珠海网站建设建站模板网站开发学习步骤
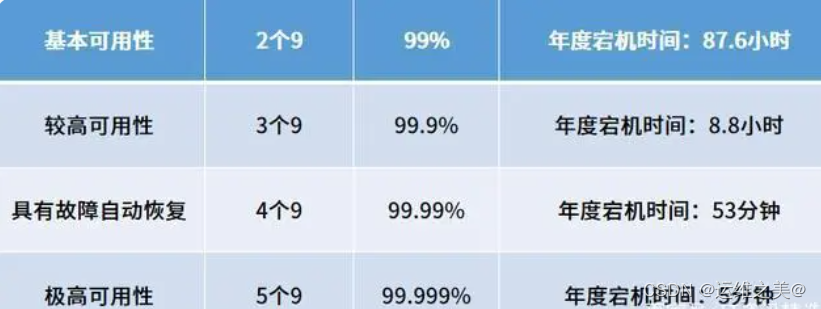
一、什么是高可用
在运维中,经常听到高可用,那么什么是高可用架构呢?通俗点讲,高可用就是在服务故障,节点宕机的情况下,业务能够保证不中断,服务正常运行。
举个例子,支付宝,淘宝商城,24小时不间断的有人支付或者购物,如果服务器宕机就造成了支付宝不能转账,网站不能访问,那么造成的损失是可想而知的。对于商业合作来说,不稳定的系统也不会有人相信和使用。
二、怎么使用高可用
最简单的例子就是访问一个网站,例如访问百度网站www.baidu.com,多次ping www.baidu.com域名,返回的地址是不同的。在架构上,此域名后端是不同的地址池,通过负载测试将流量转发给后端的real server,slb负载会进行存活检测,当后端业务服务器A出现宕机或者服务异常时,nginx会将服务转发到B应用服务器上,仍然能够正常对外提供服务

三、常见的高可用架构
高可用的服务架构要求架构的健壮性,出现异常情况时能够保证服务的可用性,我认为需要从下面几个方面来设计
域名:作为网站的入口,使用域名服务(如DNS)来实现域名解析,将域名映射到服务的负载均衡器上。可以考虑使用多个域名服务提供商以增加可用性。
负载:使用负载均衡器(如NGINX、HAProxy、AWS ELB等)来分发流量到多个后端服务实例。负载均衡器可以根据实例的负载情况和健康状态动态调整流量分发。这样当节点出现故障时,对用户是无感知的。
数据库:使用主从复制或者多主复制来实现数据库的高可用性。可以考虑使用数据库集群(如MySQL Cluster、MongoDB Replica Set等)来提高数据库的可用性和性能。
自动扩展:使用自动化工具(如Kubernetes、Docker Swarm、AWS Auto Scaling等)来实现服务的自动扩展。根据流量和负载情况自动增加或减少服务实例数量,以应对高峰时段的流量变化。
故障转移:配置故障转移机制,当一个服务实例或节点发生故障时,自动切换到备用实例或节点。可以使用健康检查和故障转移工具(如keepalived、etcd等)来实现故障转移。
监控:实时监控服务的运行状态和性能指标,包括CPU、内存、网络等。可以使用监控工具(如Prometheus、Grafana、ELK Stack等)来实现监控和报警功能,及时发现和解决问题。
-
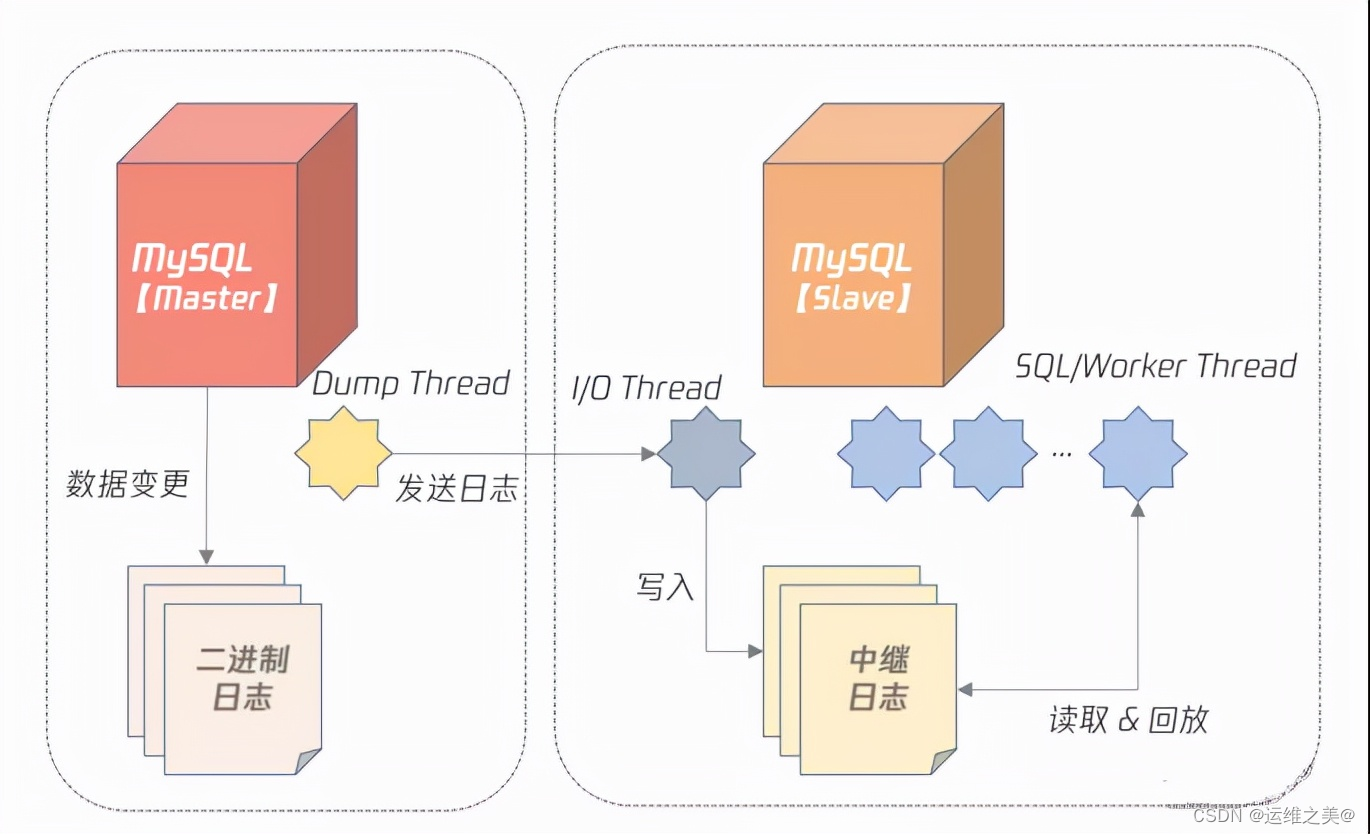
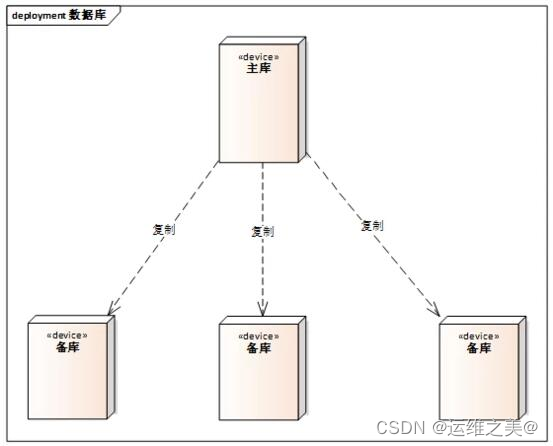
数据库的高可用
数据存储高可用的方案本质都是通过将数据复制到多个存储设备,通过数据冗余的方式来实现高可用。常见的高可用架构有主备、主从、主主、集群、分区等,接下来我们聊聊每种架构的优缺点。
-
K8S高可用机制
三master多node节点,多副本都是高可用的例子