游戏网站建设公司长沙做网站seo公司
下载Android Studio,配置安卓开发环境,这个过程比较漫长。

安装cmake,注意安装的是cmake3.10版本。
根据手机安卓版本选择相应的安卓版本,我的是红米K30Pro,安卓12。

使用腾讯开源的ncnn,这是一个为手机端极致优化的高性能神经网络前向计算框架,能够将深度学习算法轻松移植到手机端高效执行。
克隆大佬写好的yolov8的安卓项目
git clone https://github.com/FeiGeChuanShu/ncnn-android-yolov8.git下载解压ncnn-20231027-android-vulkan。
https://github.com/Tencent/ncnn/releases/download/20231027/ncnn-20231027-android-vulkan.zip
把ncnn-20231027-android-vulkan里面的文件放到ncnn-android-yolov8的\app\src\main\jni目录下。

下载opencv
Releases - OpenCV

然后解压,把文件夹放到ncnn-android-yolov8的\app\src\main\jni目录下。

修改ncnn-android-yolov8\app\src\main\jni里面的CMakeLists.txt文件,就是我们刚刚下载的两个文件的路径

修改依赖的gradle插件版本为7.2.0,为什么呢,因为这个版本亲测没有问题,其他的难说。

然后是修改使用的gradle版本为7.4-all版本。

重新sync项目

连接手机,打开手机的开发者模式,打开USB调试,打开USB安装,等Android Studio检测到我的红米K30Pro,然后点击运行,这时app就可以安装到手机上了,可以正常识别。

yolov8安卓部署
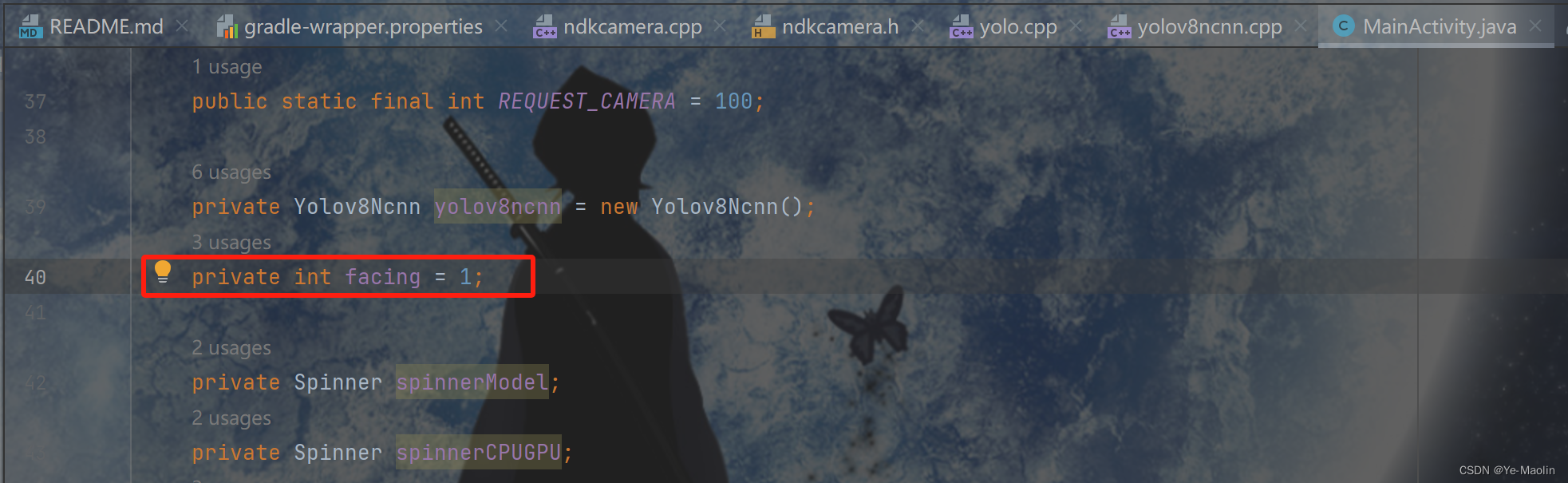
另外app默认先打开的是前置摄像头,通过分析代码,可以知道,将MainActivity.java的40的facing的初始值从0改成1可以让app默认先打开后置摄像头