医药类网站前置审批zion小程序开发
ArcMap 分享统计点要素、路网等功能等功能操作今天进行
一、按格网统计点要素

1、创建公里网格统计单元

点击确定后展示

打开连接

点击后

展示

2、处理属性
1)查看属性表

每个小格都统计出了点的数量
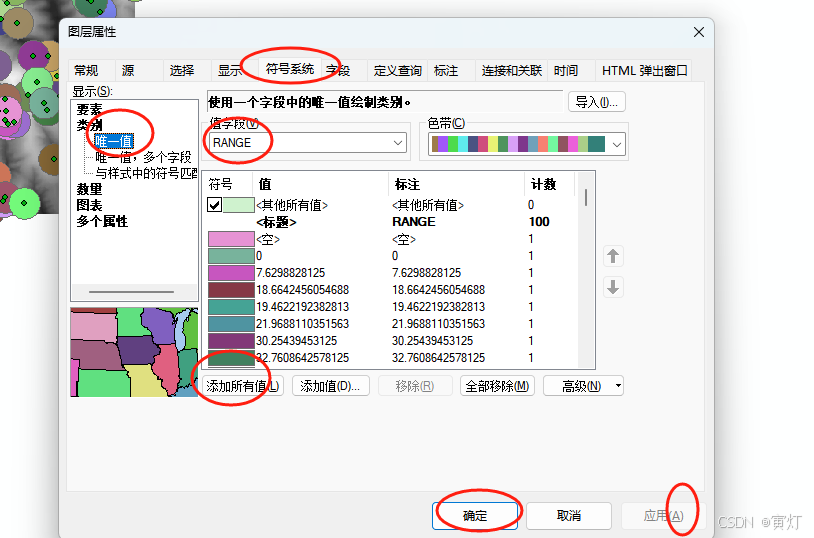
2)查看属性 符号系统

点击应用后展示结果,然后点击确定后即可完成。
二、按要素区分统计路网

目的是在全国不同的区域统计出道路的信息。

默认没有公路信息。
1、标识公路数据

点击确定后查看属性表
 2、添加字段
2、添加字段

点击确定

3、计算公路长度

进入

点击确定后展示

4、计算各省公路长度

点击

点击确定
 结构化展示
结构化展示

点击下一步
 点击完成展示各省的长度
点击完成展示各省的长度

三、按栅格分区统计路网

根据到超时的距离划分区域,然后在不同的区域统计出路网的长度。
1、创建直线距离分区

打开环境
 点击确定展示
点击确定展示

2、栅格数据转矢量面

点击确定生成后打开属性表

对应关系

3、标识道路数据

点击确定后查看属性表

统计道路和

点击

点击确定查看属性信息

四、分区统计降雨量

1、导入采样点的数据
打开后展示

添加X\Y

进入

导入坐标系

添加后确定

展示点事件
 导出
导出

展示

点击确定后展示

查看属性表,P 代表降雨量数据

2、生成全区降雨量数据

配置环境变量
 点击确定后展示
点击确定后展示

3、统计管理区降雨量总量

点击确定后展示
 4、统计降雨量总量表格
4、统计降雨量总量表格

点击确定后展示
 5、绘制统计脂肪图
5、绘制统计脂肪图

点击

下一步
 点击完成
点击完成

五、随机采样统计

1、创建随机的分布点

点击确定后

2、创建统计原单位

点击确定展示效果
 3、在缓冲区范围内统计DEM的高程信息
3、在缓冲区范围内统计DEM的高程信息

点击确定

展示参数,总和和高程平均值。
4、数据链接

点击

点击确定,完成链接

5、符号化显示
到此,ArcMap 统计点要素、路网等功能等功能操作分享完成,下篇分享点群空间分析,敬请期待!