医疗网站不备案深圳市前十的互联网推广公司
一、项目简介
使用过ABP框架的童鞋应该知道它也自带了一款免费的Blazor UI主题,它的页面是长这样的:
个人感觉不太美观,于是网上搜了很多Blazor开源组件库,发现有一款样式非常不错的组件库,名叫:Radzen,它的组件库案例网址是:https://blazor.radzen.com/dashboard?theme=material3-dark,比较符合我的审美,于是使用它开发了基于ABP框架的UI主题,项目名称叫Abp.RadzenUI,已在Github上开源:Abp.RadzenUI,欢迎大家star。已经提供了基本的功能:登录(支持多租户)、角色管理、用户管理、权限分配、租户管理、多语言切换、免费主题样式切换、侧边栏菜单等;
二、UI展示
1.登录页面,支持多租户的切换登录

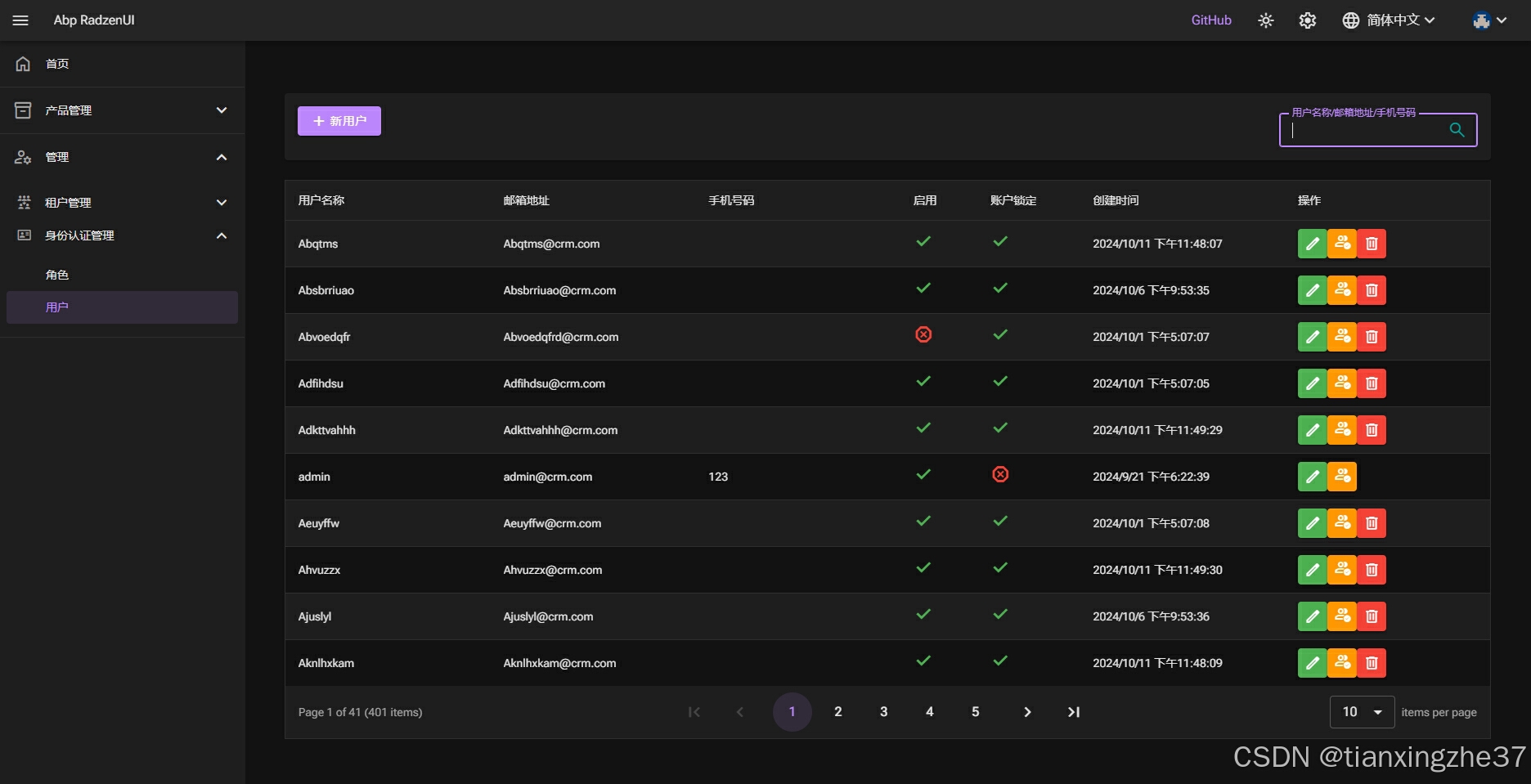
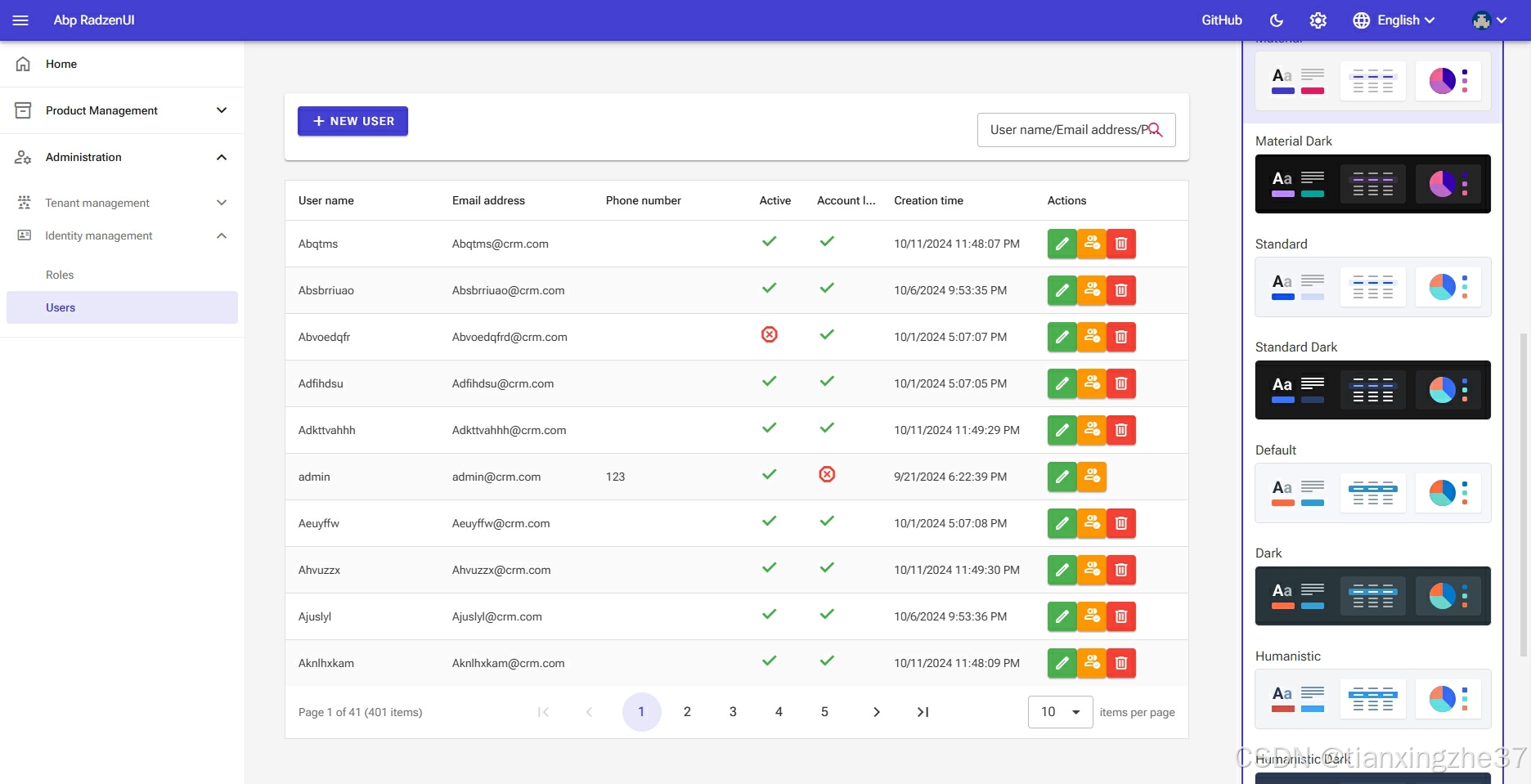
2.用户列表
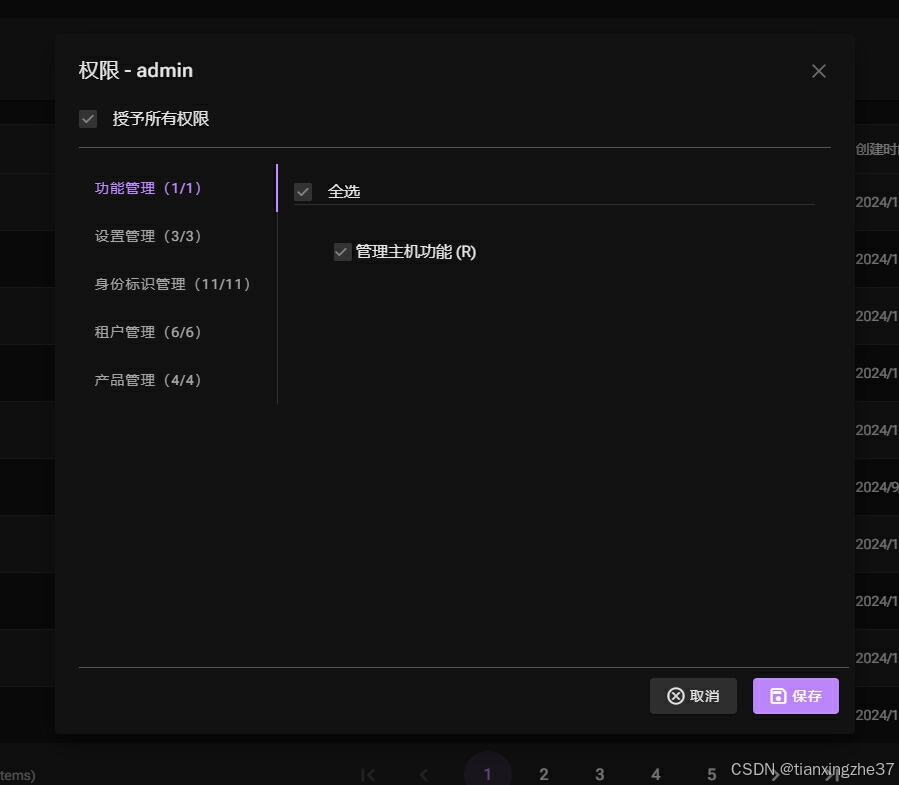
3.权限分配
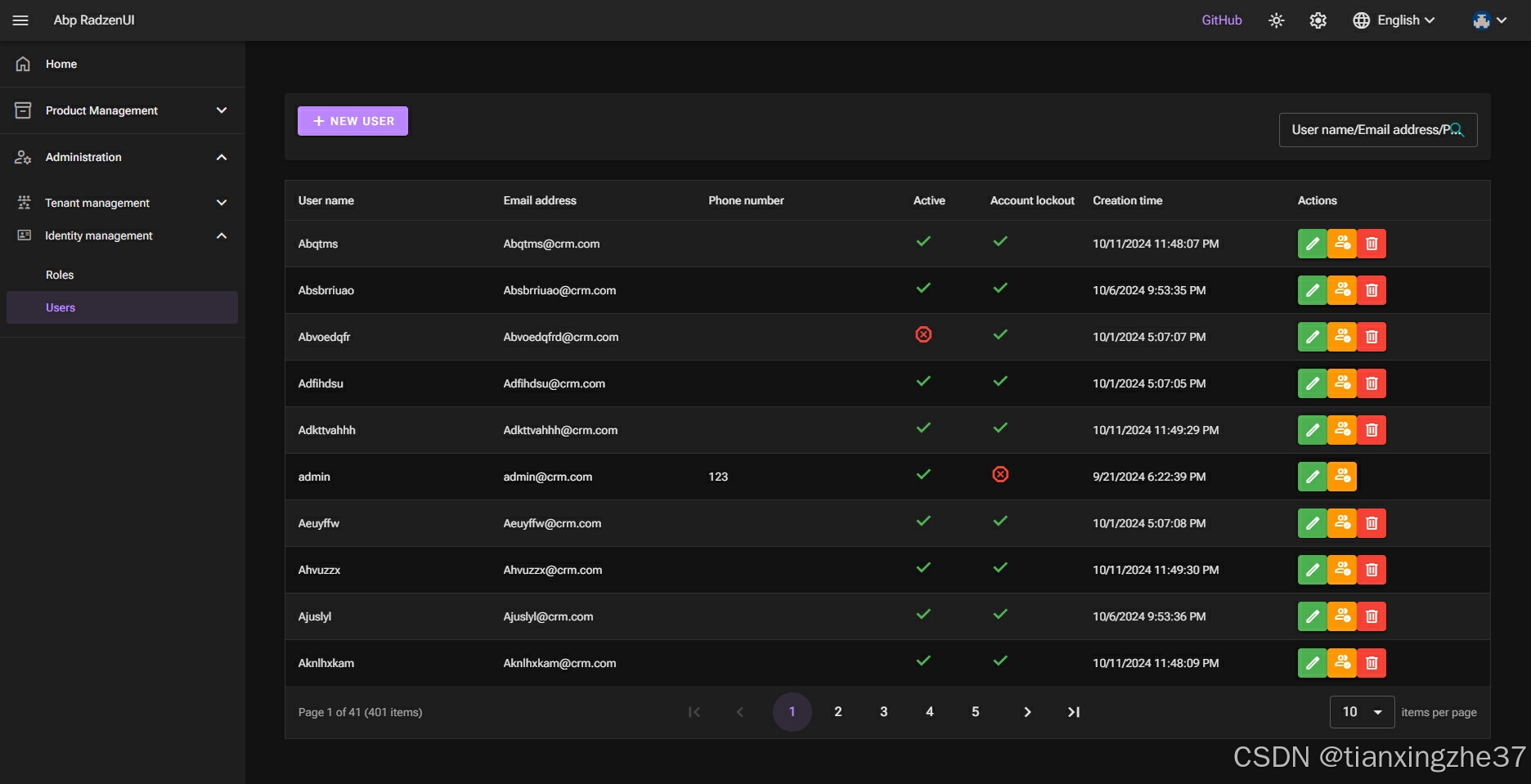
4.支持多语言切换
5.支持多主题切换
要体验更多的功能,你可以下载本项目到本地亲自体验
三、如何使用
1. 使用ABP CLI工具创建一个新的Abp Blazor Server应用,例如项目名称叫CRM
abp new CRM -u blazor-server -dbms PostgreSQL -m none --theme leptonx-lite -csf2. 在CRM.Blazor项目安装AbpRadzen.Blazor.Server.UI包
dotnet add package AbpRadzen.Blazor.Server.UI3. 移除CRM.Blazor项目中与leptonx-lite主题相关的nuget包和代码
主要是 CRMBlazorModule 类中的代码需要精简,可以参考示例项目中的CRMBlazorWebModule.cs文件代码,你可以直接将它的代码覆盖你的代码;
然后删除Pages目录中自带的razor页面文件。
4. 对 Abp RadzenUI 进行配置
将 ConfigureAbpRadzenUI 方法添加到ConfigService方法中
private void ConfigureAbpRadzenUI()
{// Configure AbpRadzenUIConfigure<AbpRadzenUIOptions>(options =>{// 这句代码很重要,它会将你在Blazor Web项目中新建的razor页面组件添加到Router中,这样就可以访问到了options.RouterAdditionalAssemblies = [typeof(Home).Assembly];// 配置页面标题栏//options.TitleBar = new TitleBarSettings//{// ShowLanguageMenu = false, // 是否显示多语言按钮菜单// Title = "CRM" // 标题栏名称:一般是系统名称//};//options.LoginPage = new LoginPageSettings//{// LogoPath = "xxx/xx.png" // 登录页面的logo图片//};//options.Theme = new ThemeSettings//{// Default = "material",// EnablePremiumTheme = true,//};});// 多租户配置, 这个会影响到登录页面是否展示租户信息Configure<AbpMultiTenancyOptions>(options =>{options.IsEnabled = MultiTenancyConsts.IsEnabled;});// Configure AbpLocalizationOptionsConfigure<AbpLocalizationOptions>(options =>{// 配置多语言资源,需要继承AbpRadzenUIResource,它包含了需要用到的多语言信息var crmResource = options.Resources.Get<CRMResource>();crmResource.AddBaseTypes(typeof(AbpRadzenUIResource));// 配置多语言菜单中显示的语言options.Languages.Clear();options.Languages.Add(new LanguageInfo("en", "en", "English"));options.Languages.Add(new LanguageInfo("fr", "fr", "Français"));options.Languages.Add(new LanguageInfo("zh-Hans", "zh-Hans", "简体中文"));});// 配置侧边栏菜单Configure<AbpNavigationOptions>(options =>{options.MenuContributors.Add(new CRMMenuContributor());});
}最后在OnApplicationInitialization方法的最后添加以下代码,使用RadzenUI
app.UseRadzenUI();关于更多的配置可以参考本项目的示例代码:https://github.com/ShaoHans/Abp.RadzenUI/blob/main/samples/CRM.Blazor.Web/CRMBlazorWebModule.cs
5. 配置侧边栏菜单
当你添加了新的razor页面组件后,需要在CRMMenuContributor类文件中进行配置,这样它就会显示在页面的侧边栏菜单中
四、添加自己的页面
比如你现在要做一个商品管理的增删改查功能,你只要定义一个IProductAppService接口并继承ABP的ICrudAppService接口:
public interface IProductAppService: ICrudAppService<ProductDto, Guid, GetProductsInput, CreateProductDto, UpdateProductDto> { }然后实现IProductAppService接口:
public class ProductAppService: CrudAppService<Product,ProductDto,Guid,GetProductsInput,CreateProductDto,UpdateProductDto>,IProductAppService{}一个简单的增删改查业务代码就搞定了,而且接口带了权限验证,完全不用写那么多代码,当然一些其他业务逻辑也可以通过override的方式去实现。
接下来就是增加产品的列表页面,razor页面需要继承下面这个组件:
@inherits AbpCrudPageBase<IProductAppService, ProductDto, Guid, GetProductsInput, CreateProductDto, UpdateProductDto>这个组件将CRUD的代码都实现了,你只需要编写DataGrid显示列的代码,以及创建产品、编辑产品弹框的代码,强烈建议你把项目代码下载下来学习一下,实现一个后台管理系统真的太简单了。
五、RadzenDataGrid的过滤功能介绍
列表页面都有下面类似的筛选功能:
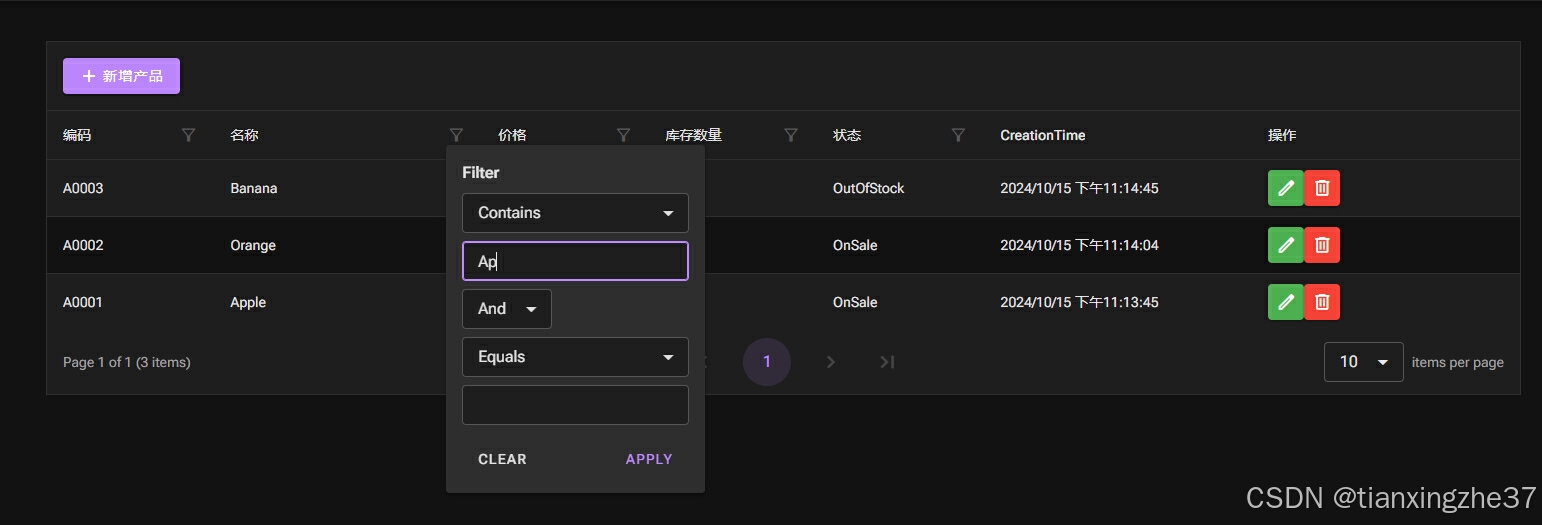
RadzenDataGrid组件也支持这种筛选,它会把所有列头的筛选条件最后组装成一个过滤字符串,放到了LoadDataArgs类的Filter参数中,这个过滤字符串类似这样:
(Name == null ? "" : Name).Contains("App") and StockCount < 10000 and Status = 0你的查询接口只需要定义一个Filter属性接受这个字符串,通过这个字符串就能查到数据,当然这得归功于强大的工具包:Microsoft.EntityFrameworkCore.DynamicLinq,感兴趣的可以去查阅资料学习一下。
protected override async Task<IQueryable<Product>> CreateFilteredQueryAsync(GetProductsInput input
)
{var query = await base.CreateFilteredQueryAsync(input);/*在 CRM.EntityFrameworkCore 项目上安装包: Microsoft.EntityFrameworkCore.DynamicLinq然后引用命名空间 : using System.Linq.Dynamic.Core;Dynamic LINQ会自动将过滤字符串转成动态查询表达式*/if (!string.IsNullOrEmpty(input.Filter)){query = query.Where(input.Filter);}return query;
}六、总结
以上就是对我这个开源项目(https://github.com/ShaoHans/Abp.RadzenUI)简单介绍,如果你熟悉ABP且希望使用它开发一个后台管理系统,不妨一试,有什么问题欢迎大家提issue。