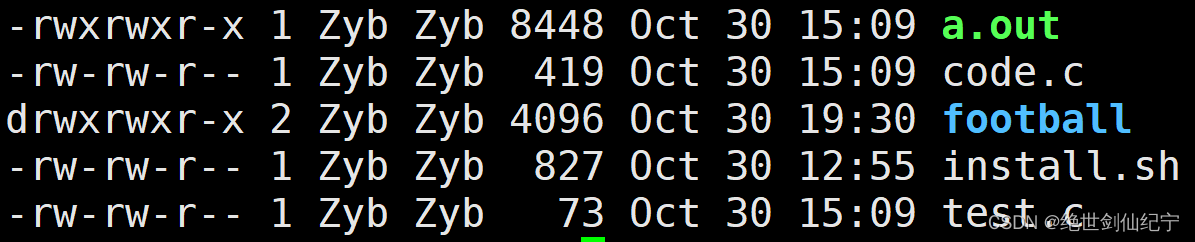
上图中文件的权限为:
111111101
110110100
111111101
110110100
110110100
权限顺序从左到右为 读、写、执行,将文件的每个角色的三种权限看作一位8进制的数,如下
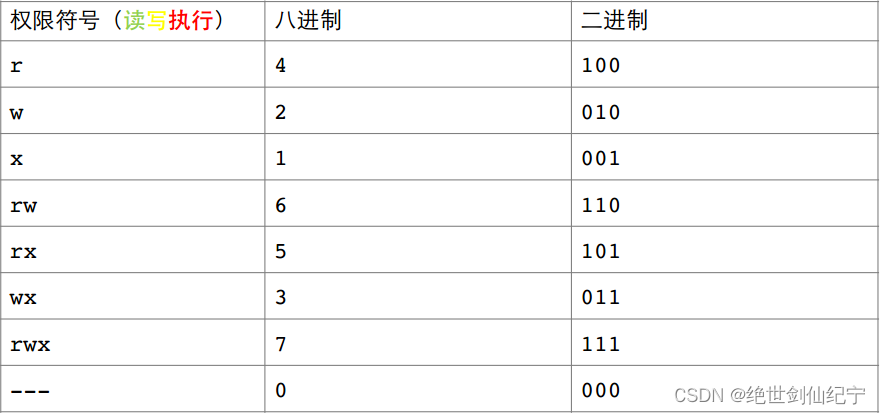
那么目录的起始权限就应该是 777,普通文件的其实权限就是 777。但为什么不是呢?这就与权限掩码有关了。规定一个文件的默认权限为文件的起始权限 - umask 中出现的权限(8进制减法)
umask 指令可以查询当前账号的文件掩码,可查到当前的文件掩码为 002

umask 权限编号 可以修改当前账号的文件掩码
如:umask 003 将本账号的文件掩码改为 005,创建文件 test.cc 、code.cc 、目录efootball,可以看到权限相对于之前创建的文件有所减少。
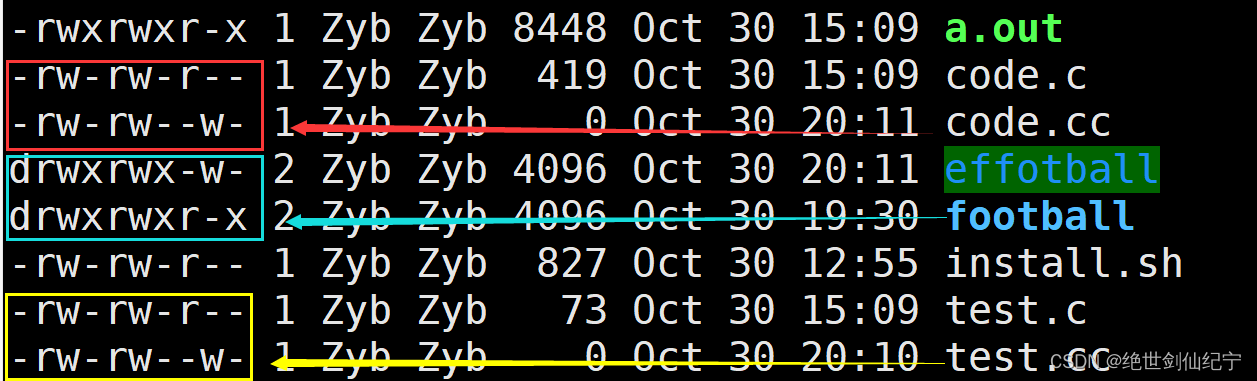
那这个是如何计算的呢?
在原理层面上,就是总权限的二进制与权限掩码比较,相同位有的就去掉,没有的就不做处理。也可以使用如下的公式计算:
最终权限 = 起始权限&(~umask)
注意:一个文件是否能被删除,并不取决于文件本身!而取决于文件所处的目录,拥有者是否具有写权限。当然,root 账号为所欲为。
粘滞位
在共享文件目录中,我们在不设置所属组的情况下,可以给此目录的 other 添加一个粘滞位t,代替other 的最后一个权限 x,时期具体x 的意义,同时也进一步对此目录的权限进行特殊限制:目录对 other 具有 w 属性,但该目录中的文件,只有root或文件的所有者有权利删除,其他人一概不许!
粘滞位可以用来给目录添加特殊权限。