什么网站百度容易收录网站建设费属哪个费用
获取源码或者论文请私信博主
演示视频:
基于微信小程序的中医体质辨识文体活动的设计与实现(Java+spring boot+MySQL)
使用技术:
前端:html css javascript jQuery ajax thymeleaf 微信小程序
后端:Java springboot框架 mybatis
数据库:mysql5.7
开发工具:IDEA2019
主要功能:
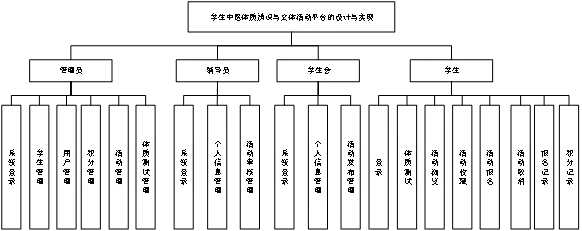
管理员功能需求:
登录:按照输入的要求输入归属的登录账号和自己设置的密码进行登录,登录时页面会进行格式校验,若校验失败则根据失败原因做出对应的提示。
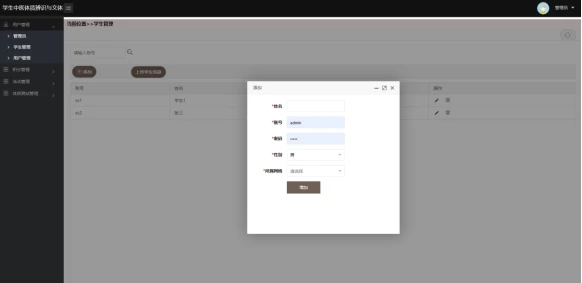
学生管理:管理员可在此功能下进行学生的信息管理,包括学生姓名、学号、身份证号码、学院、专业等信息的增删改操作。
用户管理:管理员可在此功能下进行辅导员、学生会的信息管理,包括辅导员姓名、身份证号码、学院等信息以及学生会的名称、发布的活动等信息的增删改操作。
积分管理:管理员可在此功能下对学生在报名参加文体活动后修得的积分或减少的积分进行增加或者减少等操作。
活动管理:管理员可在此功能下可对学生会发布的文体活动进行监督管理,比如活动发布的规范性、安全性等。
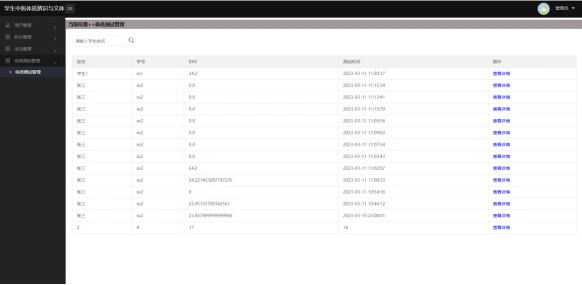
体质测试管理:管理员可在此功能下查看所有学生进行的体质测试结果并进行管理。
辅导员功能需求:
个人信息管理:辅导员可在此功能下进行查看自己的个人信息,例如姓名、身份证号码、学院等信息。
活动审核管理:辅导员可在此功能下进行查看学生会提交的待审批活动,点进去可以查看详细信息并进行活动审批与驳回。
学生会功能需求:
个人信息管理:学生会可在此功能下进行查看自己的个人信息,例如名称、发布的活动、活动审核状态、活动进度等信息。
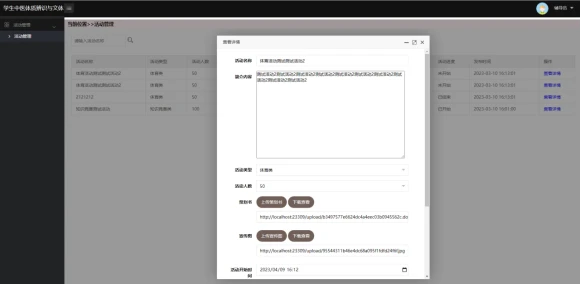
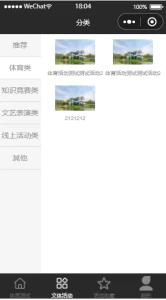
活动发布管理:学生会可在此功能下进行各类文体活动的发布并进行管理,包括活动的名称、类型、起始时间、人数等信息。
学生功能需求:
体质测试:学生可在此功能下进行体质测试并查看体质测试的结果,方便学生了解自己的体质并由此选择适合自身体质的文体活动。
活动浏览:学生可在此功能下浏览学生会发布的各类文体活动的各项具体信息。
活动收藏:学生可在此功能下对学生会发布的各类文体活动进行收藏,以便报名自身感兴趣并适合的文体活动。
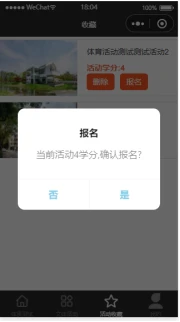
活动报名:学生可在此功能下对自身感兴趣并适合的文体活动进行报名操作。
活动取消:学生可在此功能下对自己已报名的文体活动进行取消操作。
报名记录:学生可在此功能下对自己已报名的文体活动记录进行查看,以便了解报名进度。
积分记录:学生可在此功能下对自己已报名参加完的文体活动进行积分记录查看,以便了解积分的多少。
功能截图: