PHP网站开发成功案例张家港保税区建设规划局网站
1.整理磁盘操作的完整流程,如何接入虚拟机,是否成功识别,对磁盘分区工具的使用,格式化,挂载以及取消挂载
U盘接入虚拟机
在虚拟机--->可移动设备--->找到U盘---->连接
检测U盘是否被虚拟机识别
ls /dev/sd* 查看到的有除了sda外的内容,说明U盘连接成功 sda指的是当前虚拟机自己的磁盘空间
查看磁盘的使用情况
df -h 当U盘没有被挂载在具体的目录下时,不能被df -h查找到的
给磁盘分区
fdisk ---->工具用于磁盘分区 m:获取帮助信息 p:打印已有的磁盘分区 d:删除已有的磁盘分区 n:新建磁盘分区 w:将操作写入磁盘并保存 q:不写入磁盘保存 如果输入w后,显示设备或资源忙,先取消挂载,再分区
格式化分区
mkfs ---->make file system
(格式化的空间尽量小)
对具体的分区进行格式化操作 sudo mkfs.ntfs /dev/sdb1 ---->ntfs是要格式化的目标文件类型
挂载
挂载的作用:Linux下不像Windows一样,可以直接对磁盘进行操作,但是可以将磁盘分区挂载在具体的目录下,作用:对目录的操作相当于对磁盘的操作。
sudo mount 挂载的分区 挂载点(已有的一个目录) ---->最好新建一个空目录
取消挂载: (既可以通过挂载点取消挂载,也可以通过挂载分区取消) sudo umount 挂载点名 sudo umount 挂载分区
2.复习cp、mv和find指令
cp 当前的文件位置 复制到哪个位置
格式 : cp 路径/文件 路径/目录名/重新命名的目录名
示例: cp ./2.c ./1
mv 当前的文件位置 复制到哪个位置
格式 : mv 路径/文件 路径/目录名/重新命名的目录名
示例: mv ./2.c ./1
find 在指定目录下,查找文件
查找文件 find 目标路径 -name 文件名
后续写项目时,文件较多,不容易查找,使用find可以快速查找到目标文件
find可以进行模糊查找
find 目标路径 -name xxx* 关于*转义的问题,如果不转义(加\)报错,就转义 如果转义报错,就不转义
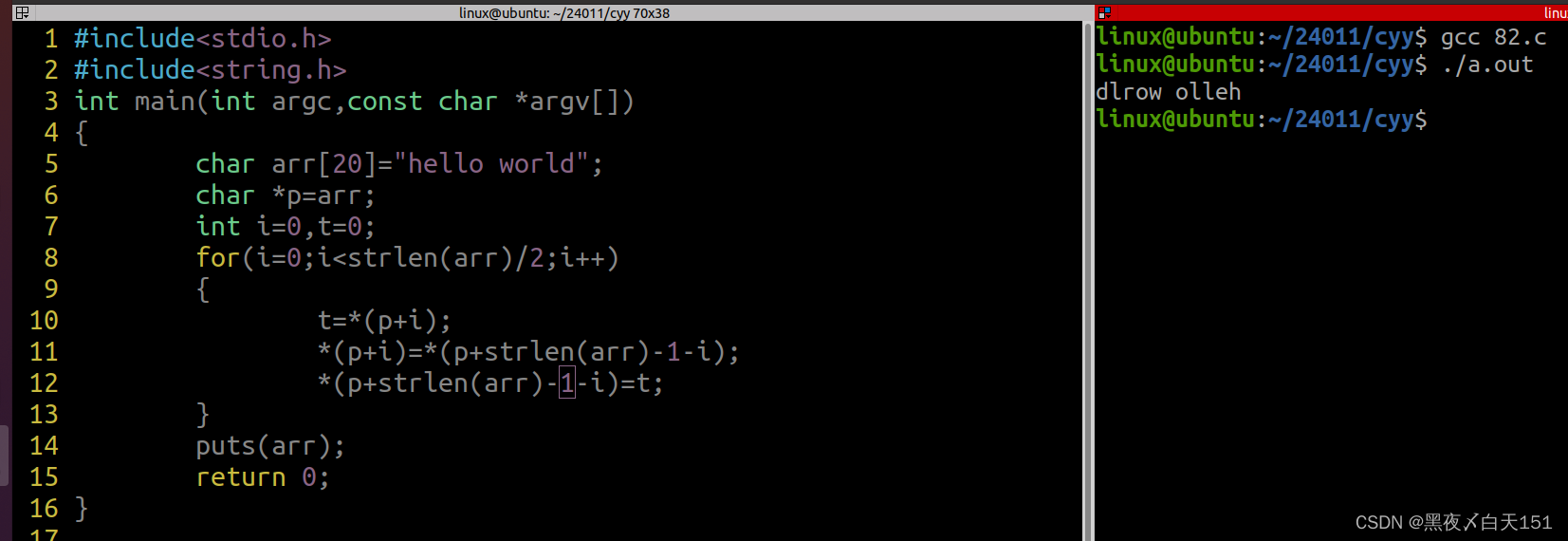
3.使用指针完成字符串逆置
代码:
#include<stdio.h>
#include<string.h>
int main(int argc,const char *argv[])
{
char arr[20]="hello world";
char *p=arr;
int i=0,t=0;
for(i=0;i<strlen(arr)/2;i++)
{
t=*(p+i);
*(p+i)=*(p+strlen(arr)-1-i);
*(p+strlen(arr)-1-i)=t;
}
puts(arr);
return 0;
}