做网站需要多少钱 做成都电商平台网站设计
2.1 线性表
线性表是具有相同数据类型的n个数据元素的有限序列。第一个元素为表头元素,最后一个元素为表尾元素。除第一个元素,每个元素有且仅有一个直接前驱。除最后一个元素,每个元素都仅有一个直接后继。
其中线性表包括以下(字有点丑,不要介意):

接下来展开讲述顺序表
2.2顺序表
线性表的顺序存储叫做顺序表。它是由一组地址连续的存储单元依次存储线性表中的数据元素,从而使得逻辑上相邻的两个元素在物理位置上也相邻,举个例子其实数组就是典型的顺序存储结构。
通过数组,我们可以分析一波顺序表。
优点:随机访问,访问时间O(1);存储密度高;
缺点:插入和删除操作需要移动大量元素(在数组插入或者删除某元素,因为要保证元素与元素的顺序结构,必然会需要移动大量元素。)
接下来就是顺序存储结构的大小分配,也可认为是数组的静态分配和动态分配,搞过程序设计的友友通常会理解。有明确的数据个数时,可以采用静态数组。有个时候不知道数据有多少个,不知道要分配多大的数组的时候,就采用动态数组。以下的ElemType为数据类型,可以是int,string,等;
静态顺序表:
#define MaxSize 50 //定义顺序表最大长度
typedef struct{ElemType data[MaxSize];//顺序表的元素int length; //顺序表的当前长度
}SeqList; //顺序表的类型定义动态顺序表:
#define InitSize 100 //表长度的初始定义
typedef struct{ ElemType* data; //指示动态分配的数组的指针int MaxSize ,length; //数组的最大容量和当前个数
}SeqList; //动态分配数组顺序表的类型定义
C语言初始化动态分配语句:
SeqList L;//L为顺序表
L.data = (int*) malloc (sizeof(int) * InitSize);//sizeof(数组名),这里的数组名表示整个数组,sizeof(数组名)计算的是整个数组的大小C++的初始动态分配语句为:
SeqList L;
L.data = new ElemType(InitSize);写到这里我还是想简单说一下我对于&和*的理解。
首先先说一下地址吧,我们存储的每一个数据都是有相应的地址的,就像我们寄东西给别人,我们需要给出对方的所在地址,我们才可以寄给对方,计算机中数据也不例外。指针是什么呢,我通常认为是指向一个某一数据类型变量地址的读取工具,例如我知道了对方的地址,我需要去访问我就需要用到指针,需要看后面的代码理解。”&“是取地址符号,取地址应该非常好理解吧,就是获得相应变量的地址。为了方便理解,直接上代码:
#include<stdio.h>
int main()
{int a=10;printf("%lld",&a);
}运行结果大家都不一样的,我的是这个:
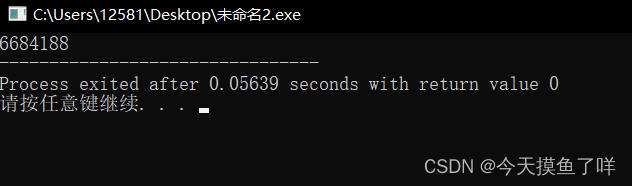
这个返回的就是a的地址。
对于“*"的理解,我先展示一段代码和结果:
#include<stdio.h>
int main()
{int a = 10;int* b = &a;//(int*)是一个int指针类型printf("%d\n",*b);printf("%d",b);
}结果是这样的:
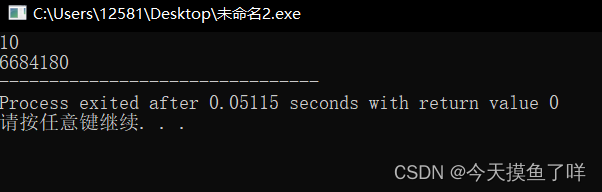
注意了喔,int* b = &a;里面的" int* "的是固定的搭配,不要混了,以为是b上面的。b作为int指针类型,存的是a的地址,给它一个"*",“*b"转到获取该地址的数据值,所以”*“是间接访问操作符。当然,这个只是指针的冰山一角,如果有兴趣,最好还是去看看专业书籍。
最后拿着C语言初始化动态分配结合数据结构来实现一波:
#include<stdio.h>
#include <stdlib.h>
#define InitSize 100 //表长度的初始定义
typedef struct
{ int *data; //指示动态分配的数组的指针int MaxSize ,length; //数组的最大容量和当前个数
}SeqList; //动态分配数组顺序表的类型定义int main()
{SeqList L;L.data = (int*) malloc (sizeof(int) * InitSize);L.length = 50;L.MaxSize = 100;//给数组的前50个分别赋值0,1....49for(int i= 0;i<50;i++){*(L.data+i) = i;//L.data+i类似于数组的序号依次递增,如a[0],a[1]...a[49]}//打印输出for(int i = 0;i<50;i++){printf("%d ",*(L.data+i));}free(L.data);//记得malloc动态分配的存储空间需要释放
}结果如下:

最好的理解当然是自己去敲一遍代码,实现一次。最后的最后,上文如果有什么描述不准确的或错误,欢迎各位佬指出!
趁年轻,勇敢闯!