自己做网站需要收费吗成都小程序开发名录
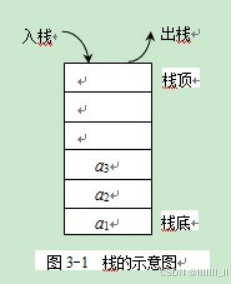
存储结构
1,顺序存储结构
用一组地址连续的存储单元依次存储线性表的各个数据元素, 适用于频繁查询时使用。
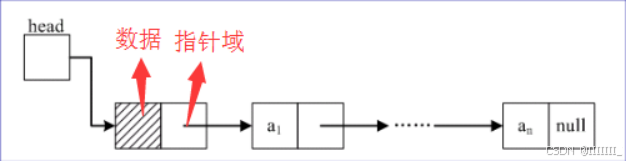
2,链式存储结构
在计算机中用一组任意的存储单元存储线性表的数据元素(这组存储单元可以是连续的,也可以是不连续的),适用于在较频繁地插入、删除、更新元素时使用。
单链表
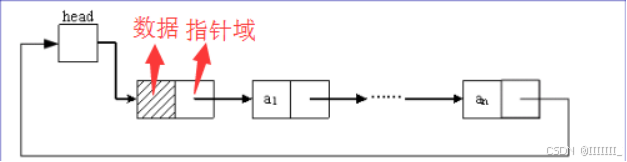
循环链表
双链表
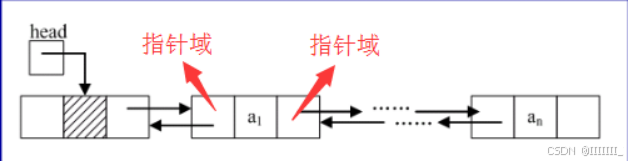
各链表的比较
因为双链表有两个指针域,因此,双链表的灵活度优于单链表,但是双链表的开支要大一些
3,散列存储结构
将数据元素的存储位置与关键码之间建立确定对应关系的查找技术,即键值对。

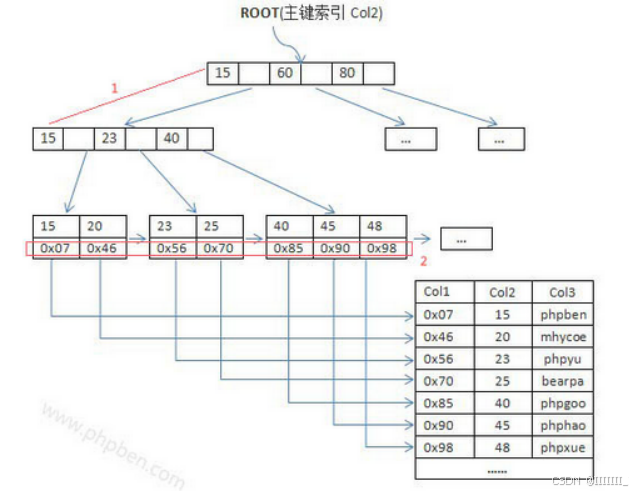
4,索引存储结构
索引是一个单独的、物理的数据库结构,它是某个表中一列或若干列值的集合和相应的指向表中物理标识这些值的数据页的逻辑指针清单。比如数据库