建设一批适合青少年的网站免费足网站
⭐博客主页:️CS semi主页
⭐欢迎关注:点赞收藏+留言
⭐系列专栏:C++进阶
⭐代码仓库:C++进阶
家人们更新不易,你们的点赞和关注对我而言十分重要,友友们麻烦多多点赞+关注,你们的支持是我创作最大的动力,欢迎友友们私信提问,家人们不要忘记点赞收藏+关注哦!!!
多态
- 前言
- 一、多态的概念
- 二、多态的定义及实现
- 1、多态的构成条件
- 2、虚函数
- 3、虚函数的重写
- (1)基类virtual和派生类virtual
- (2)协变
- (3)析构函数的重写(基类与派生类析构函数的名字不同)
- (4)面试问题 -- 析构函数是虚函数?
- 三、C++11 override 和 final
- 1、final:修饰虚函数,表示该虚函数不能再被重写
- 2、override: 检查派生类虚函数是否重写了基类某个虚函数,如果没有重写编译报错。
- 3、设计一个不被继承的类
- (1)基类构造函数私有(C++98)
- (2)基类加一个final不让它继承(C++11)
- 四、重载、覆盖(重写)、隐藏(重定义)的对比
- 五、抽象类
- 1、概念
- 2、接口继承和实现继承
- 六、多态的原理
- 1、虚函数表
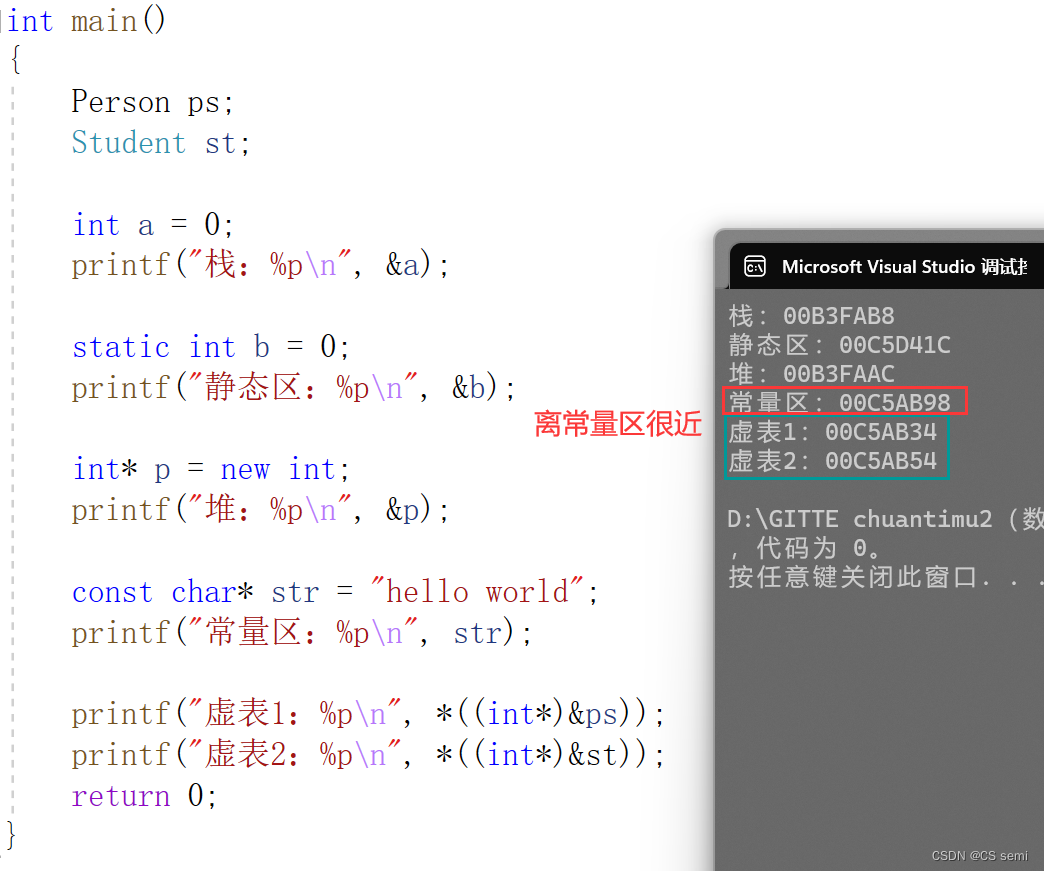
- 验证虚表存放在常量区
- 2、从多态原理分析多态的构成条件(回答多态构成条件)
- (1)为什么不是子类的指针或者是引用呢?
- (2)为什么一定是指针或者是引用呢?不能是对象吗?
- 3、多态的底层原理
- 4、动态绑定与静态绑定
- 七、单继承和多继承关系的虚函数表
- 1、单继承中的虚函数表
- 2、多继承中的虚函数表
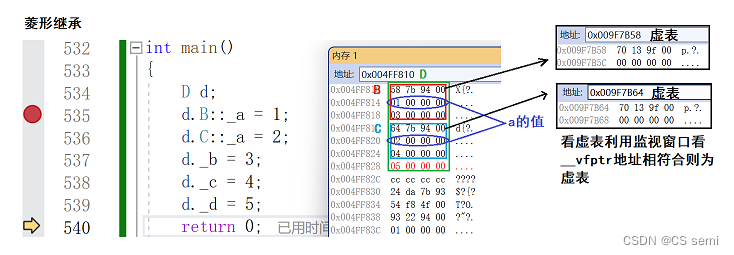
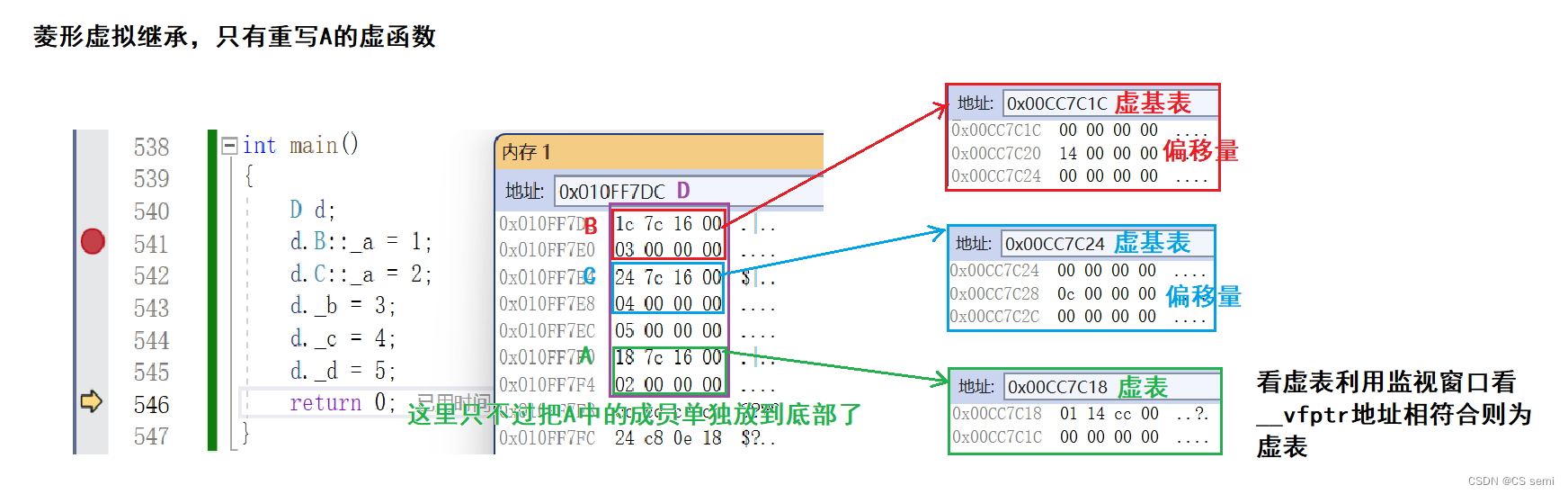
- 3、菱形虚拟继承中的虚函数表
- 八、面试题
- 1、子类父类虚函数
- 2、问答题
前言
多态的概念又难又杂,不仅仅要学好多态本身的知识点,更要加上继承两者一起进行实现讲解,让整个代码显得很高级…
一、多态的概念
顾名思义,多态就是多种形态,我们这里举简单又形象的例子供大家形象地理解。
当我们在放暑假的时候一窝蜂抢高铁票的时候,对于我们大学生会有两个窗口,第一个是成人票,第二个是学生票。当我们满足学生票的购票区间的条件,系统就会跳转到学生票并显示相应的金额让我们进行支付,但如果我们不满足学生票的购票区间的条件,系统就会自动按照原本的成人票给我们算钱,所以,多态就是控制了系统往学生票还是成人票转。这就是多态。
二、多态的定义及实现
1、多态的构成条件
no1.在不同的继承关系中调用相同的函数,实现这个函数的不同行为。
no2.必须通过基类的指针或者引用调用虚函数。
no3.被调用的函数必须是虚函数,且派生类必须对基类的虚函数进行重写。

2、虚函数
虚函数:即被virtual修饰的类成员函数称为虚函数。

3、虚函数的重写
虚函数的重写(覆盖):派生类中有一个跟基类完全相同的虚函数(即派生类虚函数与基类虚函数的返回值类型、函数名字、参数列表完全相同),称子类的虚函数重写了基类的虚函数。

(1)基类virtual和派生类virtual
派生类的重写虚函数可以不加virtual

(2)协变
返回值可以不同,但是要求返回值必须是父子关系指针和引用。
如下所示:
注意的是同时用指针或同时用引用
子对子,父对父


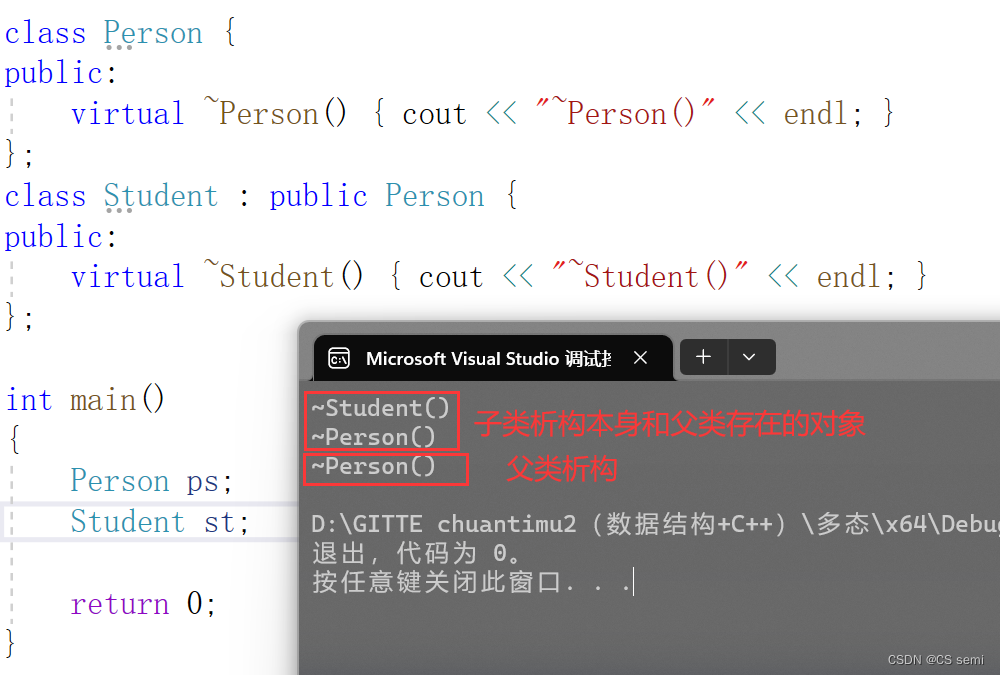
(3)析构函数的重写(基类与派生类析构函数的名字不同)
如果基类的析构函数为虚函数,此时派生类析构函数只要定义,无论是否加virtual关键字,都与基类的析构函数构成重写,虽然基类与派生类析构函数名字不同。虽然函数名不相同,看起来违背了重写的规则,其实不然,这里可以理解为编译器对析构函数的名称做了特殊处理,编译后析构函数的名称统一处理成destructor。
看的很鸡肋,但是在一种场景下很有用:
不加virtual虚函数的情况,容易造成内存泄露。
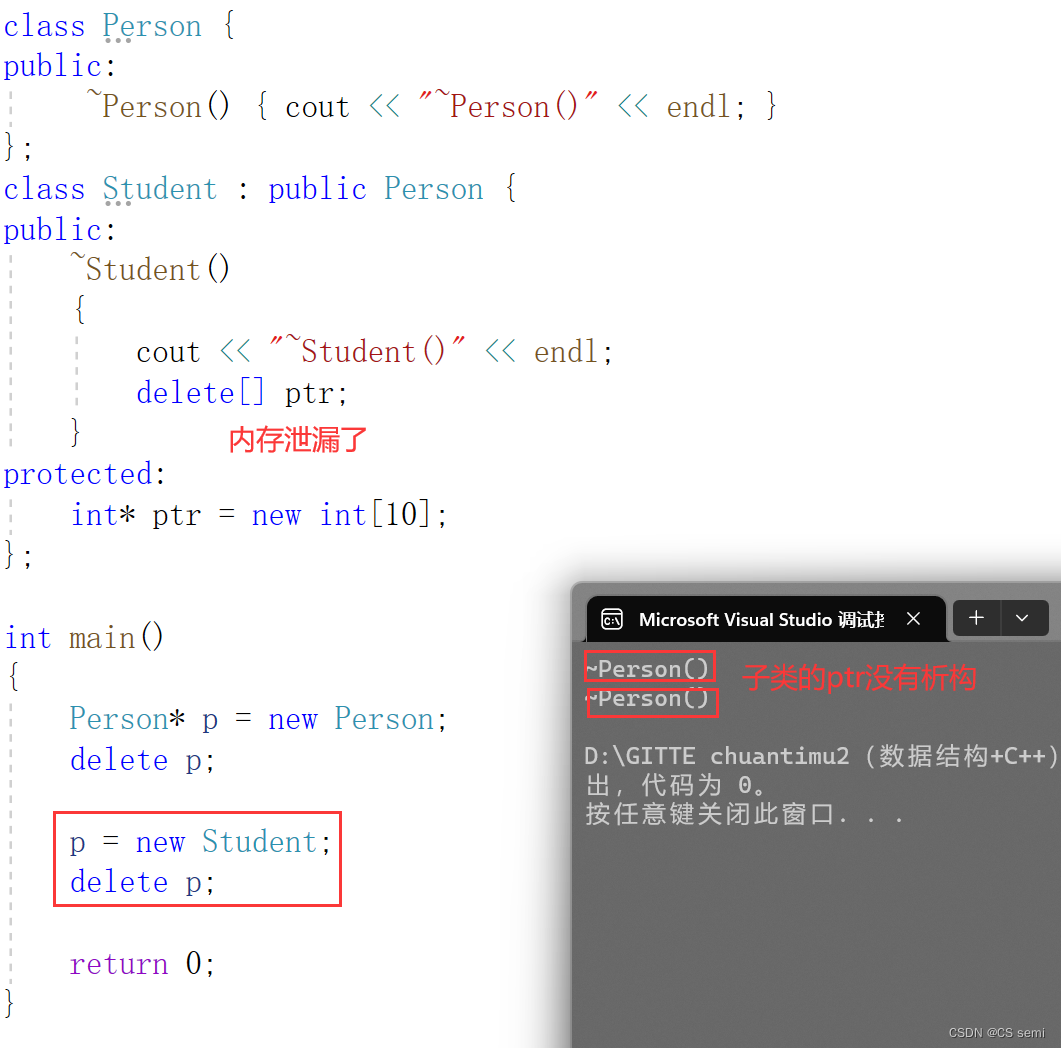
加了虚函数,不会导致内存泄漏:
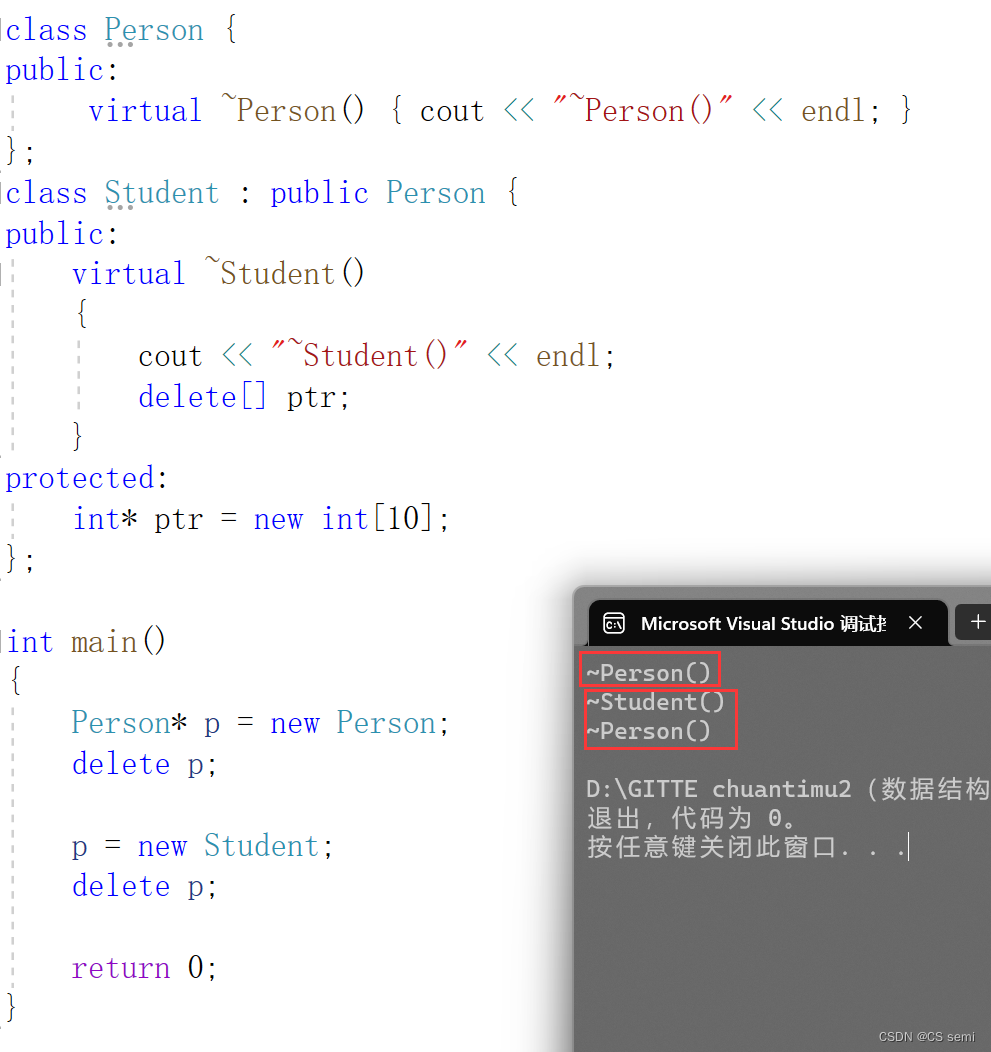
所以析构函数构成重写的过程为:
底下的delete p在编译器中加了虚函数以后被再次重新进行改写,统一改写成了p->destructor()+operator delete§为一个多态的调用,所有的析构函数不管是父类还是子类的析构函数都改写成了destructor()为一个多态的调用而不是一个普通调用,既然形成了一个多态的调用,就是析构函数的重写,那么去访问父类和子类的析构函数都不在话下。

(4)面试问题 – 析构函数是虚函数?
上述的原本面试问题为:析构函数是虚函数吗?为什么需要是虚函数,不能是普通函数呢?
解答:是虚函数,虚函数不会导致内存泄露的问题,我们经过演示,发现如果不是虚函数的话,main函数中的delete调用不到子类的析构函数,而只能调用父类的析构函数,如果在子类的析构函数中加上了释放内存的操作,释放不了内存导致内存泄露问题很严重。而我们在析构函数是个虚函数,加上了virtual的话,编译器内部自动将main函数中的delete转化成为p->destructor()+operator delete§,destructor()是编译器将不同的析构函数改写成为destructor(),实现析构函数的重写了,main函数中的调用是一个多态的调用,能够进行正确的调用析构函数了。
所以日常当中我们在基类的析构函数中加上virtual变成虚函数即可。
三、C++11 override 和 final
1、final:修饰虚函数,表示该虚函数不能再被重写

2、override: 检查派生类虚函数是否重写了基类某个虚函数,如果没有重写编译报错。


3、设计一个不被继承的类
(1)基类构造函数私有(C++98)

解决方法:

(2)基类加一个final不让它继承(C++11)

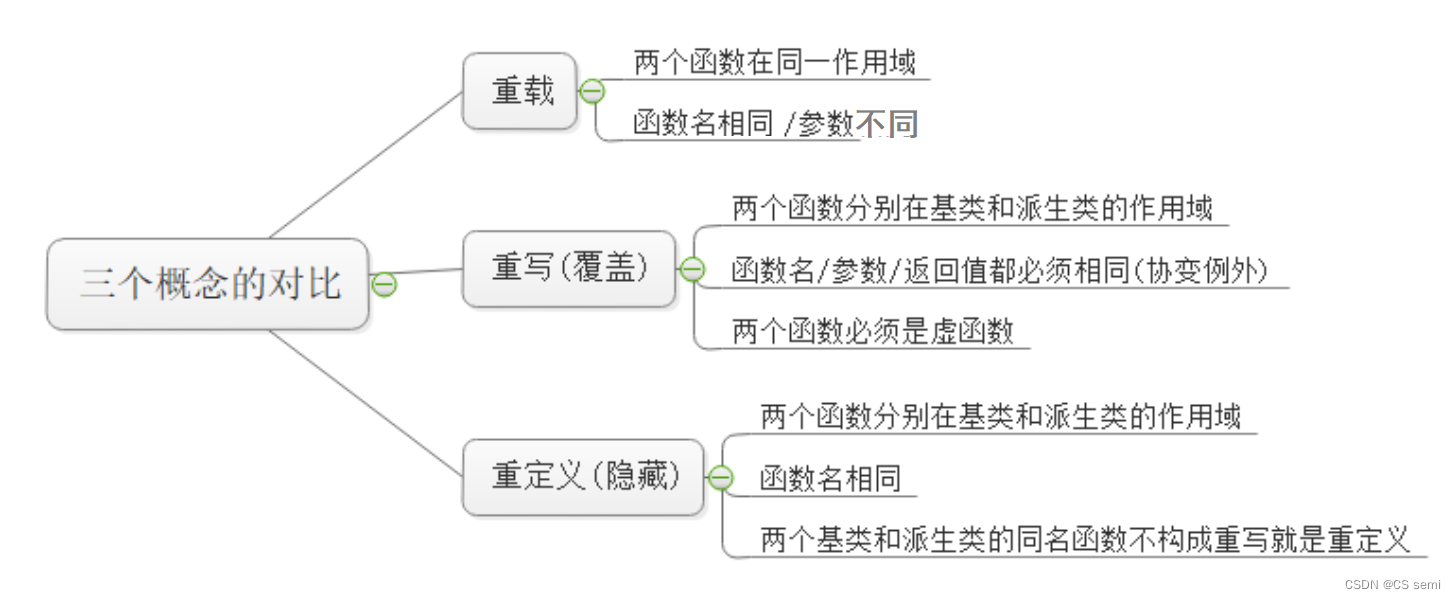
四、重载、覆盖(重写)、隐藏(重定义)的对比
五、抽象类
1、概念
在虚函数的后面写上 =0 ,则这个函数为纯虚函数。包含纯虚函数的类叫做抽象类(也叫接口类),抽象类不能实例化出对象。派生类继承后也不能实例化出对象,只有重写纯虚函数,派生类才能实例化出对象。纯虚函数规范了派生类必须重写,另外纯虚函数更体现出了接口继承。

2、接口继承和实现继承
普通函数的继承是一种实现继承,派生类继承了基类函数,可以使用函数,继承的是函数的实现。虚函数的继承是一种接口继承,派生类继承的是基类虚函数的接口,目的是为了重写,达成多态,继承的是接口。所以如果不实现多态,不要把函数定义成虚函数。
实现多态就只需要定义一个指针或者是引用,再在继承的类中进行重写即可。
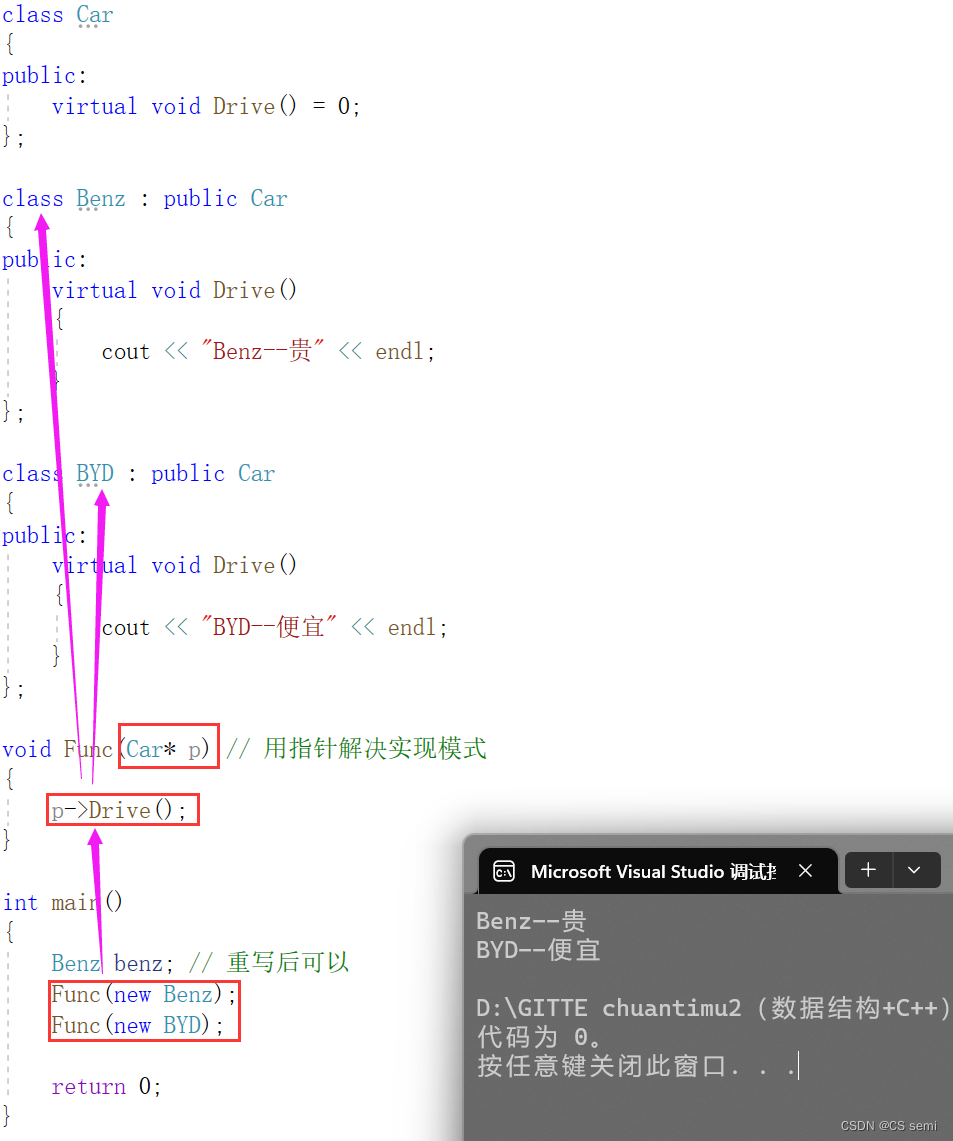
抽象类什么用?间接强制派生类进行虚函数的重写。
六、多态的原理
1、虚函数表
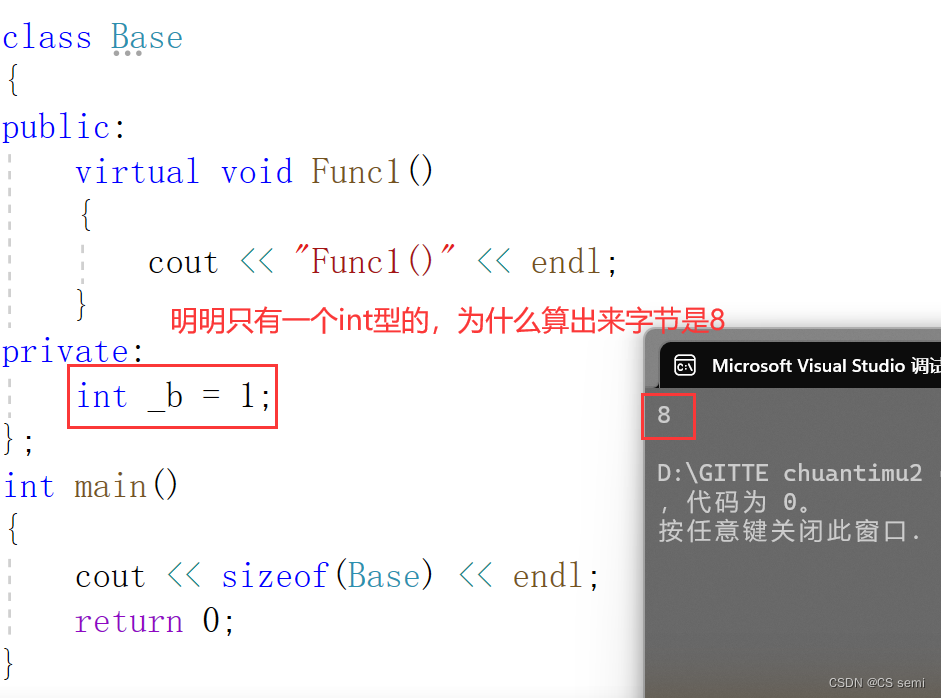
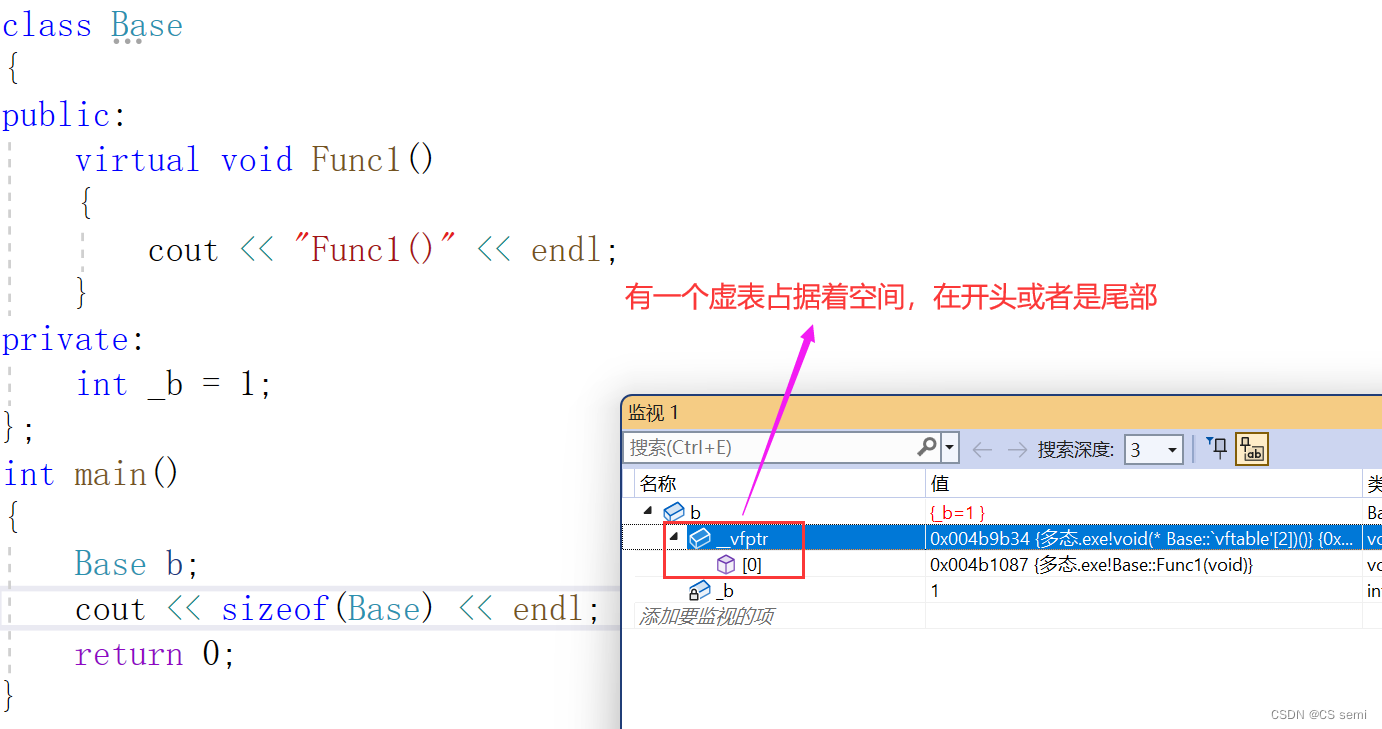
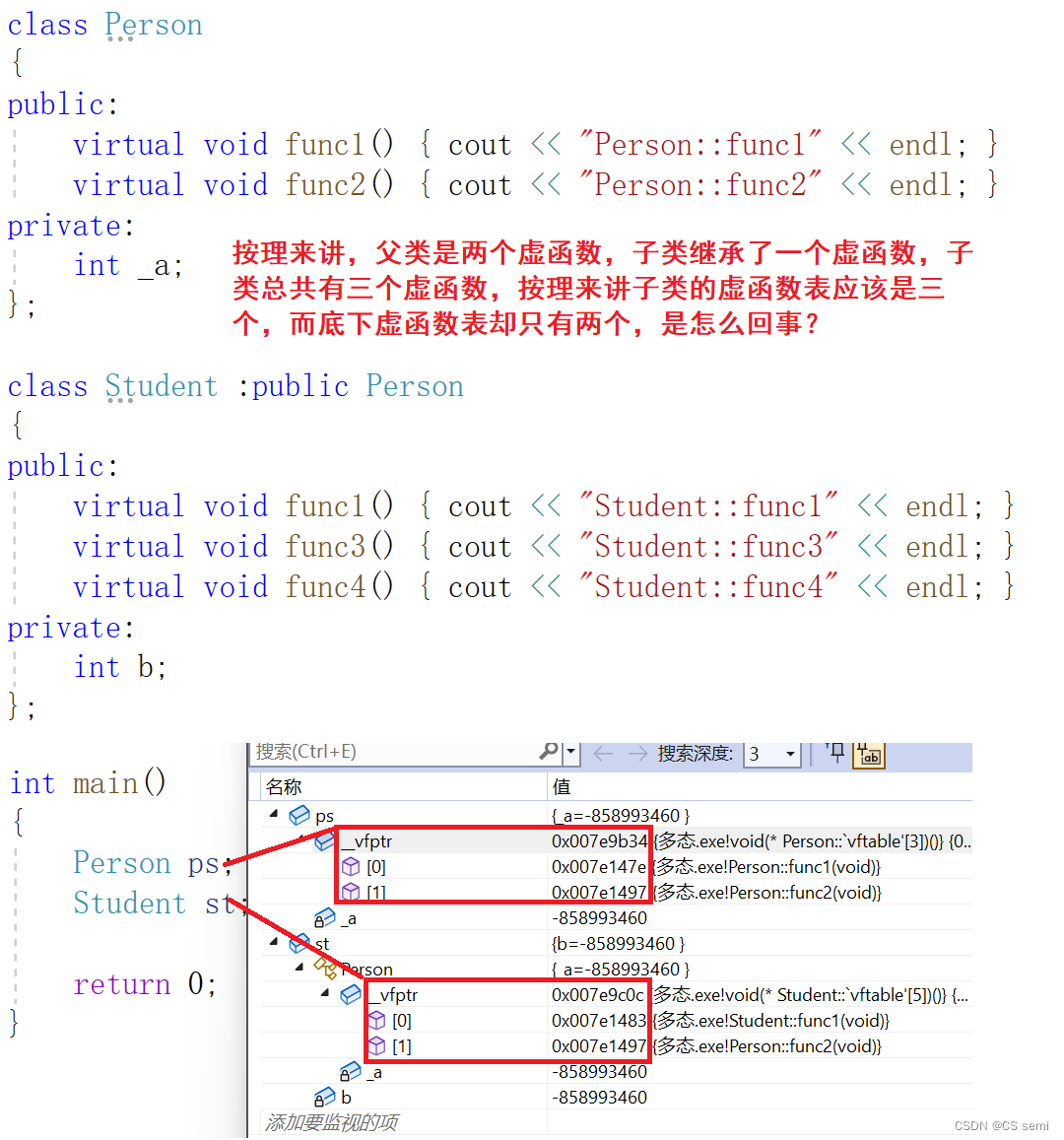
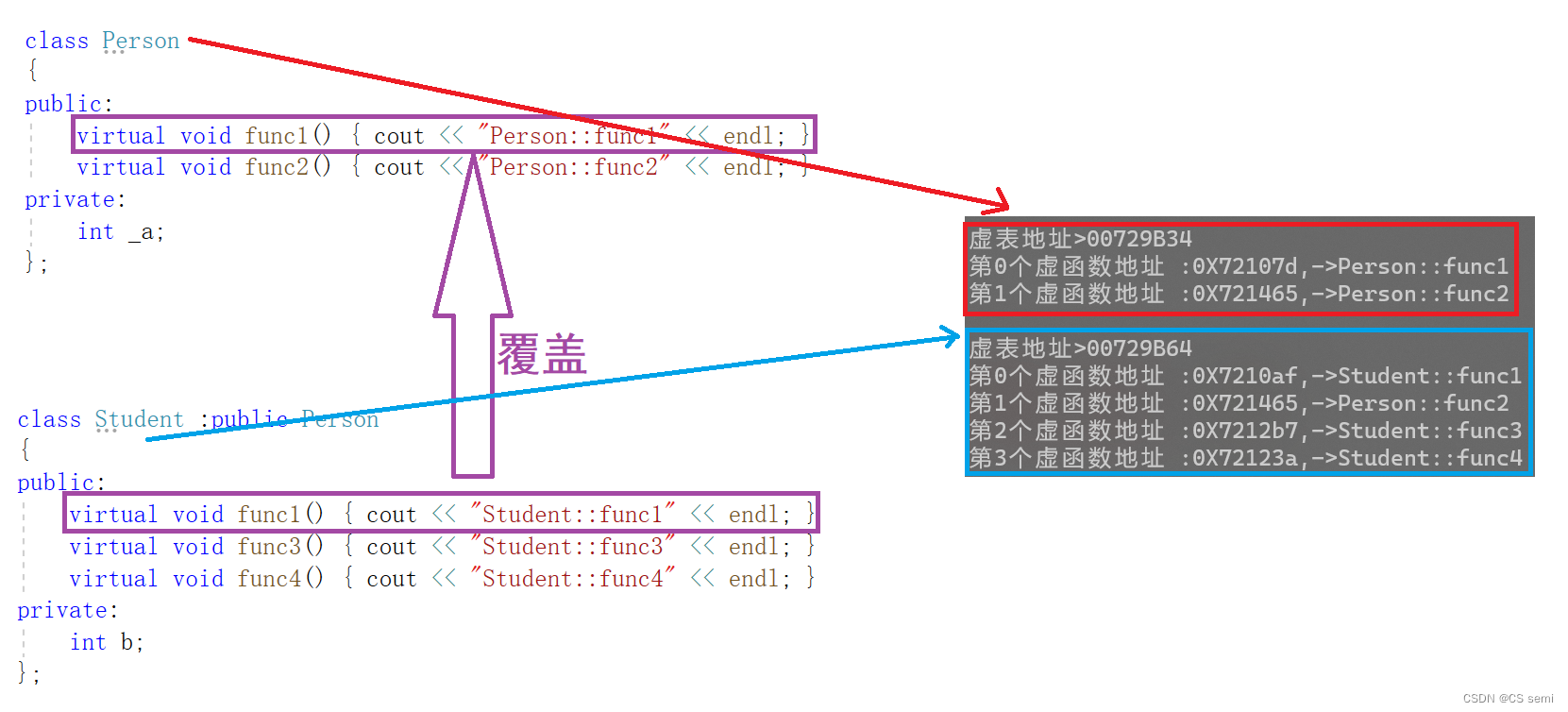
除了_b成员,还多一个__vfptr放在对象的前面,对象中的这个指针我们叫做虚函数表指针(v代表virtual,f代表function)。一个含有虚函数的类中都至少都有一个虚函数表指针,因为虚函数的地址要被放到虚函数表中,虚函数表也简称虚表,那么派生类中这个表放了些什么呢?
我们在原有的基础上增加一个子类去继承,在基类中重写一个func1函数,子类再增加一个虚函数func2和一个普通函数func3。

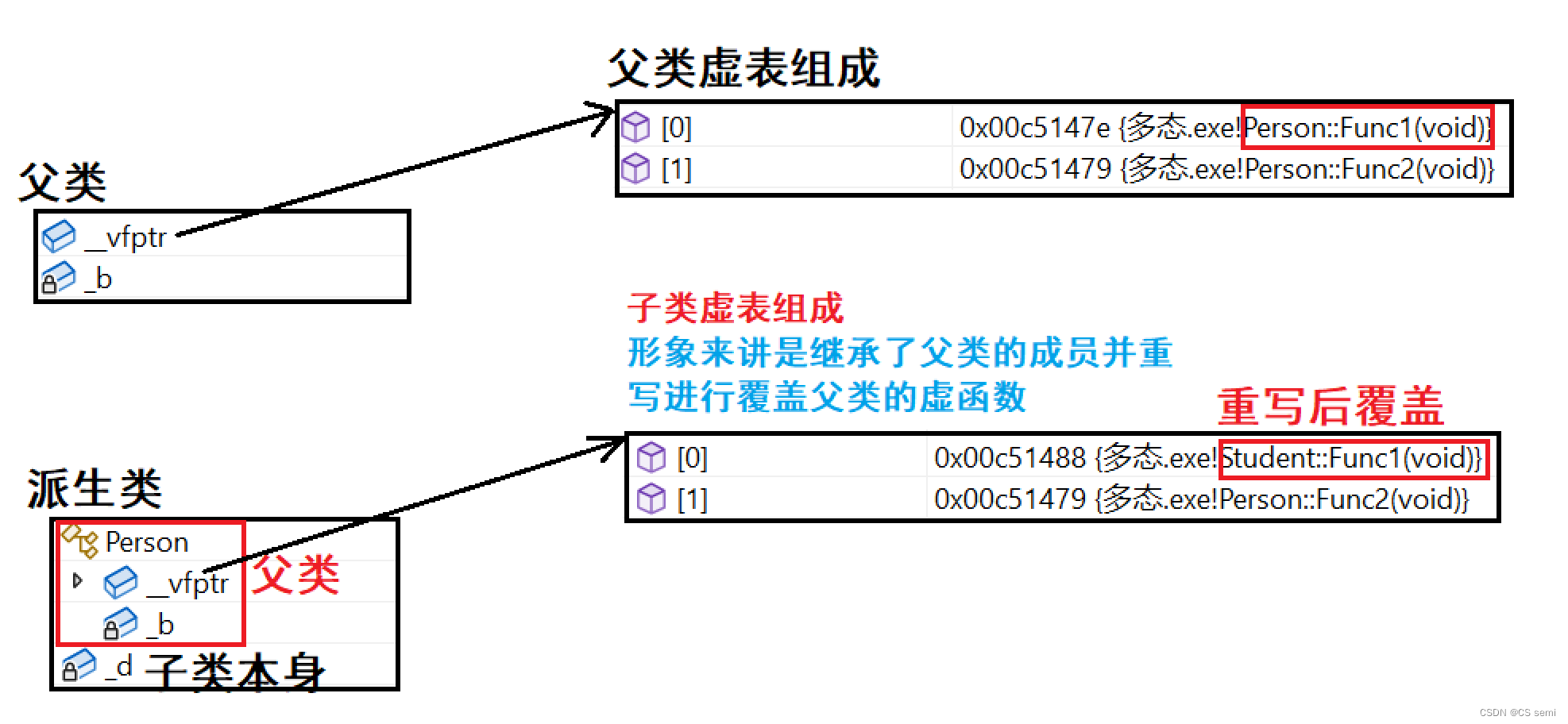
通过分析发现得出下面结论:
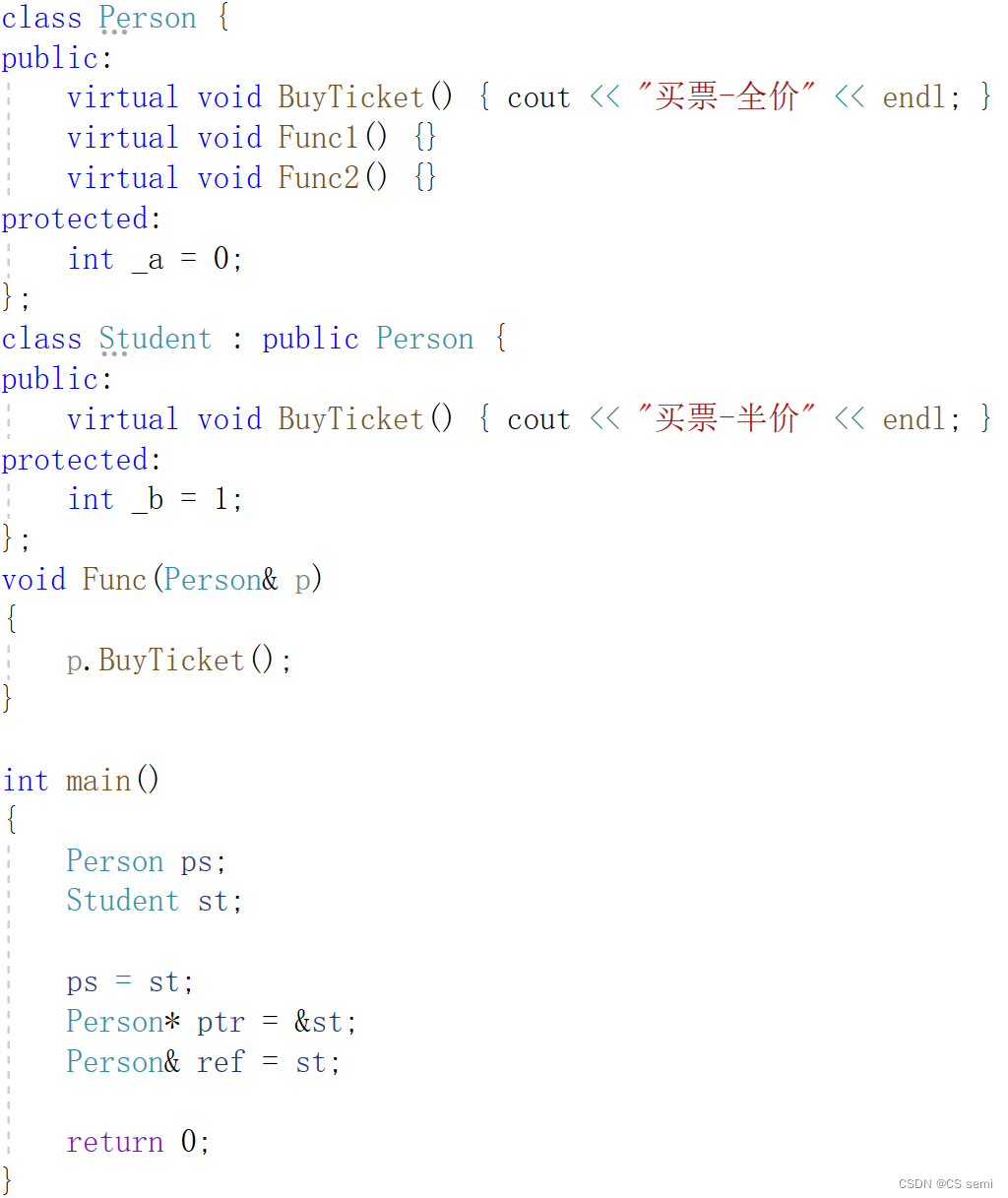
- 派生类对象d中也有一个虚表指针,d对象由两部分构成,一部分是父类继承下来的成员,虚表指针也就是存父类继承下来的部分以及另一部分是自己的成员。
- 基类b对象和派生类d对象虚表是不一样的,这里我们发现Func1完成了重写,所以d的虚表中存的是重写的Student::Func1,所以虚函数的重写也叫作覆盖,覆盖就是指虚表中虚函数的覆盖。重写是语法的叫法,覆盖是原理层的叫法。
- Func2继承下来后是虚函数,所以放进了子类的虚表,Func3也继承下来了,但是不是虚函数,所以不会放进虚表。
- 虚函数表本质是一个存虚函数指针的指针数组,一般情况这个数组最后面放了一个nullptr。
- 派生类的虚表生成:a.先将基类中的虚表内容拷贝一份到派生类虚表中 b.如果派生类重写了基类中某个虚函数,用派生类自己的虚函数覆盖虚表中基类的虚函数 c.派生类自己新增加的虚函数按其在派生类中的声明次序增加到派生类虚表的最后。
- 虚表放在常量区(代码段)。虚表存的是虚函数指针,不是虚函数,虚函数和普通函数一样的,都是存在代码段的,只是他的指针又存到了虚表中。另外对象中存的不是虚表,存的是虚表指针。
验证虚表存放在常量区
验证虚表存放在常量区:
2、从多态原理分析多态的构成条件(回答多态构成条件)
两个想法:1、调用子类的指针或者是引用呢?2、调用的是父类对象呢?
(1)为什么不是子类的指针或者是引用呢?
根据我们学过的知识,用基类的指针或引用能够找到子类的各个成员,同样也不仅仅能够用基类的各个成员。也就是基类的指针或引用既能够指向基类,也能够指向派生类。
(2)为什么一定是指针或者是引用呢?不能是对象吗?
为什么不能是父类的对象实现多态呢?
如下代码:
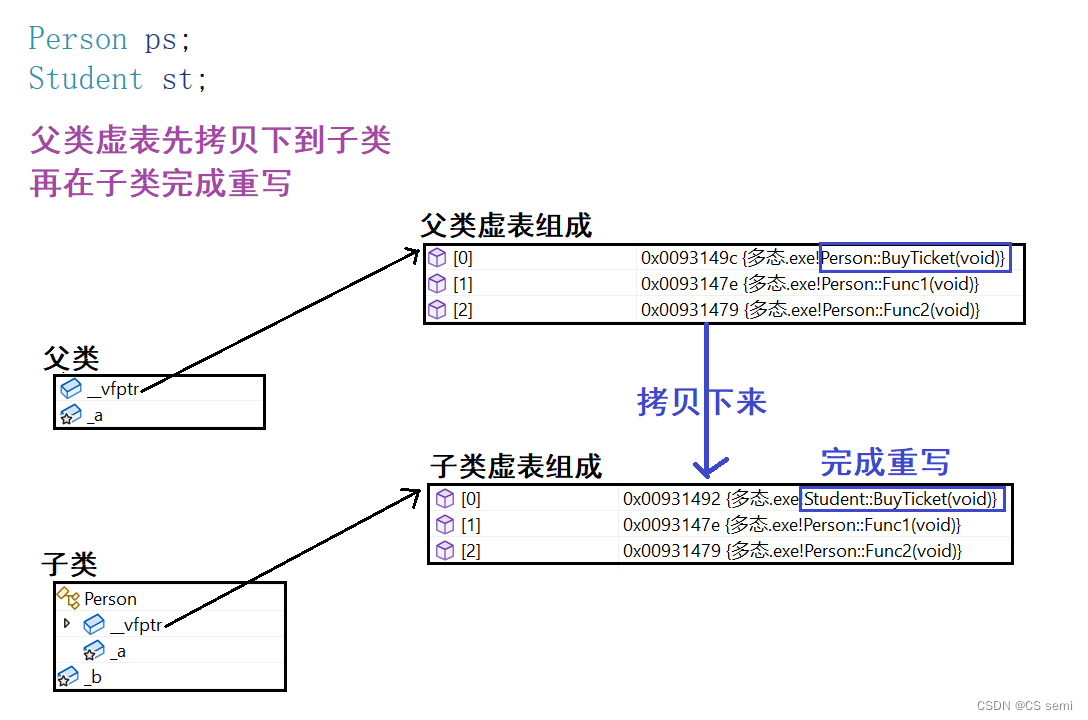
看上面两张图的逻辑是:在定义ps和st的时候就已经构造好了两个虚表,我们通过指针和引用的话直接通过地址去寻找到然后进行多态的处理即可。
ps = st呢?这个是标准的父类对象,如果用父类对象实现多态的话,切片处理肯定要拷贝的!!!如果拷贝虚表过去肯定不符合的,虚表拷贝过去都一样了,不知道是子类还是父类的虚表,而我们进调试发现,虚表是不会被拷贝过去的,所以否决了父类对象的设想,所以要用指针或者引用。(不懂的话理解成它父类对象本身的虚表不允许被改变,用父类对象作为多态的条件,改变了虚表不成立)
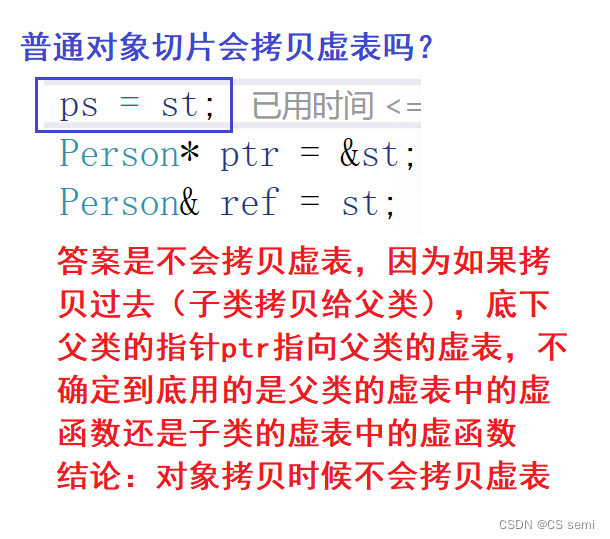
结论:只有指针和引用访问才能实现晚绑定,如果是使用的是对象的话,再编译期间就已经绑定完成了,不需要实现多态了。
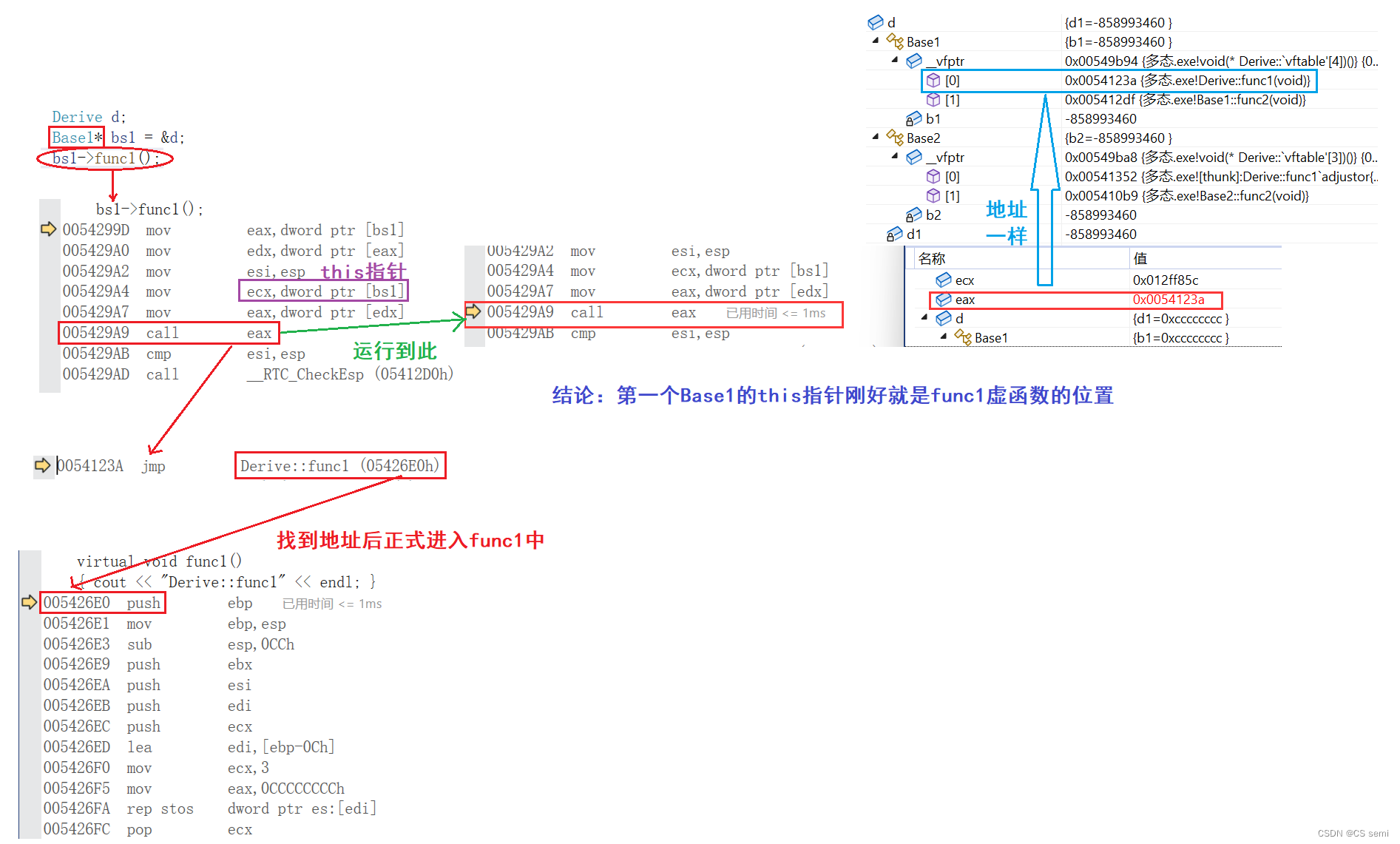
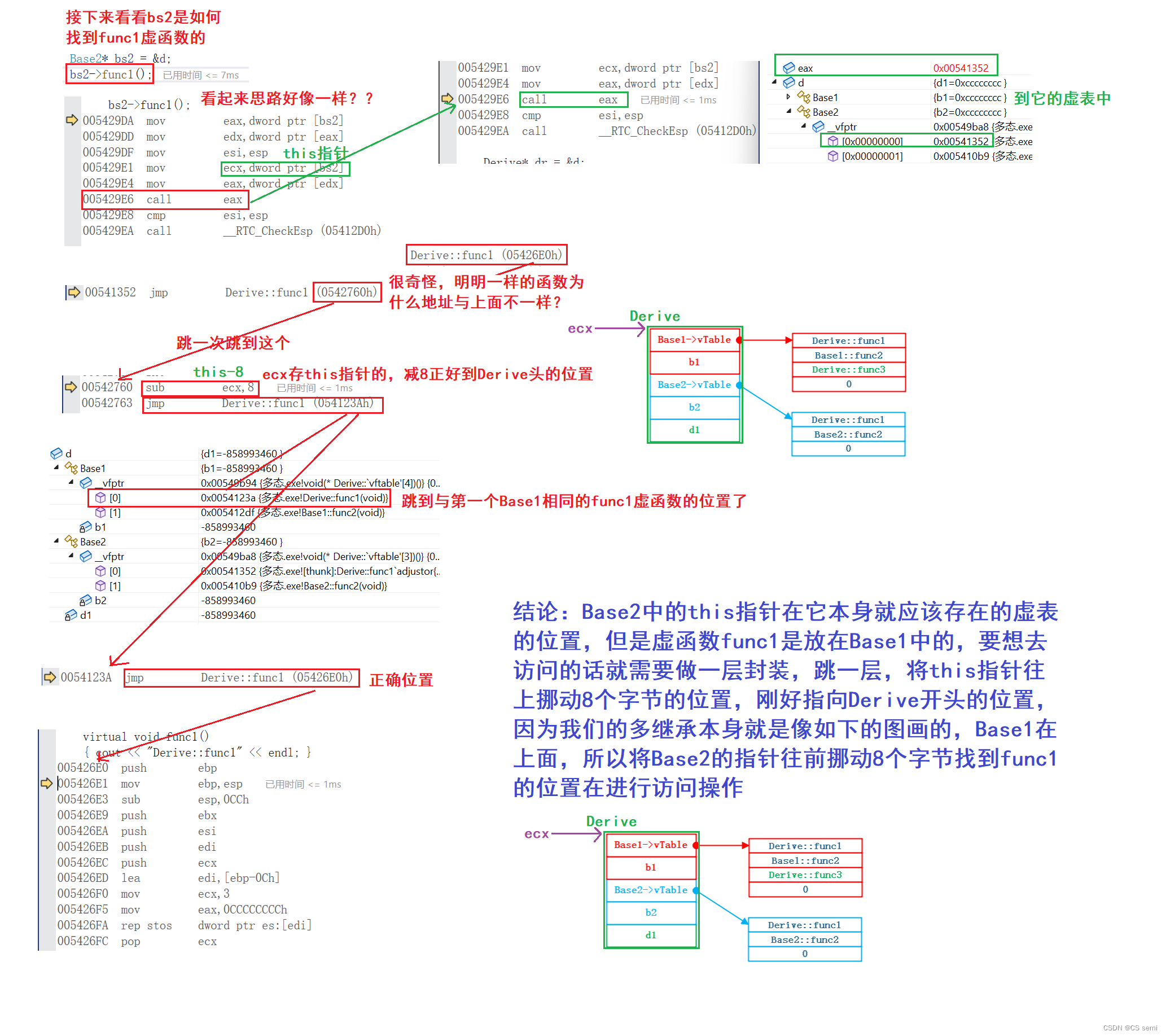
3、多态的底层原理

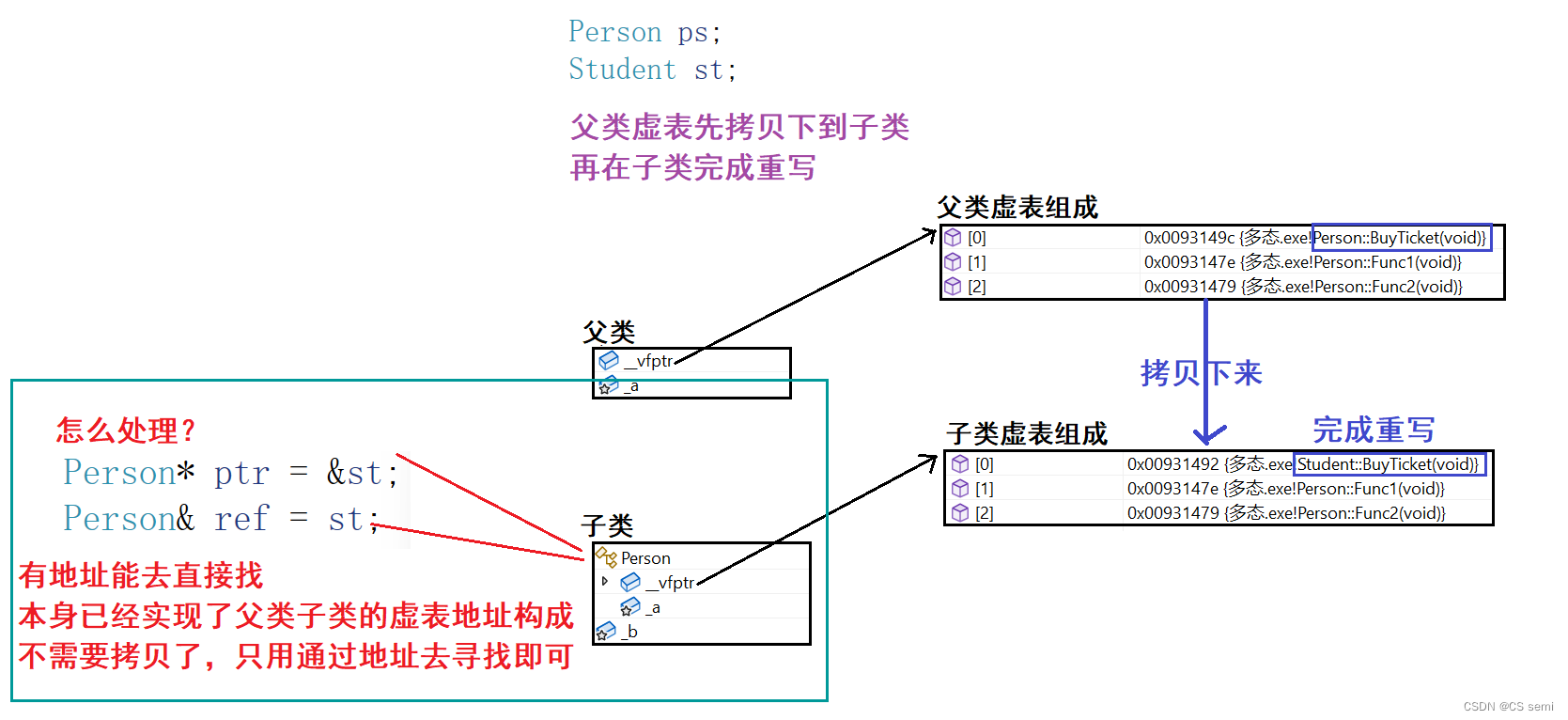
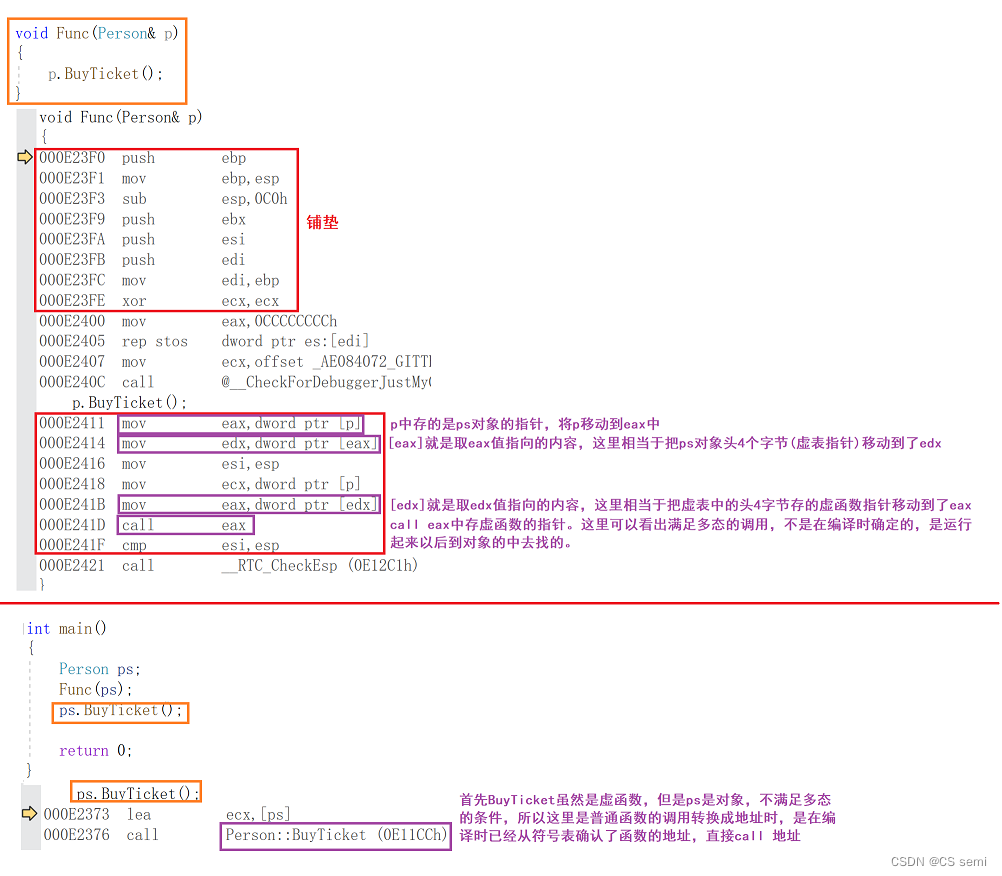
- 观察下图的黄色箭头我们看到,p是指向ps对象时,p->BuyTicket在ps的虚表中找到虚函数是Person::BuyTicket。
- 观察下图的蓝色箭头我们看到,p是指向st对象时,p->BuyTicket在ps的虚表中找到虚函数是Student::BuyTicket。
- 这样就实现出了不同对象去完成同一行为时,展现出不同的形态。
- 要达到多态,有两个条件,一个是虚函数覆盖,一个是对象的指针或引用调用虚函数。
- 再通过下面的汇编代码分析,看出满足多态以后的函数调用,不是在编译时确定的,是运行起来以后到对象的中去找的。不满足多态的函数调用时编译时确认好的。
4、动态绑定与静态绑定
- 静态绑定又称为前期绑定(早绑定),在程序编译期间确定了程序的行为,也称为静态多态,比如:函数重载
- 动态绑定又称后期绑定(晚绑定),是在程序运行期间,根据具体拿到的类型确定程序的具体行为,调用具体的函数,也称为动态多态。
七、单继承和多继承关系的虚函数表
1、单继承中的虚函数表
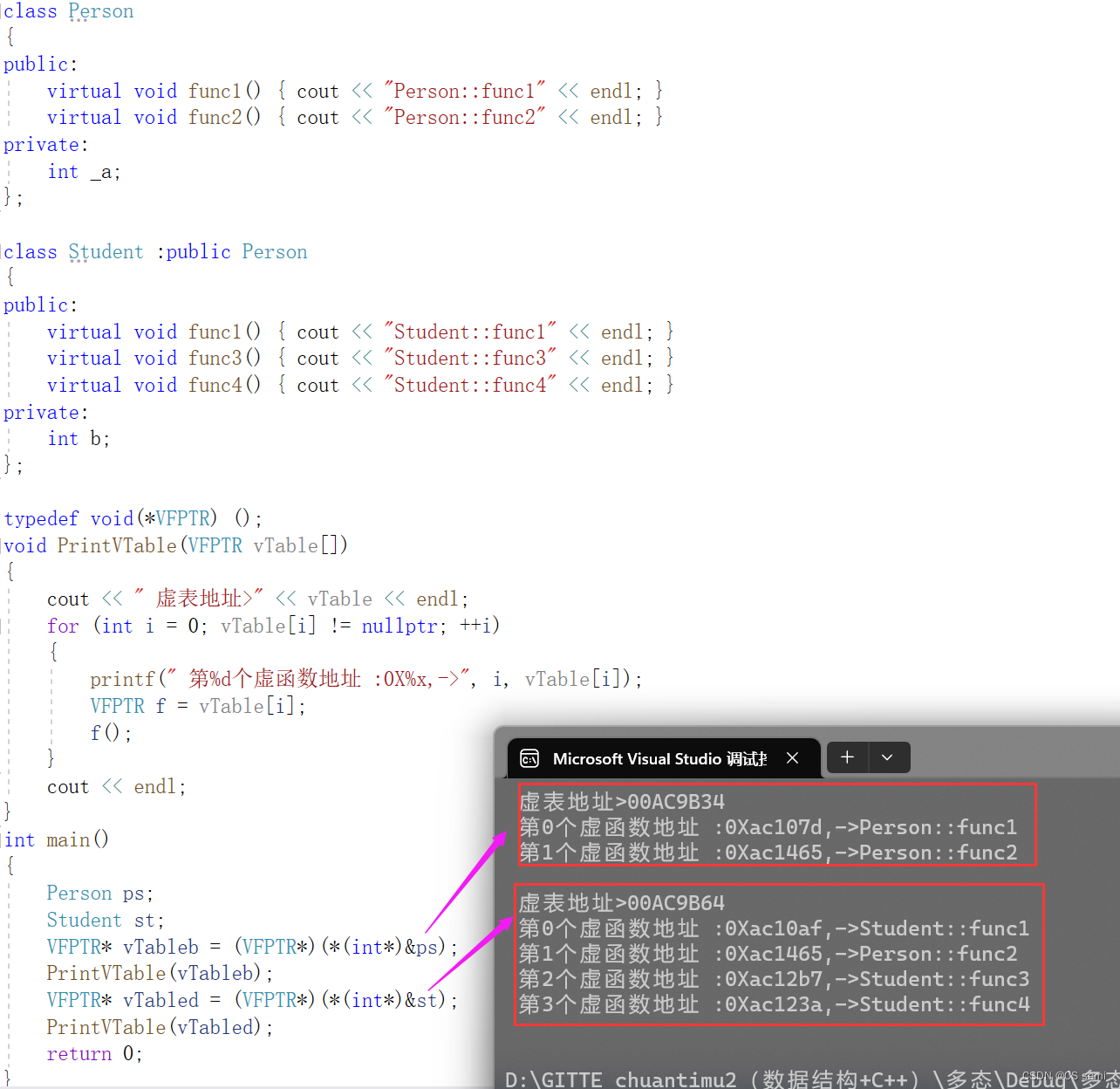
因为虚函数表本质是一个存虚函数指针的指针数组,这个数组最后面放了一个nullptr。
我们本质的思路是先取b的地址,强转成一个int型的指针 再解引用取值,就取到了b对象头4bytes的值,这个值就是指向虚表的指针 再强转成VFPTR*,因为虚表就是一个存VFPTR类型(虚函数指针类型)的数组。 虚表指针传递给PrintVTable进行打印虚表
2、多继承中的虚函数表
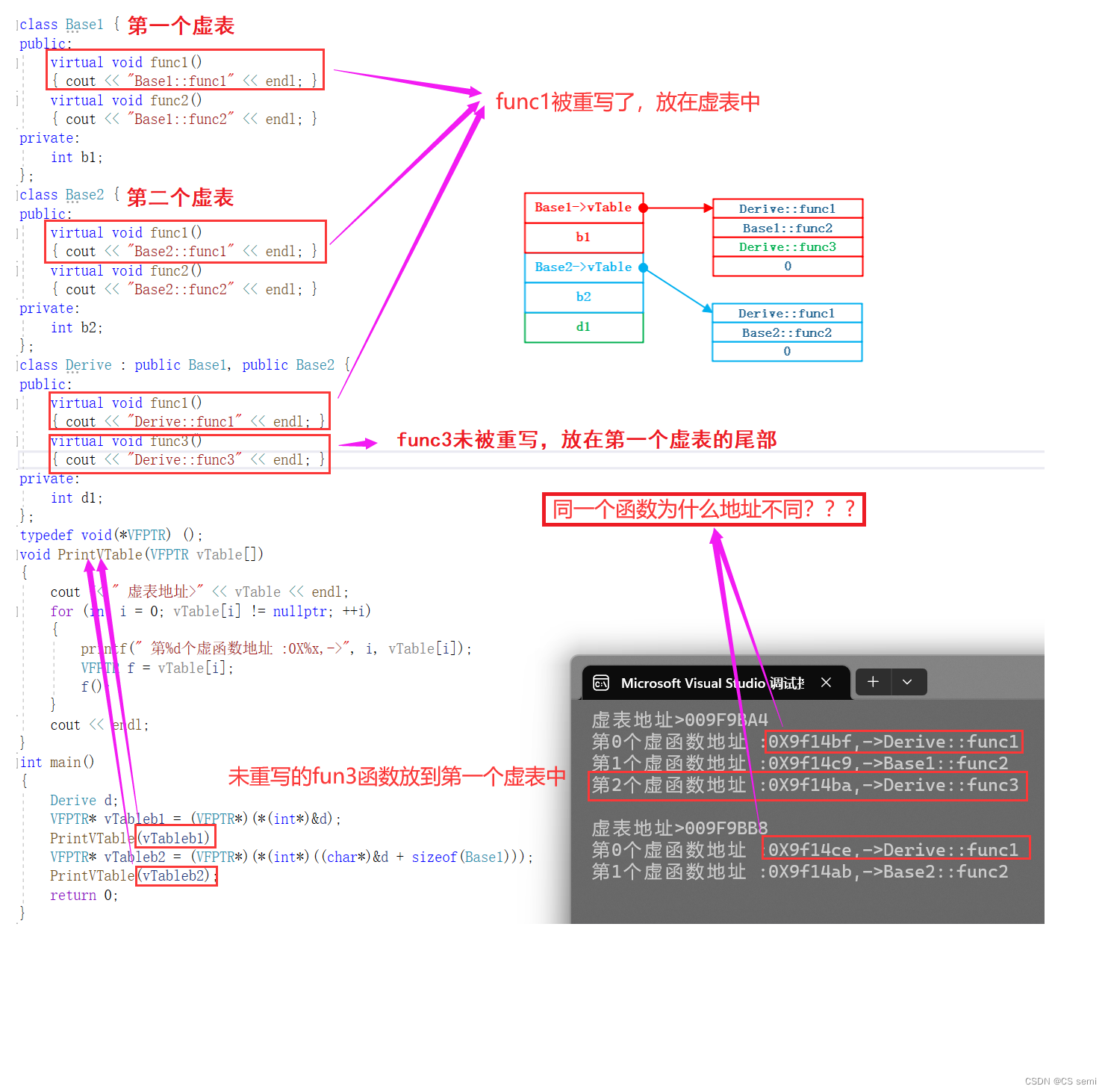
解决为什么同一个函数地址不同的问题(利用汇编):
代码如下:

Base1访问func1虚函数(Derive与其相似):
Base2访问func1虚函数:
3、菱形虚拟继承中的虚函数表

八、面试题
1、子类父类虚函数
以下程序输出结果是什么()

答案及解析:
B->1

2、问答题
- 什么是多态?见本博客的多态的概念章节内容。分为静态多态(函数重载)和动态多态为继承中虚函数重写加上父类指针的引用。
- 什么是重载、重写(覆盖)、重定义(隐藏)?见本博客第四章节三者的比较。
- 多态的实现原理?有函数名修饰规则和虚函数表的概念,具体见多态的原理。
- inline函数可以是虚函数吗?答:可以,不过编译器就忽略inline属性,这个函数就不再是inline,因为虚函数要放到虚表中去。
- 静态成员可以是虚函数吗?答:不可以,因为静态成员函数没有this指针,使用类型::成员函数的调用方式无法访问虚函数表,所以静态成员函数无法放进虚函数表。这样做没有办法实现多态,也就是没有任何意义,所以语法会强制检查。
- 构造函数可以是虚函数吗?答:不能,因为对象中的虚函数表指针是在构造函数初始化列表阶段才初始化的。初始化时间有很大的问题。
- 析构函数可以是虚函数吗?什么场景下析构函数是虚函数?答:可以,并且最好把基类的析构函数定义成虚函数。见本博客第二章节虚函数的概念。
- 对象访问普通函数快还是虚函数更快?答:首先如果是普通对象,是一样快的。如果是指针对象或者是引用对象,则调用的普通函数快,因为构成多态,运行时调用虚函数需要到虚函数表中去查找。
- 虚函数表是在什么阶段生成的,存在哪的?答:虚函数表是在编译阶段就生成的,一般情况下存在代码段(常量区)的。
- C++菱形继承的问题?虚继承的原理?见本博客第七节不同继承的虚函数表。
- 什么是抽象类?抽象类的作用?见本博客第五章。