珠海专业网站建设价格重庆专业做淘宝网站
一、前言
最近有幸参加了由中国图象图形学学会(CSIG)主办,合合信息、CSIG文档图像分析与识别专业委员会联合承办的“CSIG企业行——走进合合信息”的分享会,这次活动以“图文智能处理与多场景应用技术展望”为主题,聚焦图像文档处理中的结构建模、底层视觉技术、跨媒体数据协同应用、生成式人工智能及对话式大型语言模型等热门话题,特邀来自上海交大、复旦、厦门大学、中科大的知名高校的学者与合合信息技术团队一道,以直播的形式分享文档处理实践经验及NLP发展趋势,探讨ChatGPT与文档处理未来。经过此次会议,让我对AI图像、文档处理方面有了更深刻的理解,下面聊聊我的一些感悟和想法。
二、感悟分享
1)生成式人工智能将在未来成为主流
会议开始,来自上海交大的杨小康教授带来了他的报告《生成式人工智能与元宇宙》
生成式人工智能这个词对于非AI领域的同学一定很陌生,但它就在我们身边,这里给大家简单说明一下:
我们熟知的通过AI进行图像识别、垃圾邮件检测、数据预测、自动驾驶等这些都属于分析或决策式的人工智能,我们给机器大量的数据,建立学习模型,让它们能够比人类更高效精准的完成一些任务。而生成式人工智则是进行“创造”,通过从数据中学习要素,进而生成全新的、原创的内容或产品,它不仅能够实现传统AI的分析、判断、决策功能,还能够实现传统AI力所不及的创造性功能,如今大火的ChatGPT、AIGC都属于生成式人工智能,2021年4月,英伟达公司创始人兼首席执行官黄仁勋的演讲会就有15秒的视频通过生成式人工智能合成的:
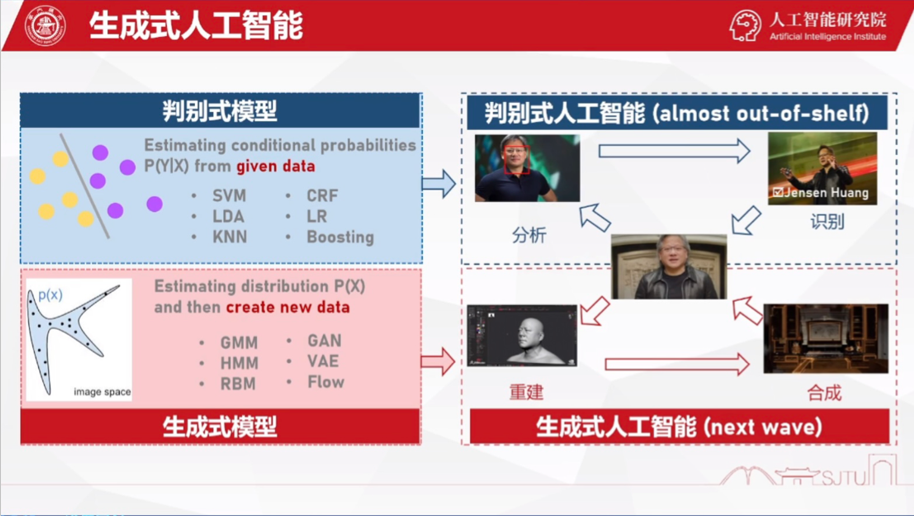
杨小康教授在会议中首先分享了他们对元宇宙和生成式人工智能发展趋势和价值:
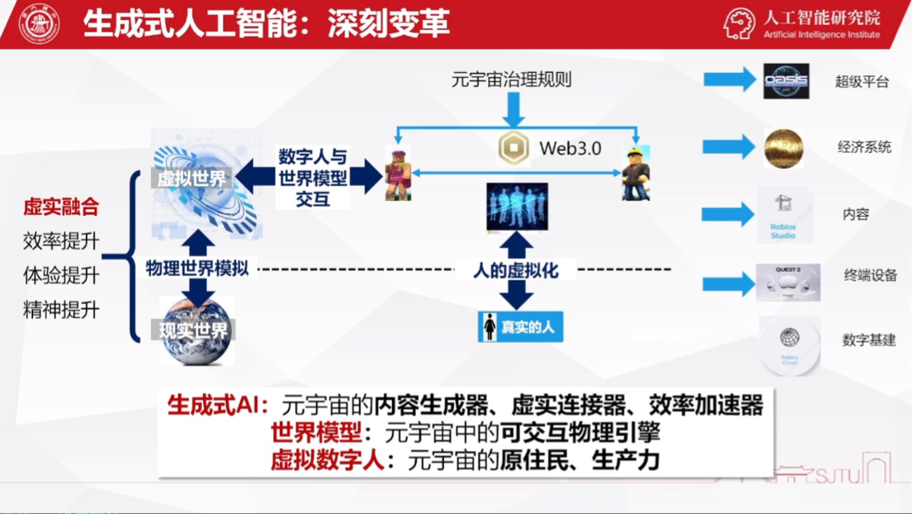
然后介绍他们在流体现象模拟推理、物理环境持续预测学习、强化学习中世界模型表征解耦、虚拟数字人重建与驱动等方面的生成式人工智能取得成果:
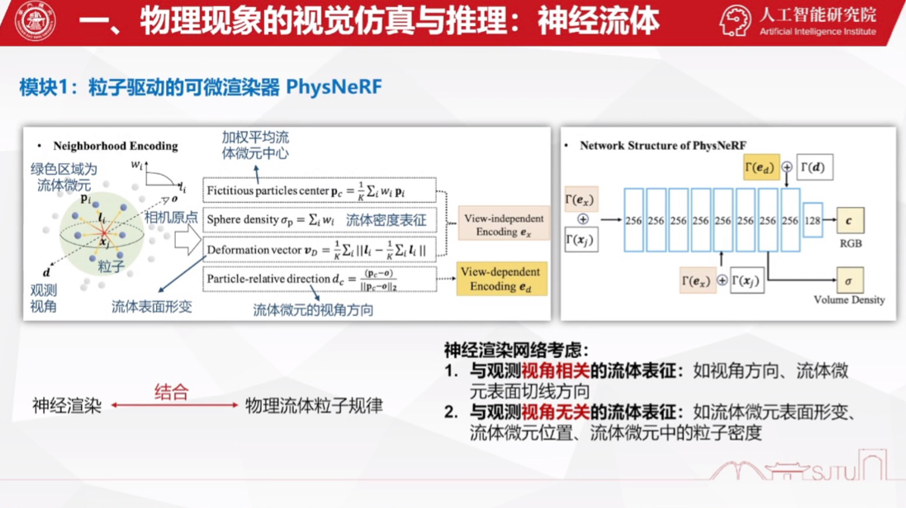
并表示,目前的生成式人工智能还存在解空间巨大、宏观一致性差、微观清晰度受限等问题,需要通过数学、物理、信息论、脑认知、计算机等学科交叉研究,进一步夯实生成式人工智能的基础理论,通过“物理+数据”联合驱动, “虚拟+现实”深度融合,助力科学发现的加速。
随着人工智能技术的飞速发展,生成式AI仿佛一股清流般涌入了人类的日常生活,充满创造力的新世界就此呈现在我们的眼前。
据国际IT研究机构Gartner预测,到2025年,生成式人工智能产生的数据将占据人类全部数据的10%。可以明显的看到,生成式人工智能技术正加速数字经济的发展,生成型人工智能已经成为一个重要的研究领域,因为它能够弥合物理世界和数字领域之间的差距。它的重要性在于它能够将现实世界中的结构、操作和规则映射到计算机模型中,从而使计算机能够模仿人类的行为。此外,它在各个行业的应用表明了它改变我们生活的潜力。展望未来,这一领域的研究可能会集中于“新智能”模型,如转移学习、深度强化学习和贝叶斯优化,以及基于大数据和无监督学习技术的应用。
我很赞成杨小康教授的一个观点就是:生成式人工智能是构建元宇宙的一个可行的途径。而且在不久的将来,以“识别——分析”为代表的判别式人工智能将被“合成——重建”为代表的生成式人工智代替而成为主流。

另外,复旦大学计算机学院教授邱锡鹏也对ChapGPT大语言模型的关键技术进行了深度剖析,他从大规模预训练语言模型带来的变化、ChatGPT 的关键技术及其局限性等角度深入地介绍了大规模语言模型的相关知识:

也指出了ChatGPT目前最大的问题之一:作为大型语言模型,它无法实时与外部世界互动,也无法利用如计算器,数据库,搜索引擎等外部工具,导致它的知识也相对落后,而未来它更应该做到提高适时性、即时性、无害等等。总的来说,如果将 LLM 作为智能体本身,能够与外部交互之后,这些模型的能力一定会有更大的提升!

随着 ChatGPT的大火,很多公司和组织都跟风,推出类似的聊天机器人产品。这也证明了大家认可聊天机器人技术的可行性和潜力,也让人们看到了聊天机器人在未来的巨大市场和应用前景。
2)文档图像处理方向的AI应用还存在巨大的挑战,但也有巨大的行业前景和价值
我们经常提到的图像超分辨率、去模糊、去噪、破损图像恢复等都属于底层视觉应用的范畴,底层视觉的特征非常明显:输入是图像,输出也是图像。比如:图像预处理、滤波、恢复和增强等:

近年来,随着人工智能、深度学习技术的快速发展以及在高层视觉任务上的出色表现,将其应用到底层视觉任务上的工作也逐渐涌现出来。然后面临的问题却很多,效果也不太理想。
来自上海交通大学的模式识别与智能系统博士,合合信息图像算法研发总监郭丰俊表示:底层视觉的理论和方法在众多领域都有着广泛的应用,如手机、医疗图像分析、安防监控等。重视图像、视频内容质量的企业、机构不能不关注底层视觉方向的研究。如果底层视觉没做好,很多 high-level 视觉系统(如检测、识别、理解)无法真正落地。看了他针对目前底层视觉技术在处理形变、模糊、阴影遮盖、背景杂乱的文档时遇到的典型问题,就公司技术团队在智能图像处理技术模块、融合技术典型应用、图像安全领域等领域的研究成果进行的分享后我深表赞同。
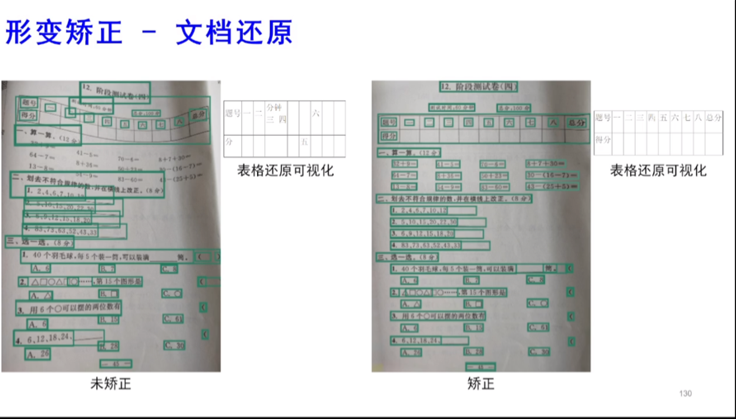
之后他介绍了合合信息智能文档处理技术基于对图像目标区域的精准裁剪,对弯曲、倾斜透视的页面进行形变矫正,在去除阴影、摩尔纹后,通过人工智能技术对文档图像进行增强锐化和清晰度提升,能达到“图像质量增强”的效果,在改善阅读体验的同时,也提升了识别转换、图像分析等文档处理下游任务的质效,相关技术已通过“扫描全能王”等智能文字识别产品,服务全球上百个国家和地区的上亿用户:

去年我也使用过合合科技的PS检测合摩尔纹去除等服务,效果都很不错,特别是PS检测上,这一直是很多行业迫切需要解决的难点,特别是在保险、金融、银行等领域,如果将虚假篡改过的信息资料审核通过可能会带来巨大的影响甚至是经济上的损失:

会议中,来自中国科学技术大学语音及语言信息处理国家工程实验室副教授杜俊做的文字识别工作也惊艳到了我。
如果仅仅是标准字体的图文识别,那相对来说很简单,但在很多现实场景中,字不一定会以规范的印刷体的形式出现,这就给字的识别带来了挑战,比如学生作业及试卷的错别字检测,医嘱识别等场景,如果能够通过自动化代替人工来做的话会对效率的提升和数据汇总分析等是特别有价值的。
杜俊教授的团队创建了一套基于部首的汉字识别、生成与评测系统,因为与整字建模相比,部首的组合要少得多:
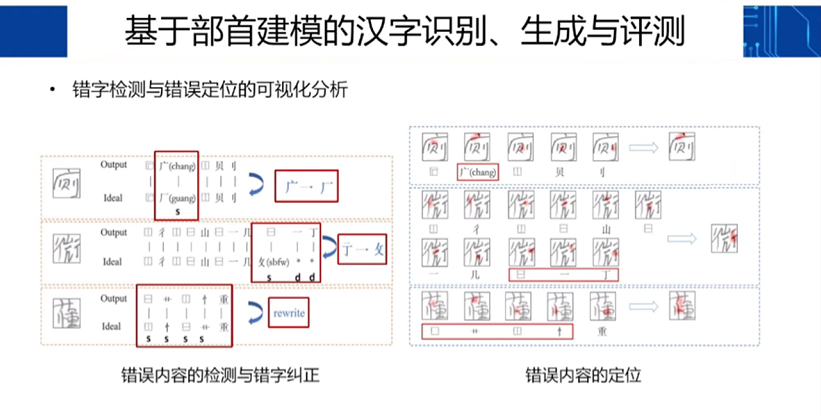
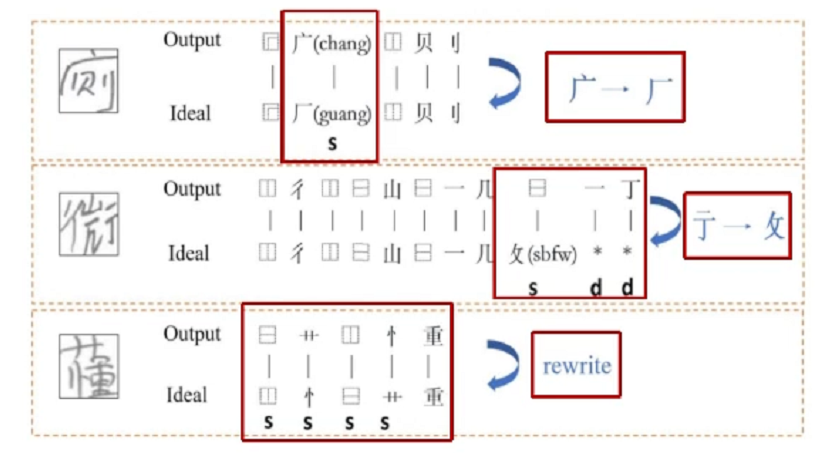
其中,识别与生成是联合优化的,这有点像学生学习时识字与写字互相强化的过程。评测的工作以往大多聚焦在语法层面,而杜俊的团队设计了一种可以直接从图像中找出错别字并详细说明错误之处的方法。这种方法在智能阅卷等场景中将非常有用。
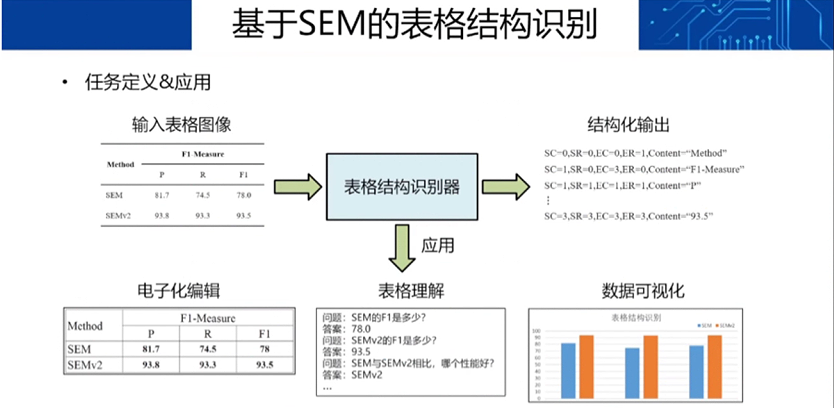
除了文本之外,表格的识别与处理其实也是一大难点,因为你不仅要识别里面的内容,还要理清这些内容之间的结构关系,而且有些表可能连线框都没有。为此,杜俊团队基于SEM的表格结构识别设计了一种「先分割,后合并」的方法:
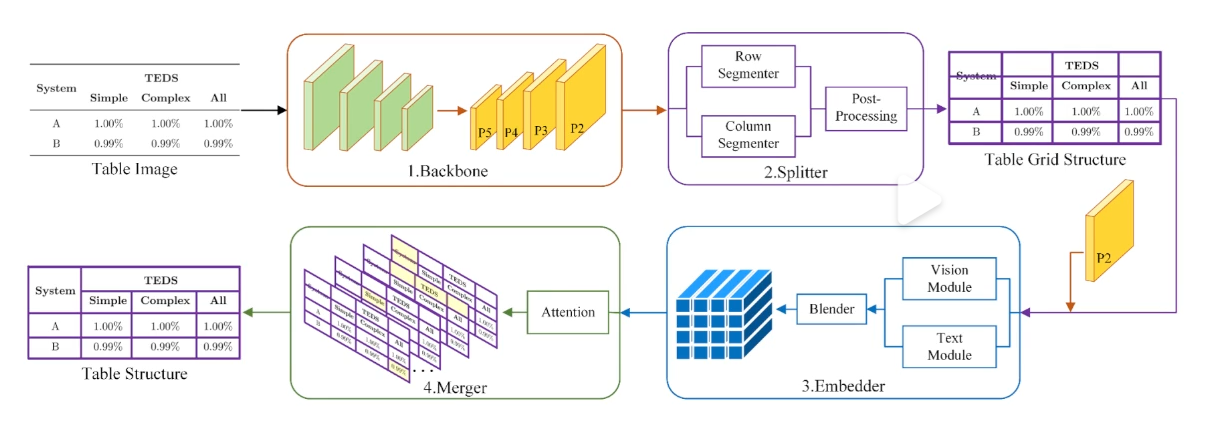
即先把表格图像拆分成一系列基础网格,然后再通过合并的方式做进一步纠正:
当然,这些方法在多版式的场景下还存在局限性,杜俊教授也针对未来的工作做出了计划和展望,希望能如他所愿:

三、总结
在21世纪,人工智能已经进入了腾飞的快车道,而且随着人工智能技术的不断完善和发展,人工智能也从生产领域扩大到生活领域,渗透到了人类生活的每一个细节,有了人工智能技术的帮助,让我们在出行、学习、工作等方面越来越方便,变得更加智慧化。
经过此次会议,让我对人工智能技术的发展和应用有了更清晰的认识,特别是会议上邱锡鹏教授对ChatGPT类大语言模型的技术点深度剖析,让我知道了ChatGPT的原理以及现阶段的难点。ChatGPT的大火也充分展现了研发通用人工智能助手广阔的研究和应用前景,从客服问答,智能引导,灵感创造等都已出现了它的身影,可能现在还不够成熟可靠,但它的出现让我们有了希望,这也是越来越多的企业跟风加入其中的原因。我相信,在不久的将来,如同ChatGPT一样的生成式人工智能产品将越来越频繁地出现在我们的社会场景之中,成为常态。
郭丰俊博士在底层视觉技术处理图像上的应用分享让我真正的感受到了智能数字化时代的高效和美好。以前处理PS痕迹检测找了各种各样的办法,无论是exif识别还是用“放大镜”工具手动排查都无法高效准确的解决此类问题。现在通过先进的底层视觉技术来智能化的进行PS痕迹检测在节约了大量的人力成本同时,还提高了检测效率及准确性。这是人工智能价值最直观的体现。
总而言之,AI时代已经到来,AI时代会让世界更高效!