设计师用什么做网站,国外域名注册网站,营销型网站的类型有哪些,截屏的图片wordpress不能显示worker测试程序,类似mediasoup对uv的使用,是one loop per thread 。创建一个UVLoop 就可以创建一个uv_loop_t Transport 创建一个: 试验配置创建一个: UvLoop 封装了libuv的uv_loop_t ,作为共享指针提供 对uv_loop_t 创建并初始化
- worker测试程序,类似mediasoup
- 对uv的使用,是one loop per thread 。
创建一个UVLoop 就可以创建一个uv_loop_t
-
Transport 创建一个:
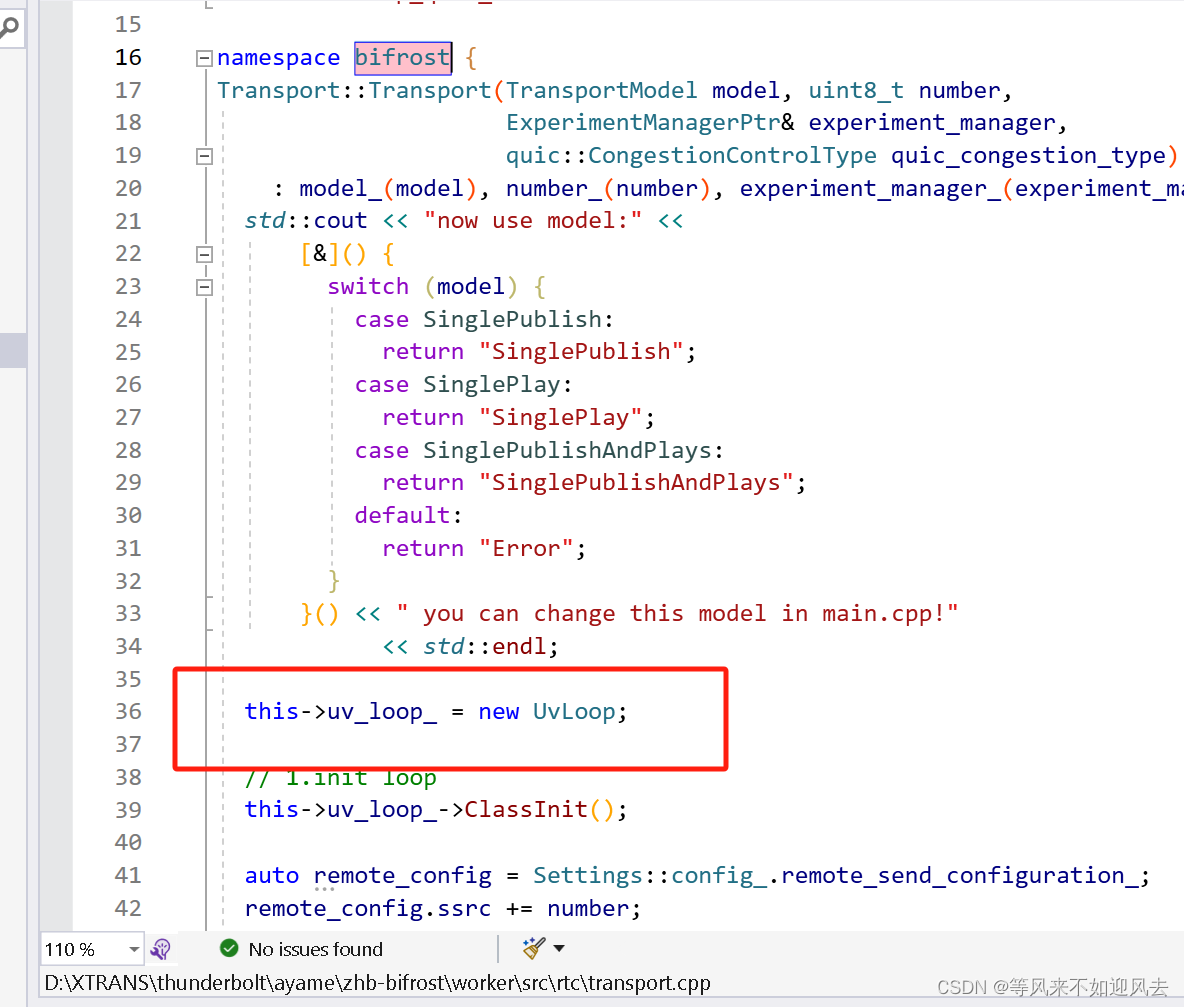
-
试验配置创建一个:
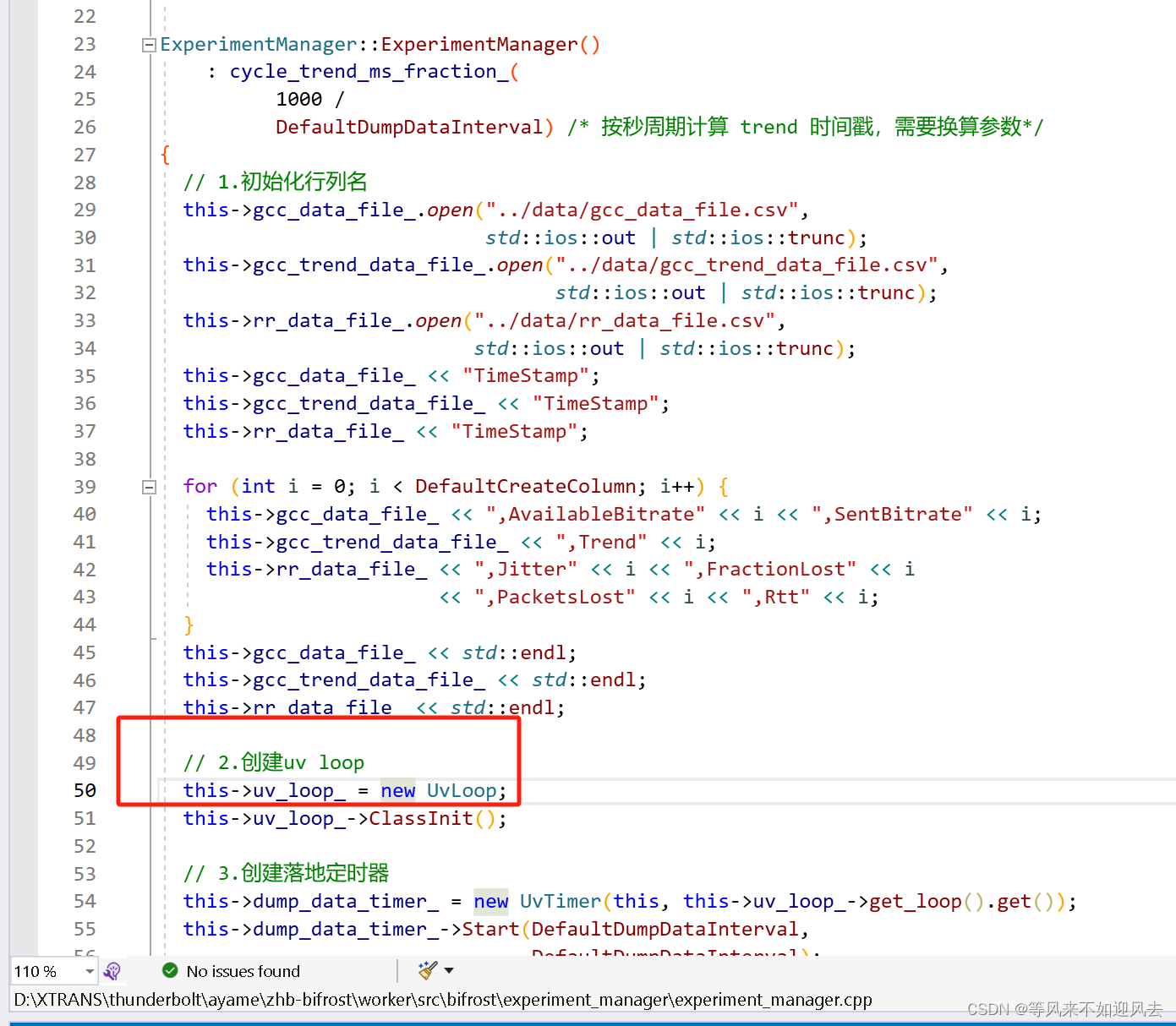
UvLoop 封装了libuv的uv_loop_t ,作为共享指针提供
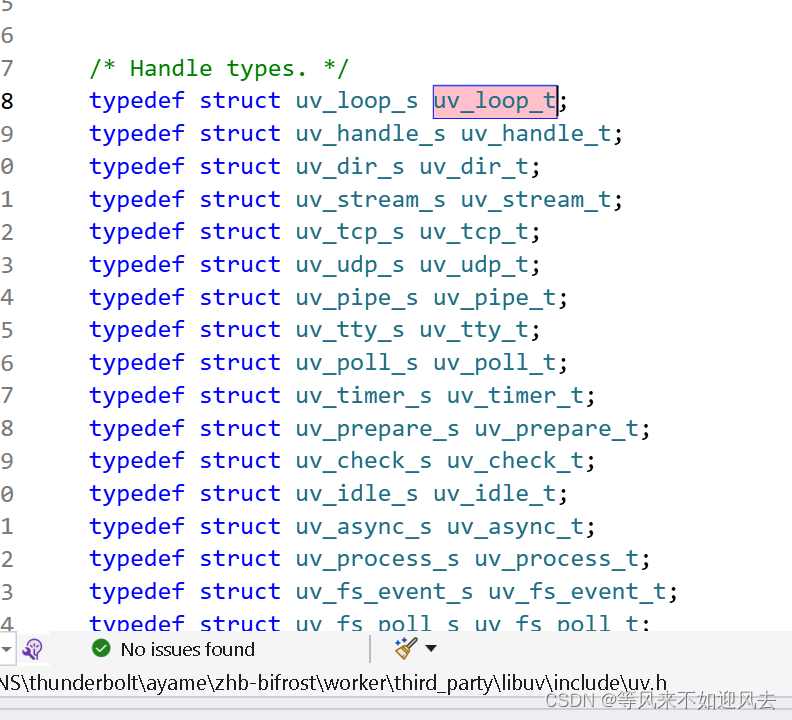
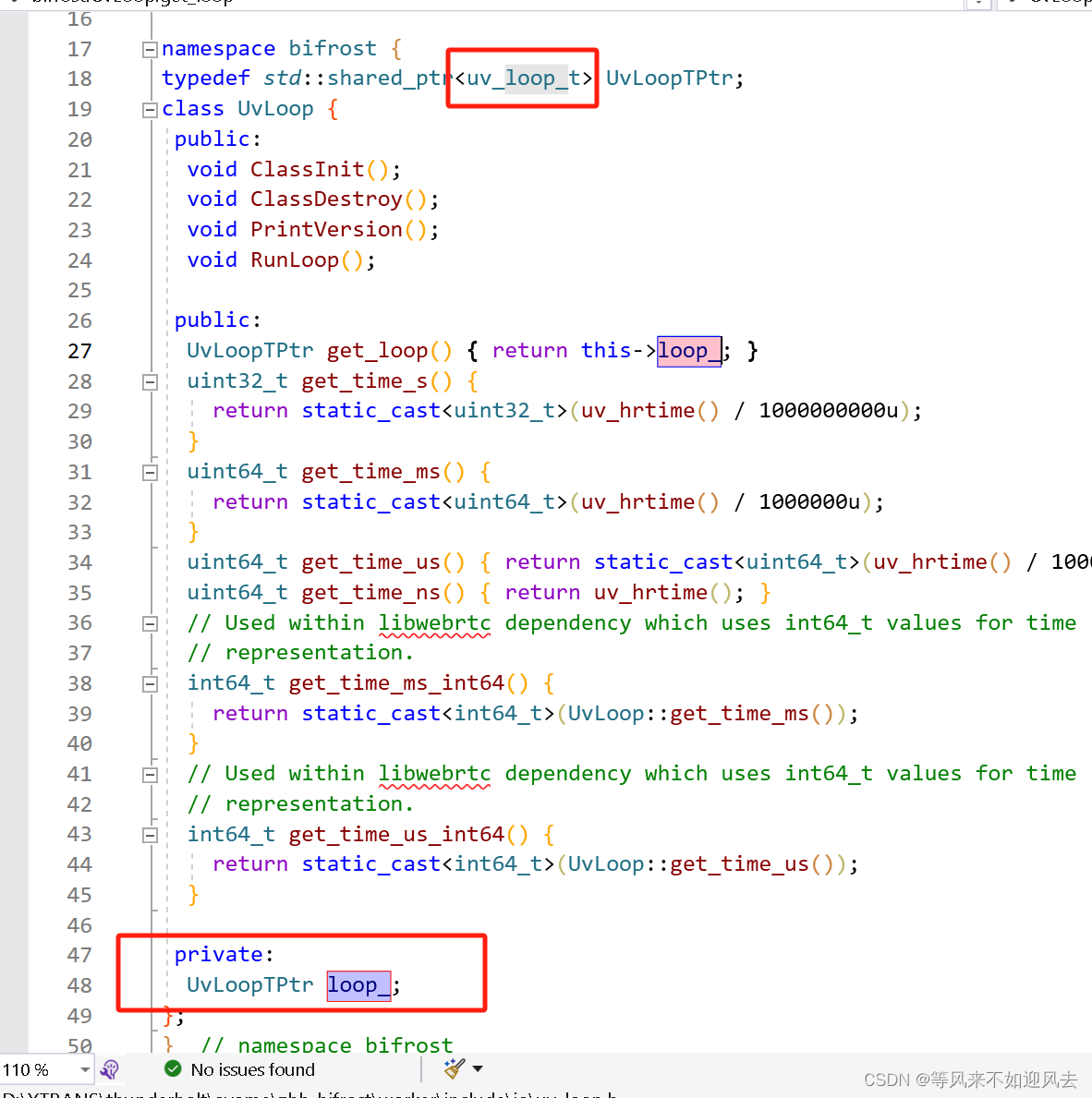
对uv_loop_t 创建并初始化