有模版之后怎么做网站国内最佳网站建设设计
1.随意创建一个类,他都有UCLASS()。GENERATED_BODY()这样的默认的宏。
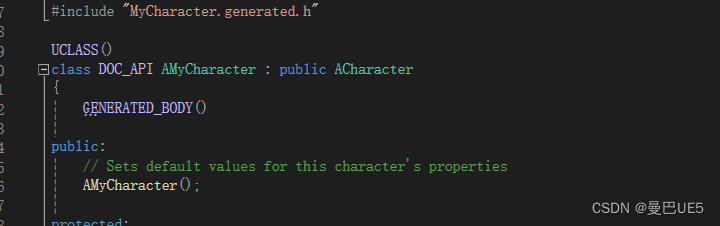
UCLASS() 告知虚幻引擎生成类的反射数据。类必须派生自UObject.
(告诉引擎我是从远古大帝UObject中,继承而来,我们是一家人,只是我进化了其他功能)
GENERATED_BODY()表示我们不直接使用父类的构造函数,如果我们要在我们自定义的类中做一些初始化操作,需要我们自己在.h头文件中声明构造函数,然后在.cpp文件中 实现该构造函数,默认它之后的成员函数,成员变量是private。
(构造函数自己写去,自己可以在面随意初始化,但在.h里要声明哦。你如果不加关键字,它后面所有的函数和变量都是私有的)。
2.GENERATED_UCLASS_BODY()表示我们使用父类的构造,如果我们在自定义的类中做一些初始化操作,可以直接在.cpp文件中实现构造函数,而不需要在.h头文件中去声明,这个宏会自动生成带有特定参数的构造函数,它之后的成员是public。(我还没咋用过)
3.UPROPERTY 叫做属性声明宏,虚幻C++在标准基础之上实现了一套反射系统(Reflection System),反射系统负责垃圾回收、引用更新,编译器集成等一系列高级且有用的功能。而UPROPERTY的作用就是声明该属性在反射系统的行为。(变量可以被引擎识别处理,最直观的体现就是蓝图交互)
4.UFUNCTION 函数声明宏,反射系统可识别的C++函数。(函数同上)
5.USTRUCT() 结构体声明宏。反射系统可识别的C++结构体。(结构体同上)
6.UENUM() 枚举声明宏,反射系统可识别的C++枚举。(枚举同上)