网站开发追款单关键词优化公司排行
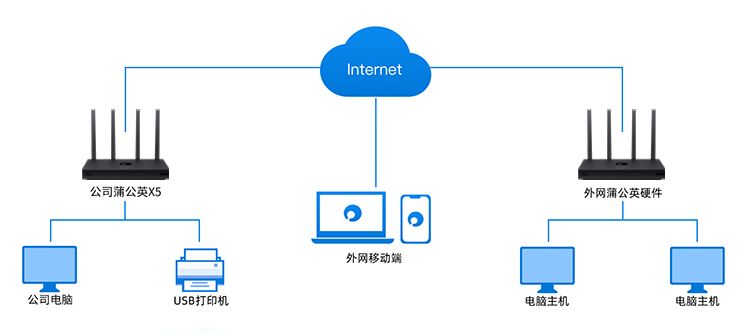
现如今,打印机已经是企业日常办公中必不可少的设备,无论何时何地,总有需要用到打印的地方,包括资料文件、统计报表等等。 但若人在外地或分公司,有文件急需通过总部的打印机进行打印时,由于不在同一物理网络环境下,无法直接操作,因此耽误了一定的时间,较为不便。
今天就由小编教大家,如何通过蒲公英X5,简单快捷低成本部署云打印,实现外网电脑或手机随时随地通过公司的打印机远程打印文件(查看PDF格式介绍手册请戳我)。

注:惠普打印机与蒲公英云打印功能无法兼容,若按以下步骤操作后仍无法实现远程打印,请更换其他品牌打印机尝试
2. 蒲公英云打印优势
1、蒲公英组网支持电脑端与手机端,网络兼容性强,能灵活使用;
2、不受宽带网络限制,无需公网IP,能接入互联网即可实现远程打印;
3、组网功能操作简单,技术门槛低,网络小白也只需简单三步骤轻松搭建。
3. 搭建步骤
3.1 接线上网
3.1.1 设备接线
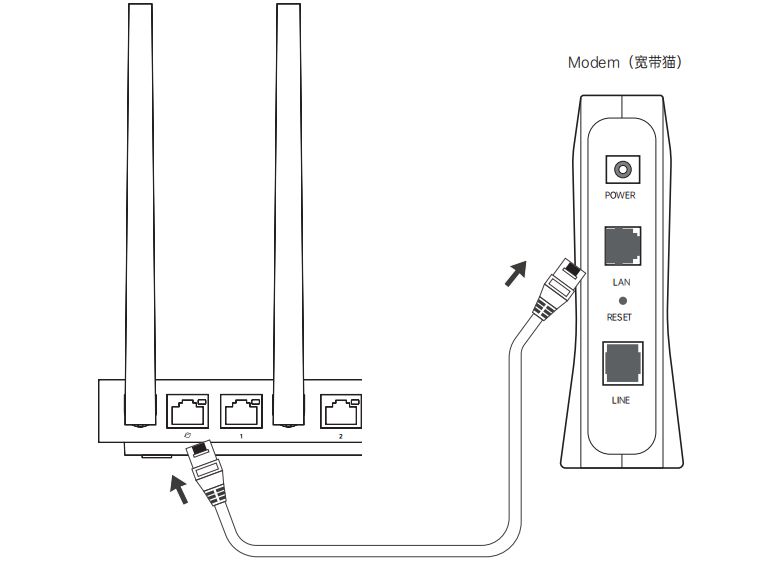
①连接电源
②连接设备
若使用宽带拨号/动态IP/静态IP模式,将蓝色网口连接外网网口(如宽带猫、光猫等),黄色网口连接局域网优先设备
若使用3G/4G路由模式,请将上网卡插入路由器USB口
③连接WiFi
待系统启动完成,连接前缀名为OrayBox的WiFi
OrayBox_xxxx表示2.4G频段,OrayBox_xxxx_5G表示5G频段
其中xxxx表示路由器MAC地址后4位
3.1.2 设备联网
蒲公英路由器提供了简单易用的Web 配置页面,您可通过Web 向导轻松完成上网配置。
(1)配置前,请确保计算机已连接到路由器的黄色网口(LAN口),并且设置好了自动获取 IP 地址。
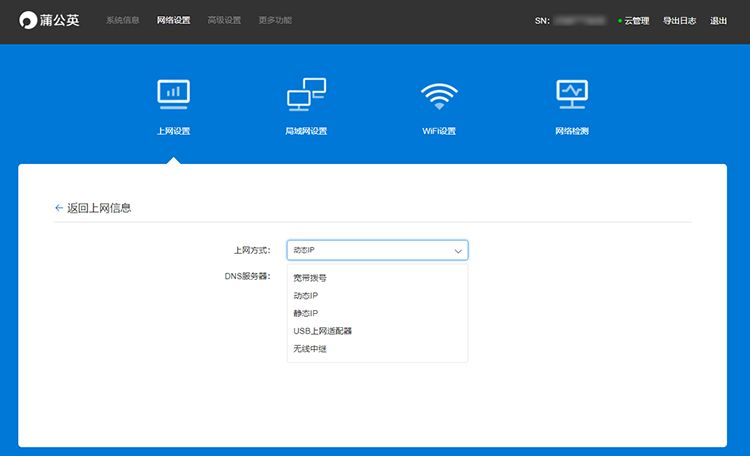
(2)蒲公英X5支持多种上网方式,可通过浏览器访问蒲公英默认出厂IP:10.168.1.1,进入本地管理页面,选择相应的上网方式进行配置(【网络设置】-【上网设置】-【切换上网方式】);
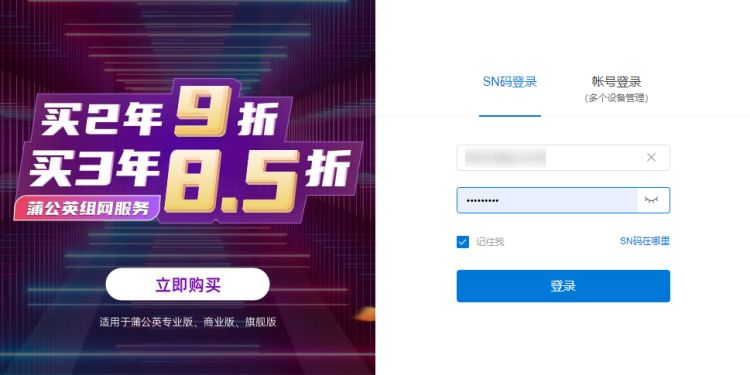
(3)若蒲公英路由器正常联网,可直接在浏览器输入https://pgybox.oray.com/ 访问云管理平台,通过SN码和密码完成登录。
3.2 开启云打印
(1)在云管理平台的【应用中心】->【智能云打印】,点击“立即使用”; 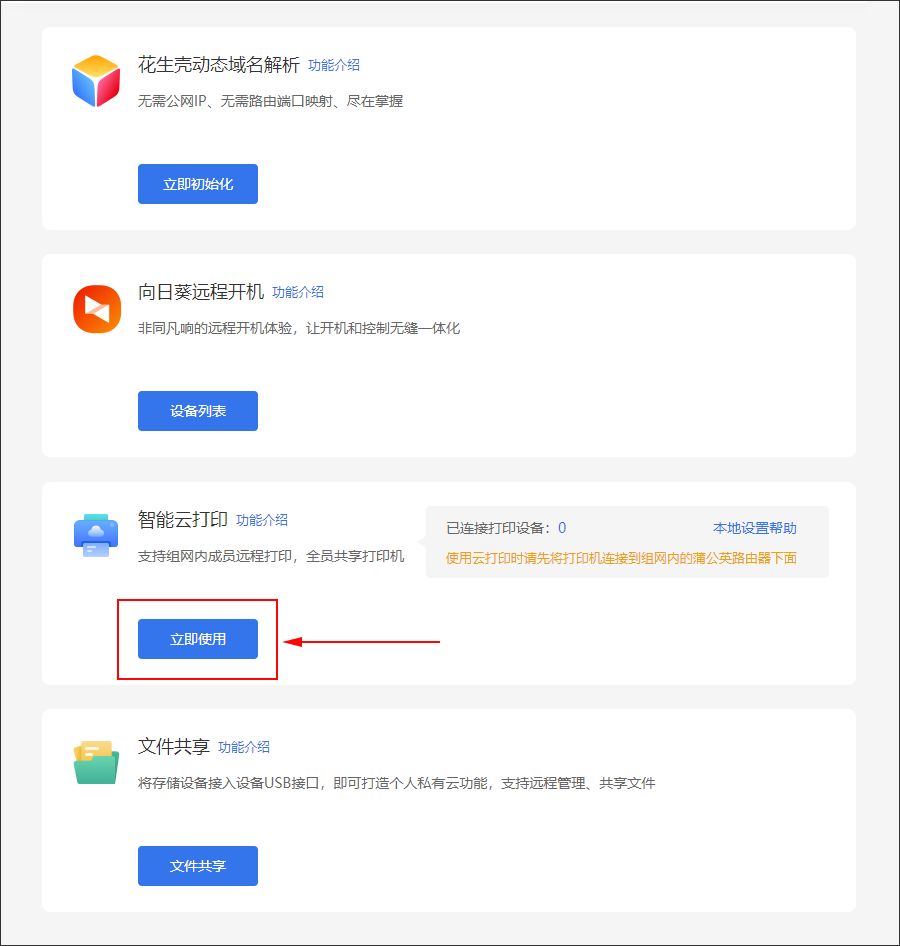
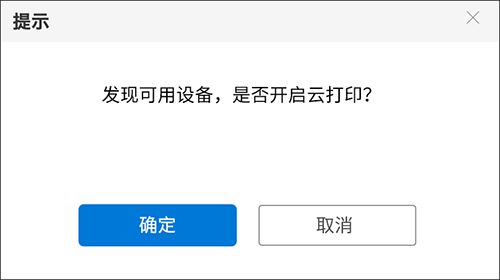
(2)若检测到已接入USB打印机,则弹窗请求确认,点击“确定”即可成功开启云打印功能。
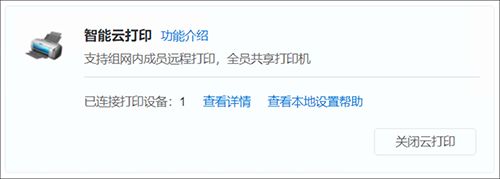
3.3 组建网络
【点击查看智能组网教程】
根据需求添加相应的成员后,点击确定,组网创建成功。下面演示外网访问端成员访问步骤。 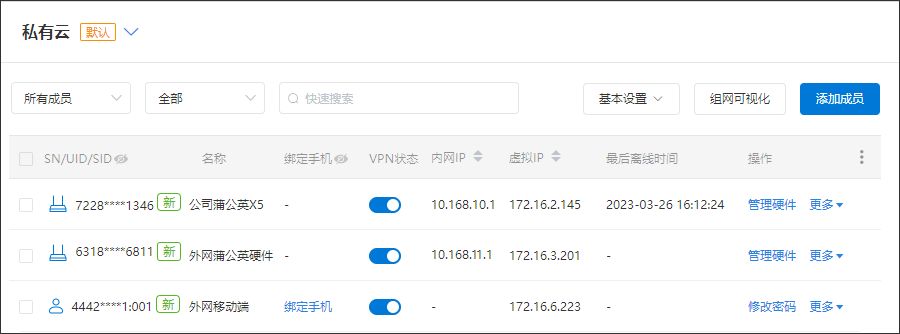
3.4 异地访问
3.4.1 外网软件成员
蒲公英客户端支持市场上各大主流操作系统,用户可访问蒲公英官网下载页(跳转戳我),选择相应操作系统的版本进行下载安装登录。
3.4.1.1 电脑端
下面以Windows访问端为例(具体教程请戳我)。
①登录客户端
用户首先需要登录蒲公英访问端,加入蒲公英X5所在的组网网络。
可通过前面组网后生成的UID进行登录,也可通过UID所绑定的手机号发送短信验证码进行登录;
登录相应的客户端账号后,即可看到组网内的成员,双击对应成员即可进行PING测试,若有收到回复,则表示组网通道已建立。 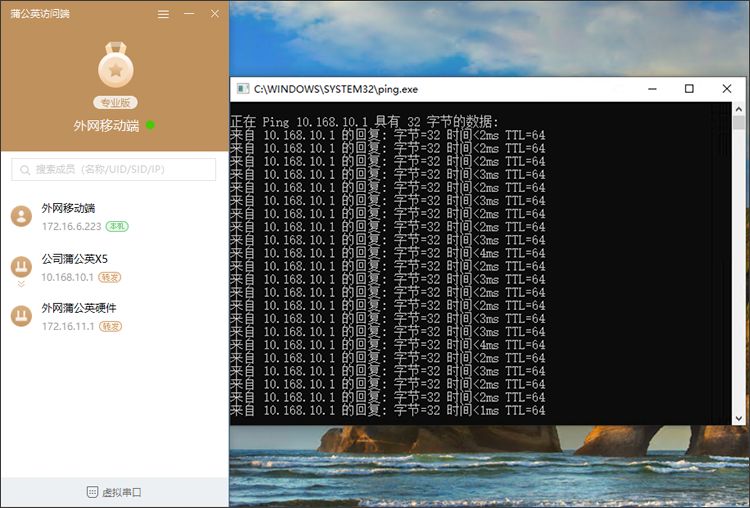
②添加打印机
以Windows10系统为例,点击左下角Win图标——设置;
在Windows设置中,找到并点击【设备】版块;
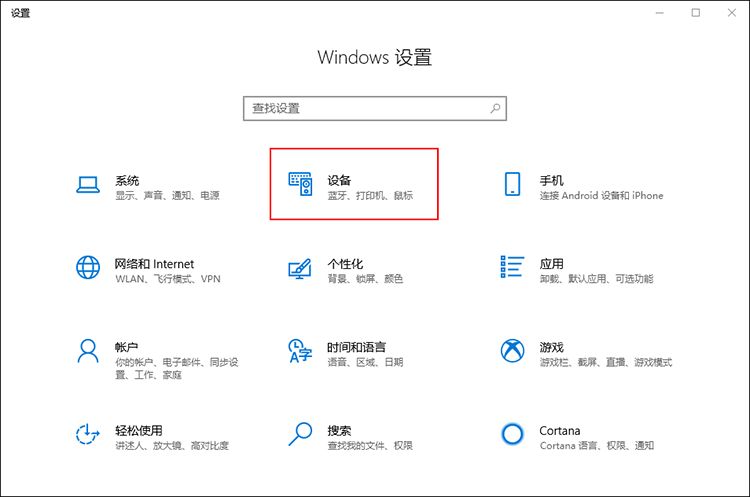
在打印机和扫描仪中,点击【我需要的打印机不在列表中】,选择【使用TCP/IP地址或主机名添加打印机】,点击下一步;
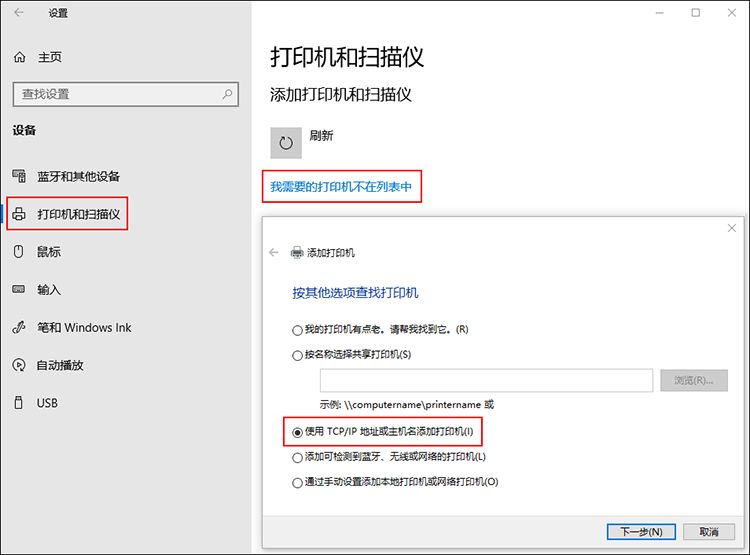
【主机名或IP地址(A)】输入蒲公英X5的IP地址:10.168.10.1,点击下一步;
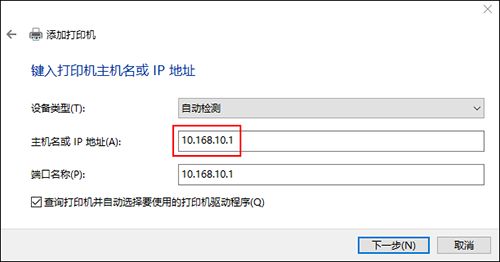
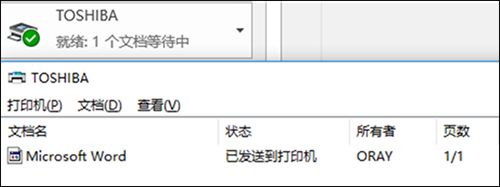
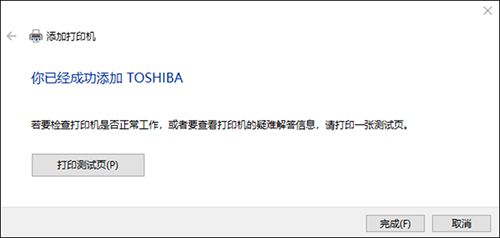
可以看到打印机添加成功,并可实现将本地文件通过X5所连接的USB打印机进行打印。
3.4.1.2 移动端
下面以安装蒲公英安卓访问端为例(具体教程请戳)
注:打印机是否支持通过手机进行打印可咨询相应的设备厂商。
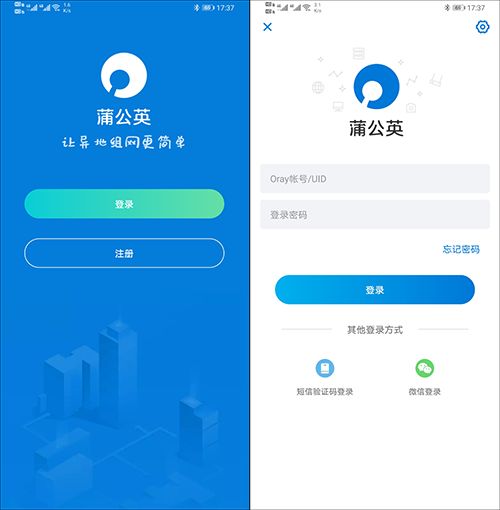
①登录客户端
首次使用组网功能,自动创建组网的用户,在此处直接输入X5所绑定的账号密码进行登录即可。若原先已使用组网功能,生成访问端UID或已绑定手机号/微信号,则可通过相应的方式进行登录;
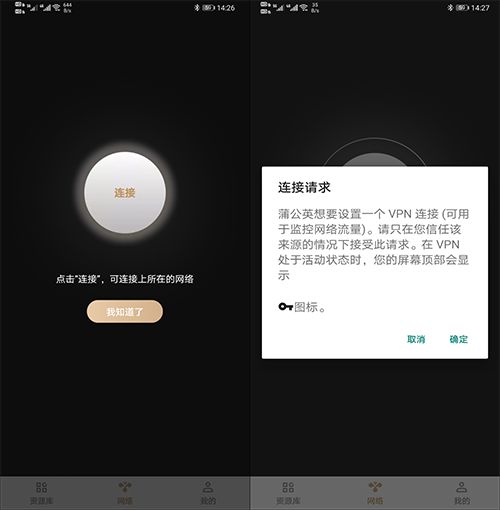
登录成功后,点击【连接】,并同意连接请求,点击【确定】,客户端登录成功。
②远程打印
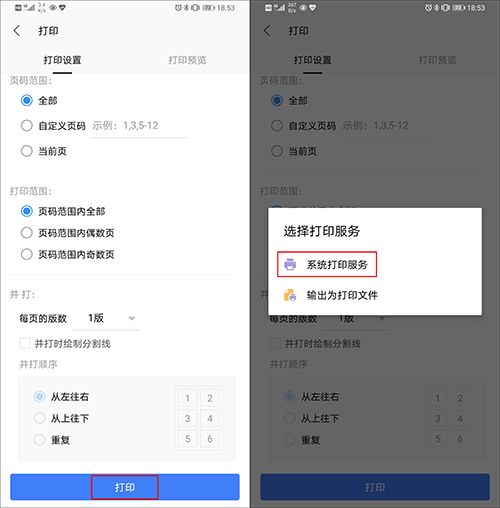
以WPS 为例进行演示,打开手机中的文档,点击【文件】---【打印】,选择【更多打印方式】;
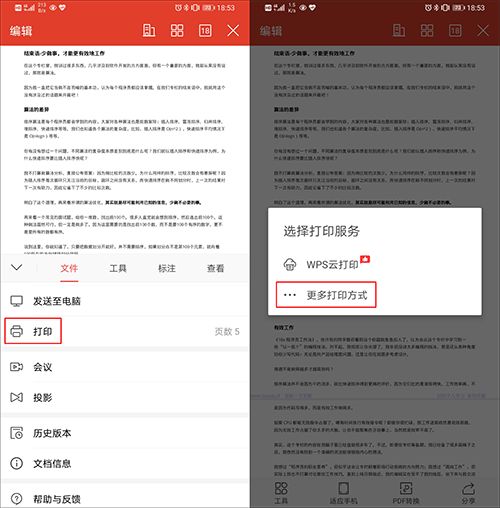
进行打印相关设置后,点击【打印】,选择【系统打印服务】;
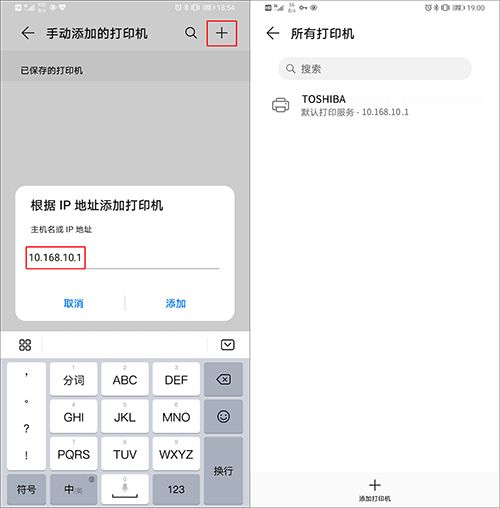
点击右上角【+】,输入蒲公英X5的IP地址,点击【添加】,打印机添加成功;
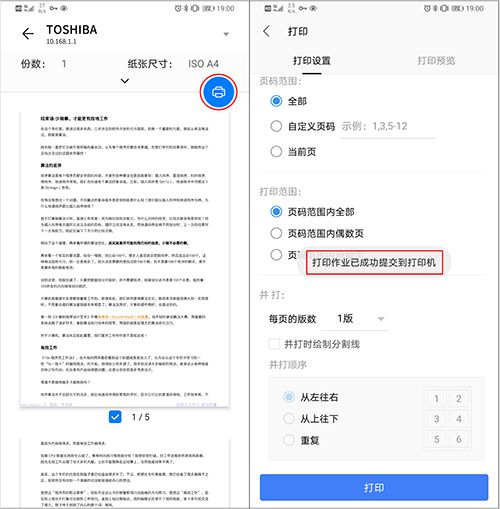
打印机添加成功后,即可在手机上选择远端X5所连接的USB相应的打印机,进行远程文件打印。
3.4.1 外网硬件成员
若组网中有其他蒲公英硬件,那该蒲公英下接的设备无需额外安装蒲公英客户端,直接访问即可。
如前文所述,手动添加打印机后,即可实现将本地文件通过X5所连接的USB打印机进行打印。
至此,蒲公英X5远程打印操作指南介绍结束,感谢您的观看!