wordpress 4.4漏洞手机端网站优化
上一章我们处理的基本的构建接入,以及插入的处理,那么接下来我们进行查询的操作处理。
我们继续在IoTDBSessionConfig工具类中加入查询的方法处理
/*** description: 根据SQL查询最新一条数据* author:zgy* @param sql sql查询语句,count查询语句,一般为count(id) as ct 必须加as* @return*/public Map<String,Object> queryMapData(String sql) {Map<String,Object> rtMap = new HashMap<>();try {SessionDataSet sessionDataSetWrapper = session.executeQueryStatement(sql,timeoutInMs);List<String> columnNames = sessionDataSetWrapper.getColumnNames();List<Map<String,Object>> rtList = packagingData(sessionDataSetWrapper,columnNames);if(!rtList.isEmpty()){rtMap = rtList.get(0);}}catch (Exception e) {logger.error("查询Map返回数据集数据异常,异常SQL>{};:{}",sql,e.toString());}return rtMap;}/*** description: 根据SQL查询最新一条数据* author:zgy* @param sql sql查询语句,查询条件最前面加 last* @param clazz 类* @return*/public IoTDBRecordable queryLastData(String sql, Class<? extends IoTDBRecordable> clazz) {Map<String,Object> rtMap = new HashMap<>();try {IoTTableName iotTableName = clazz.getAnnotation(IoTTableName.class);String tableName = iotTableName.value();SessionDataSet sessionDataSetWrapper = session.executeQueryStatement(sql,timeoutInMs);List<String> columnNames = sessionDataSetWrapper.getColumnNames().subList(1,sessionDataSetWrapper.getColumnNames().size());List<Map<String,Object>> rtList = packagingData(sessionDataSetWrapper,columnNames);for(Map<String,Object> map : rtList){if(map.get(TIMESERIES)!=null){rtMap.put(map.get(TIMESERIES).toString().replace(tableName+".",""),map.get("Value"));}}}catch (Exception e) {logger.error(MSG_SQL,clazz,sql,e.toString());}return JSON.parseObject(JSON.toJSONString(rtMap),clazz);}/*** description: 根据SQL查询最新一条数据* author:zgy* @param sql sql查询语句,查询条件最前面加 last* @param tableName IoTDB表名* @return*/public Map<String,Object> queryLastData(String sql,String tableName) {Map<String,Object> rtMap = new HashMap<>();try {SessionDataSet sessionDataSetWrapper = session.executeQueryStatement(sql,timeoutInMs);List<String> columnNames = sessionDataSetWrapper.getColumnNames().subList(1,sessionDataSetWrapper.getColumnNames().size());List<Map<String,Object>> rtList = packagingData(sessionDataSetWrapper,columnNames);for(Map<String,Object> map : rtList){if(map.get(TIMESERIES)!=null){rtMap.put(map.get(TIMESERIES).toString().replace(tableName+".",""),map.get("Value"));}}}catch (Exception e) {logger.error(MSG_SQL,tableName,sql,e.toString());}return rtMap;}/*** description: 根据SQL查询* author: zgy* @param sql sql查询语句* @param clazz 类.* @return*/public List<?> queryListData(String sql, Class<? extends IoTDBRecordable> clazz) {List<IoTDBRecordable> rtList = new ArrayList<>();try {//获取实体类注释表名IoTTableName iotTableName = clazz.getAnnotation(IoTTableName.class);String tableName = iotTableName.value();//获取查询条件是否是*全查String selectParam = sql.substring(6, sql.indexOf("from")).trim();SessionDataSet sessionDataSetWrapper = session.executeQueryStatement(sql,timeoutInMs);List<String> columnNames = sessionDataSetWrapper.getColumnNames();//判断如果第一个列值为Time时间戳去掉if(Objects.equals(columnNames.get(0),"Time")){columnNames.remove(0);}List<Map<String,Object>> list = packagingData(sessionDataSetWrapper,columnNames);for(Map<String,Object> map : list){//如果是*全查需要进行key值得转换if(Objects.equals("*",selectParam)){Map<String,Object> rtMap = new HashMap<>();//循环进行key值得转换for(Map.Entry<String,Object> it : map.entrySet()){rtMap.put(it.getKey().replace(tableName+".",""),it.getValue());}//map转换实体rtList.add(JSON.parseObject(JSON.toJSONString(rtMap),clazz));}else{//如果不为*则依照别名来查//map转换实体rtList.add(JSON.parseObject(JSON.toJSONString(map),clazz));}}}catch (Exception e) {logger.error("[{}]查询列表数据异常,异常SQL>{};:{}",clazz,sql,e.toString());}return rtList;}/*** 根据SQL查询 List集合* @param sql 查询条件* @param tableName 表名* @return*/public List<Map<String,Object>> query(String sql,String tableName) {List<Map<String,Object>> rtList = new ArrayList<>();try {SessionDataSet sessionDataSetWrapper = session.executeQueryStatement(sql,timeoutInMs);//获取查询条件是否是*全查String selectParam = sql.substring(6, sql.indexOf("from")).trim();List<String> columnNames = sessionDataSetWrapper.getColumnNames();//判断如果第一个列值为Time时间戳去掉if(Objects.equals(columnNames.get(0),"Time")){columnNames.remove(0);}List<Map<String,Object>> itsList = packagingData(sessionDataSetWrapper,columnNames);for(Map<String,Object> map : itsList){//如果是*全查需要进行key值得转换if(Objects.equals("*",selectParam)){Map<String,Object> rtMap = new HashMap<>();//循环进行key值得转换for(Map.Entry<String,Object> it : map.entrySet()){rtMap.put(it.getKey().replace(tableName+".",""),it.getValue());}//map转换实体rtList.add(rtMap);}else{//如果不为*则依照别名来查//map转换实体rtList.add(map);}}} catch (Exception e) {logger.error(MSG_SQL,tableName,sql,e.toString());return rtList;}return rtList;}/*** 封装处理数据* @param sessionDataSet* @param titleList* @throws StatementExecutionException* @throws IoTDBConnectionException*/private List<Map<String,Object>> packagingData(SessionDataSet sessionDataSet, List<String> titleList)throws StatementExecutionException, IoTDBConnectionException {int fetchSize = sessionDataSet.getFetchSize();List<Map<String,Object>> rtList = new ArrayList<>();if (fetchSize > 0) {while (sessionDataSet.hasNext()) {Map<String,Object> rtMap = new HashMap<>();RowRecord next = sessionDataSet.next();List<Field> fields = next.getFields();String timeString = new java.text.SimpleDateFormat("yyyy-MM-dd HH:mm:ss").format(next.getTimestamp());rtMap.put("time",timeString);for (int i = 0; i < fields.size(); i++) {Field field = fields.get(i);// 这里的需要按照类型获取if(field.getDataType()==null||field.getObjectValue(field.getDataType())==null){rtMap.put(titleList.get(i), null);}else{rtMap.put(titleList.get(i), field.getObjectValue(field.getDataType()).toString());}}rtList.add(rtMap);}}return rtList;}1、queryMapData 方法的话就是查询结果为Map集合的处理,比如聚合函数的查询等等。
2、queryLastData 方法为根据SQL查询表中最新的一条记录数,返回实体类。
3、queryLastData 方法为根据sql和表名查询一个Map集合
4、queryListData 根据sql查询一个list实体集合
5、query 根据sql查询一个List<Map>集合
下面为测试代码
System.out.println("1、queryMapData查询......");Map<String,Object> mapOne= iotDBSessionConfig.queryMapData("select count(id) as ct from root.syslog");System.out.println("结果:"+ArrayUtils.toString(mapOne));System.out.println("2、queryLastData 根据sql和实体类查询......");IoTDBSysLog ioTDBSysLog = (IoTDBSysLog) iotDBSessionConfig.queryLastData("select last * from root.syslog",IoTDBSysLog.class);System.out.println("结果:"+ioTDBSysLog.getLogIp()+"-->"+ioTDBSysLog.getCreateTime());System.out.println("3、queryLastData 根据sql和表名查询......");Map<String,Object> mapThree = iotDBSessionConfig.queryLastData("select last * from root.syslog", IoTDBTableParam.SYSLOG_IOT_TABLE);System.out.println("结果:"+ArrayUtils.toString(mapThree));System.out.println("4、queryListData 根据sql查询一个list实体集合......");List<IoTDBSysLog> list = (List<IoTDBSysLog>) iotDBSessionConfig.queryListData("select * from root.syslog",IoTDBSysLog.class);System.out.println("结果条数:"+list.size());for (IoTDBSysLog sysLog : list){System.out.println(sysLog.getLogIp()+"-->"+sysLog.getCreateTime());}System.out.println("5、query 根据sql查询一个List<Map>集合......");List<Map<String,Object>> listTwo = iotDBSessionConfig.query("select * from root.syslog", IoTDBTableParam.SYSLOG_IOT_TABLE);System.out.println("结果条数:"+list.size());for (Map<String,Object> map : listTwo){System.out.println(map.get("logIp")+"-->"+map.get("createTime"));}结果如下
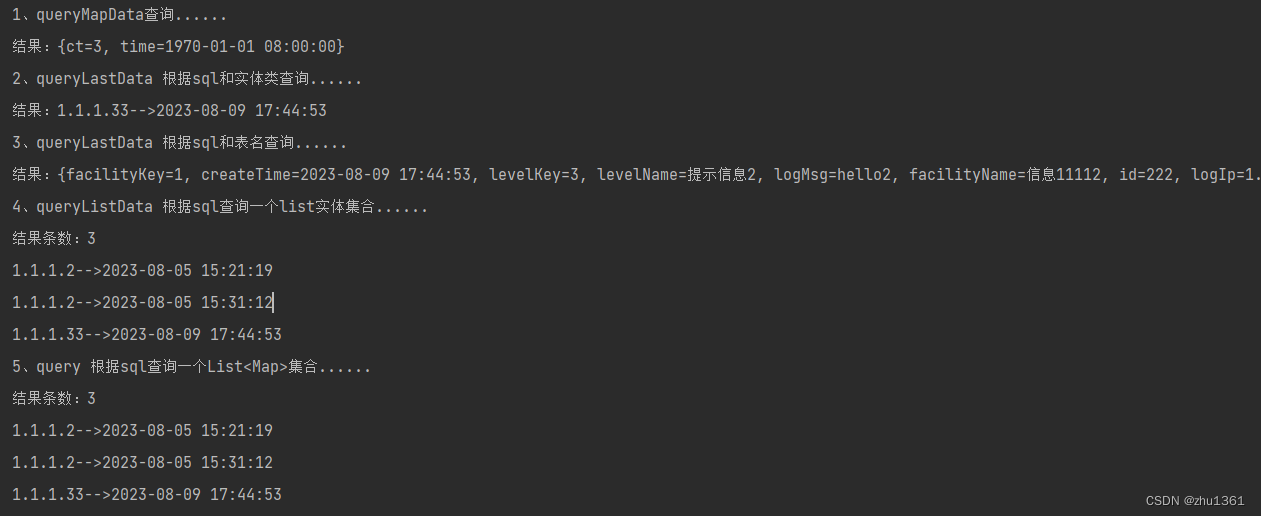
其中3,5两个方法是因为项目中需要进行添加的,是根据动态传递的参数来识别对应的表名,简单进行了包装处理,如果搭建有更好的方法可以留言交流。