临沂城乡建设管理局网站wordpress恶意注册
一 、系统概述
安卓移动应用开发作为新一代信息技术的重点和促进信息消费的核心产业,已成为我国转变信息服务业的发展新热点:成为信息通信领域发展最快、市场潜力最大的业务领域。互联网尤其是移动互联网,以其巨大的信息交换能力和快速渗透能力,通过定向整合生产要素,来扩展新的创造空间,从而改造甚至兼并传统产业的发展模式。国家出台“互联网+”行动计划,实施“中国制造2025”等政策引领国内互联网+产业发展,移动互联网用户规模发展迅猛,带动软件、存储和显示等产业发展,借助政策和发展东风,互联网+背景下,移动互联网大有可为。
安卓移动应用开发,就是将移动通信和互联网二者结合起来,成为一体。是指互联网的技术、平台、商业模式和应用与移动通信技术结合并实践的活动的总称。
安卓移动应用开发主要研究移动应用软件开发与测试等方面基本知识和技能,进行移动应用软件编程、测试、维护与销售等。例如:抖音、美图、天气等APP软件的开发与测试,软件的功能设计、界面设计及测试优化等。
安卓移动应用开发也称为手机应用开发,或叫做移动互联网应用开发,移动开发等。是指以手机、PDA、UMPC等便携终端为基础,进行相应的开发工作,由于这些随身设备基本都采用无线上网的方式,因此,业内也称作为无线开发。移动应用包括早期的WM掌上助理设备,Web os设备、java设备、塞班设备,以及现在现在火热的安卓和苹果设备等移动应用的开发。移动应用的形成对移动设备的功能有了长足的拓展。设备可以不单单只靠自带的简陋功能,而是可以像计算机一样通过安装应用程序、游戏程序等进行扩展,使移动设备成为更能帮助人们解决事物的个人智能终端。安卓移动应用开发是为小型、无线计算设备编写软件的流程和程序的集合,像智能手机或者平板电脑。安卓移动应用开发类似于Web应用开发,起源于更为传统的软件开发。但关键的不同在于移动应用通常利用一个具体移动设备提供的独特性能编写软件。例如,利用iPhone的加速器编写游戏应用。
随着智能手机的大力推广和普及,推动着移动互联网市场规模的进一步扩张,用户规模不断攀升。截至2022年3月,中国手机网民规模达8.97亿,较2020年底增长7992万。移动互联网月活跃用户规模同比增长率下降。与此同时,2021年我国移动互联网接入流量消费达1220亿GB,同比2018年增长71.6%;月户均流量(DOU)达7.82GB/户/月,是上年的1.69倍;短视频应用更成为流量增长的主要拉动力,移动用户2019年使用抖音、快手等短视频应用消耗的流量占比超过了30%。
二、安卓移动应用开发实训室介绍
安卓移动应用开发实训室是一个旨在提供实践环境和教学资源的综合实训室。安卓移动应用开发实训室的目标是为学生提供一个真实的安卓移动应用开发环境,使他们能够学习并实践安卓移动应用开发的相关技术和方法。
安卓移动应用开发实训室建设方案系统是一个集硬件、软件和教学资源于一体的综合实训室,安卓移动应用开发实训室的建设旨在为学生提供一个实践和交流的平台,让他们通过实际项目的开发来应用所学的知识,培养解决问题和合作的能力,同时也促进创新和创业精神的培养。这样的实训室可以提升学生的实践能力,并为他们将来投身安卓移动应用开发行业做好准备。
安卓移动应用开发实训室以安卓移动应用开发领域学习者的职业生涯发展及终身学习需求为依据,重点满足职业院校在校学生、进修教师、企业员工、社会自学者四类对象不同层次的学习需求,联合全国高水平院校以及企业,建设安卓移动应用开发专业优质专业资源、课程资源、认证资源、竞赛资源.企业资源等内容:优化资源库平台,在“能学、辅教”的基础上,满足个性化学习者私人定制的实际需要,并完善平台的运行机制,保证平台内容的持续更新: 依托资源库平台,实现学生学习效果评价,能够为企业出具学生能力分析报告,指导企业招聘和学生就业。
三、安卓移动应用开发实训室组成
3.1安卓移动应用开发实训装置
安卓移动应用开发实训装置是面向中职、高职、本科多层次高校移动互联应用专业和移动互联实训室建设的实验平台,采用模块化的设计模式,可以根据实际需求选配各种模块组建具有行业特色的移动互联工程实训室,与实际应用紧密结合,覆盖移动互联的主要技术,包括嵌入式技术,RFID技术,无线传感网、蓝牙、WiFi、GPRS等各种通信组网技术,以及各种移动互联应用系统。
3.2安卓移动应用开发教学平台
平台基于spring cloud微服务架构,提供便捷的SSO单点登录,采用kubernetes进行部署,可支持公有云、混合云、私有云的安装模式,数据层使用MySQL集群和MongoDB集群,实现了全流程EdvOps自动化运维,具有高内聚、松耦合、业务单一、高性能、高并发、高可能、跨平台、跨语言等特点。主要模块有课程制作工具、云盘、共享课、我的课、云优选课、云视频库、3D模型库。
课程制作工具:由平台提供专用的微服务模块进行支撑,采用websocket双向通信技术,底层存储采用三层递进的缓存方式,目的就是为了加快课程资源的加载速度。自主研发视频转码,在线视频剪辑功能。支持由word文档直接导入,并且根据标题类型自动生成目录,方便快捷。同时支持ppt、excel、图片、超链接、视频、音频、3D模型、章节测验等内容的插入,实现多个超文本文件的同屏展示。
共享课:使用订单配发或校内共享的概念,让课程资源更大程度的进行共享。
我的课:支持从共享课资源中直接进行“生成副本”,导入进我的课中,并且同时支持自行创建。所有的课程资源支持导出功能,可导出为本地的离线文件,导出文件为后缀名为wz的加密文件,在使用平台进行二次导入直接生成课程资源,便于线上传播。
云优选课:由行业资深从业人员在互联网上收集整理的学习资源,包括系列类学习视频和知识点类学习视频,供教师和学生进行自主学习。
云视频库:平台提供数百个包含各专业的微课视频,可直接引用到课程资源中。
3D模型库:采用three.js技术,实现在线加载3D模型,提供更加直观形象的教学体验。
题库:题库支持通用题目(单选题、多选题、判断题、填空题、主观题)以及实训题目(编程题、web前端题、虚拟化题等);对于通用类题目可采用excel模板批量导入,采用瀑布流的展示方式,可共享到校内供其他教师进行使用。
作业:支持手动建题和从题库中选题两种模式创建作业,提供作业库模块,作业库内的作业可多次发放给学生,对于作业平台提供自动评测,包括单选题、多选题、判断题、填空题、编程题、虚拟化题。
考试:支持导入试卷、手动创建、题库选题三种创建方式,同时支持系统随机组卷功能;提供试卷库模块,试卷库内的试卷可多次发放给学生,支持试卷的自动判分。
课堂活动:平台支持多种课堂活动,如:签到、主题讨论、提问、分组任务、投票、问卷、计时器等,提高课堂的趣味性和参与性。
个人云盘:平台将用户在备课,教学等过程中使用的文件,保存在个人云盘空间,支持二次直接使用和存档,实现云文件的保存。
3.3安卓移动应用开发实训平台
平台采用B/S结构,运用spring cloud微服务技术,构建多个稳定、高效的服务模块,提供SSO单点登录服务,并使用统一的身份认证鉴权。平台基于k8s实现公有云、混合云、私有云多种部署方式,提供在线安卓移动应用开发的运行环境,并内置代码运行结果检测,自动进行测评统计,实现真正的云开发,开箱即用,主要模块有课程制作工具、作业、活动、云盘、共享课、我的课、云优选课。
便捷的实验制作工具:让教师轻松实现pdf、ppt、word、excel等不同格式的文本、图片、音频、视频、超链接等进行混合编排,并自动生成动态实验目录,从而实现不同实训资源同屏展示。
智能代码评测,助力安卓移动应用开发实训:平台支持在线对学生提交的实验代码进行评测,将评测结果统计分析后展示给教师,提高教师的教学效率,方便学生的学习过程。
提交代码查重,防止抄袭:对于学生提交并且通过测评的安卓移动应用开发实训代码进行代码的查重,防止学生互相抄袭代码。
在线问答,及时解答学生疑问:平台提供安卓移动应用开发实训的在线问题,学生在安卓移动应用开发实训过程中,通过在线问答及时与老师进行沟通,提高学习效率。
可记录学习情况的实验笔记:平台为用户在安卓移动应用开发实训页面提供实验笔记功能,用户可在实验过程中记录下自己的笔记。
实验题解,帮助学生掌握实验知识点:平台会在每个安卓移动应用开发实训题目后面,提供相应的实验题解,教师可改变其是否展示给学生。从而让学生在实验完成之后进行学习,更好的掌握实验的知识点。
支持高并发的评测服务:平台采用kafka消息队列来处理评测的请求,并内置高配置的底层沙箱服务,支持高并发的用户同时使用。
学生测评结果自动统计:平台将课堂内的用户的评测结果进行统计,按照消耗内存、消耗时间两个维度进行展示,从而直观的展示该实验的整体评测数据。
支持公共资源课程,便于老师教学:安卓移动应用开发实训平台可内置完整的实训资源,其中包括实训文档以及在线资源包,用户可以直接进行使用。
个人云盘,资源不丢失:平台会为用户提供云盘服务,云盘内所有文件都会按照不同的文件类型进行分开,便于用户查看和操作。
平台支持移动应用程序开发、web企业级开发、数据库设计等实验。
3.4安卓移动应用开发教学资源包
安卓移动应用开发教学资源包包含专业基础课程:移动端 UI 设计、网页设计与制作、响应式 Web 程序开发、交互式 编程语言基础、面向对象程序设计、数据库技术应用。专业核心课程:面向对象建模与设计、移动端应用开发、移动端跨平台技术、小程序开发、移动端项目开发实战、移动端应用测试技术、服务端框架技术。
3.5安卓移动应用开发实训资源包
对接真实职业场景或工作情境,在校内外进行移动端 APP 开发、移动端 Web 开发、小程序开发等实训。
使学生掌握网页设计与制作的技术,能够利用HTML5、CSS3等技术进行网页布局,基于项目化教学的模式培养学生实践动手能力;使学生了解JavaScript的基本语法,具备JavaScript的编程技巧和编程步骤;使学生掌握了Android框架、Android组件、用户界面开发、用户界面布局、四大基本组件、XML解析方式及区别、数据存储等基础知识、具备Android应用开发的能力;使学生掌握了Android网络应用中的HTTP数据通信、URL处理数据、处理XML数据、下载远程数据、上传数据、使用WebView浏览网页数据等知识,具备Android网络开发的能力。
3.6安卓移动应用开发实训室配套设施
安卓移动应用开发实训室配套设置包含实训室硬件设施、安卓移动应用开发软件和工具等内容,其中硬件设施如智慧黑板、教师讲台、多媒体设备、学生实训电脑、桌椅、服务器、交换机、机柜及安卓移动应用开发实训室装修和安卓移动应用开发文化建设。安卓移动应用开发软件和工具应包含常用的安卓移动应用开发软件和工具,如Android Studio、Xcode等。这些安卓移动应用开发软件和工具可以帮助学生进行应用程序的编写、测试和调试。
四、安卓移动应用开发实训室建设图

五、安卓移动应用开发实训室方案清单

六、安卓移动应用开发实训室方案价值
6.1方案价值
6.2教材联合开发教材
联合各院校教授专家,开发安卓移动应用开发专业系列教材,为院校专业实验课程开展和教学提供参考。
6.3 产学研支撑平台
平台采用spring cloud微服务开发架构,各服务模块单独运行并提供服务接口;可提供稳定、快速、高效的服务;平台整体采用前后端分离和分布式微服务的弹性计算架构实现,后端主要基于Java的Spring cloud实现,前端vue实现等,具有高内聚、松耦合、业务单一、高性能、高并发、高可能、跨平台、跨语言等特点。
平台提供SSO单点登录,多个应用系统统一登录,统一的用户管理,一个账户可登录验证教学全场景以及数字技术专业群实践教学等所有应用模块系统。
平台采用kubernetes技术进行部署,支持公有云、私有云、混合云模式安装;平台支持多数据源从而保证技术的一致性;确保服务的稳定、可扩展、弹性扩容;每个独立服务支持分布式集群部署,理论上可以无限横向扩展,提高系统处理能力,支持大规模并发教学全场景和数字化专业群教学实践应用。
基础虚拟化服务由docker和kvm两种虚拟化技术根据学科性质进行选择性支撑,可满足不同的虚拟化需求,提供稳定、可自行配置的虚拟机器。
基于全流程DevOps自动化运维,支持持续集成、分析、服务注册与发现、系统监控、性能监控、日志管理、预警、持续部署(基于docker的镜像仓库,Kubernetes的容器云管理调度平台,在线可视化管理、监控、调度容器)。
基础持久化层支持RDS和NoSQL两种方式,采用MySQL集群和MongoDB集群搭建,支持基于CQRS的分布式事务处理,支持数据自动备份,同时使用于Redis集群对热点数据进行缓存,支持大并发;支持纯本地化数据源。
基础服务层支持在线验证码服务、基础文件服务、消息队列服务、OSS对象存储服务、用户/鉴权服务、个人云盘服务、WebSocket服务等,保证平台的通用性。用户基础信息管理:对订单实行按业务方向进行配置,对班级、教师、学生相关信息进行新增、修改、删除以及数据权限进行配置。
6.4 技能大赛支撑
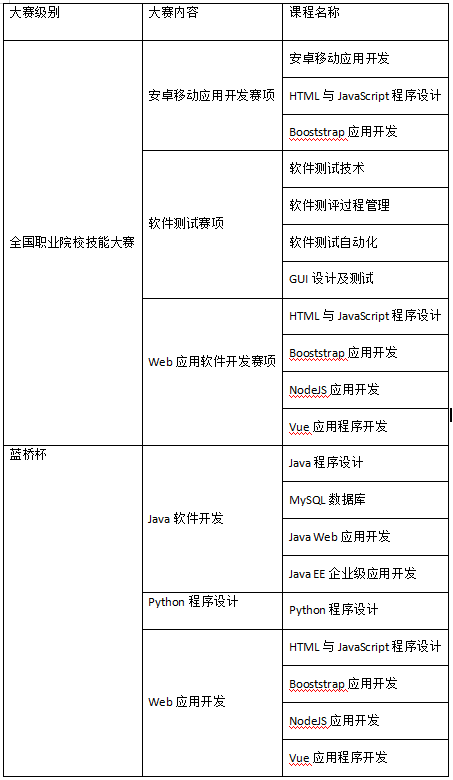
物联网技术应用与维护


安卓移动应用开发赛项内容

嵌入式应用开发赛项内容

5G技术应用开发大赛
2020年中国通信学会举办,大唐多络承办的“中国大学生5G技术应用开发大赛”中,武汉唯众将作全面技术支持服务。
一带一路金砖国家技能发展与创新大赛
