用帝国cms做企业网站网站开发的最后5个阶段是什么
作为基于现代密码学公钥算法的安全协议,TLS/SSL 能在计算机通讯网络上保证传输安全,EMQX 内置对 TLS/SSL 的支持,包括支持单/双向认证、X.509 证书、负载均衡 SSL 等多种安全认证。你可以为 EMQX 支持的所有协议启用 SSL/TLS,也可以将 EMQX 提供的 HTTP API 配置为使用 TLS。
SSL/TLS 带来的安全优势
-
强认证。 用 TLS 建立连接的时候,通讯双方可以互相检查对方的身份。在实践中,很常见的一种身份检查方式是检查对方持有的 X.509 数字证书。这样的数字证书通常是由一个受信机构颁发的,不可伪造。
-
保证机密性。TLS 通讯的每次会话都会由会话密钥加密,会话密钥由通讯双方协商产生。任何第三方都无法知晓通讯内容。即使一次会话的密钥泄露,并不影响其他会话的安全性。
-
完整性。 加密通讯中的数据很难被篡改而不被发现。
SSL/TLS 协议
TLS/SSL 协议下的通讯过程分为两部分,第一部分是握手协议。握手协议的目的是鉴别对方身份并建立一个安全的通讯通道。握手完成之后双方会协商出接下来使用的密码套件和会话密钥;第二部分是 record 协议,record 和其他数据传输协议非常类似,会携带内容类型,版本,长度和荷载等信息,不同的是它所携带的信息是加密了的。
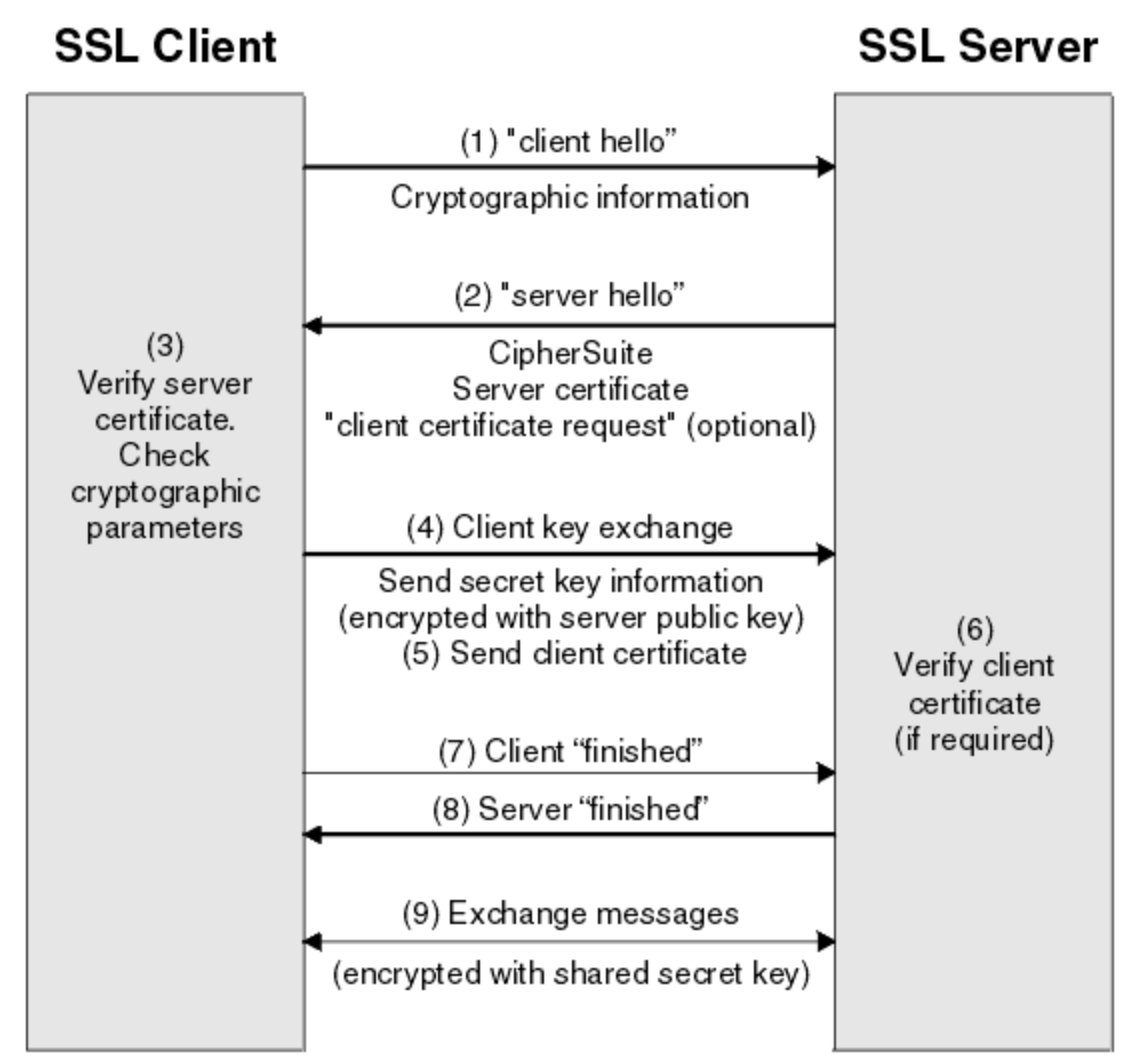
下面的图片描述了 TLS/SSL 握手协议的过程,从客户端的 "hello" 一直到服务器的 "finished" 完成握手。有兴趣的同学可以找更详细的资料看。对这个过程不了解也并不影响我们在 EMQX 中启用这个功能。
为什么需要 SSL/TLS 双向认证
双向认证是指,在进行通信认证时要求服务端和客户端都需要证书,双方都要进行身份认证,以确保通信中涉及的双方都是受信任的。 双方彼此共享其公共证书,然后基于该证书执行验证、确认。一些对安全性要求较高的应用场景,就需要开启双向 SSL/TLS 认证。
SSL/TLS 证书准备
在双向认证中,一般都使用自签名证书的方式来生成服务端和客户端证书,因此本文就以自签名证书为例。
通常来说,我们需要数字证书来保证 TLS 通讯的强认证。数字证书的使用本身是一个三方协议,除了通讯双方,还有一个颁发证书的受信第三方,有时候这个受信第三方就是一个 CA。和 CA 的通讯,一般是以预先发行证书的方式进行的。也就是在开始 TLS 通讯的时候,我们需要至少有 2 个证书,一个 CA 的,一个 EMQX 的,EMQX 的证书由 CA 颁发,并用 CA 的证书验证。
在这里,我们假设您的系统已经安装了 OpenSSL。使用 OpenSSL 附带的工具集就可以生成我们需要的证书了。
生成自签名 CA 证书
首先,我们需要一个自签名的 CA 证书。生成这个证书需要有一个私钥为它签名,可以执行以下命令来生成私钥:
openssl genrsa -out ca.key 2048 这个命令将生成一个密钥长度为 2048 的密钥并保存在 ca.key 中。有了这个密钥,就可以用它来生成 EMQX 的根证书了:
openssl req -x509 -new -nodes -key ca.key -sha256 -days 3650 -out ca.pem根证书是整个信任链的起点,如果一个证书的每一级签发者向上一直到根证书都是可信的,那个我们就可以认为这个证书也是可信的。有了这个根证书,我们就可以用它来给其他实体签发实体证书了。
生成服务端证书
实体(在这里指的是 EMQX)也需要一个自己的私钥对来保证它对自己证书的控制权。生成这个密钥的过程和上面类似:
openssl genrsa -out emqx.key 2048新建 openssl.cnf 文件,
-
req_distinguished_name :根据情况进行修改,
-
alt_names:
BROKER_ADDRESS修改为 EMQX 服务器实际的 IP 或 DNS 地址,例如:IP.1 = 127.0.0.1,或 DNS.1 = broker.xxx.com
注意:IP 和 DNS 二者保留其一即可,如果已购买域名,只需保留 DNS 并修改为你所使用的域名地址
[req]default_bits = 2048
distinguished_name = req_distinguished_name
req_extensions = req_ext
x509_extensions = v3_req
prompt = no
[req_distinguished_name]
countryName = CN
stateOrProvinceName = Zhejiang
localityName = Hangzhou
organizationName = EMQX
commonName = CA
[req_ext]
subjectAltName = @alt_names
[v3_req]
subjectAltName = @alt_names
[alt_names]
IP.1 = BROKER_ADDRESS
DNS.1 = BROKER_ADDRESS然后以这个密钥和配置签发一个证书请求:
openssl req -new -key ./emqx.key -config openssl.cnf -out emqx.csr然后以根证书来签发 EMQX 的实体证书:
openssl x509 -req -in ./emqx.csr -CA ca.pem -CAkey ca.key -CAcreateserial -out emqx.pem -days 3650 -sha256 -extensions v3_req -extfile openssl.cnf生成客户端证书
双向连接认证还需要创建客户端证书,首先需要创建客户端密钥:
openssl genrsa -out client.key 2048使用生成的客户端密钥来创建一个客户端请求文件:
openssl req -new -key client.key -out client.csr -subj "/C=CN/ST=Zhejiang/L=Hangzhou/O=EMQX/CN=client"最后使用先前生成好的服务端 CA 证书来给客户端签名,生成一个客户端证书:
openssl x509 -req -days 3650 -in client.csr -CA ca.pem -CAkey ca.key -CAcreateserial -out client.pem准备好服务端和客户端证书后,我们就可以在 EMQX 中启用 TLS/SSL 双向认证功能。
SSL/TLS 双向连接的启用及验证
在 EMQX 中 mqtt:ssl 的默认监听端口为 8883。
EMQX 配置
将前文中通过 OpenSSL 工具生成的 emqx.pem、emqx.key 及 ca.pem 文件拷贝到 EMQX 的 etc/certs/ 目录下,并参考如下配置修改 emqx.conf:
## listener.ssl.$name is the IP address and port that the MQTT/SSL
## Value: IP:Port | Port
listener.ssl.external = 8883## Path to the file containing the user's private PEM-encoded key.
## Value: File
listener.ssl.external.keyfile = etc/certs/emqx.key## 注意:如果 emqx.pem 是证书链,请确保第一个证书是服务器的证书,而不是 CA 证书。
## Path to a file containing the user certificate.
## Value: File
listener.ssl.external.certfile = etc/certs/emqx.pem## 注意:ca.pem 用于保存服务器的中间 CA 证书和根 CA 证书。可以附加其他受信任的 CA,用来进行客户端证书验证。
## Path to the file containing PEM-encoded CA certificates. The CA certificates
## Value: File
listener.ssl.external.cacertfile = etc/certs/ca.pem## A server only does x509-path validation in mode verify_peer,
## as it then sends a certificate request to the client (this
## message is not sent if the verify option is verify_none).
##
## Value: verify_peer | verify_none
listener.ssl.external.verify = verify_peer## Used together with {verify, verify_peer} by an SSL server. If set to true,
## the server fails if the client does not have a certificate to send, that is,
## sends an empty certificate.
##
## Value: true | false
listener.ssl.external.fail_if_no_peer_cert = true创建 MQTT 连接
添加以下依赖到项目 pom.xml 文件中。
<dependency><groupId>org.eclipse.paho</groupId><artifactId>org.eclipse.paho.client.mqttv3</artifactId><version>1.2.5</version></dependency>
<!-- https://mvnrepository.com/artifact/org.bouncycastle/bcpkix-jdk15on -->
<dependency><groupId>org.bouncycastle</groupId><artifactId>bcpkix-jdk15on</artifactId><version>1.70</version>
</dependency>
然后使用如下代码创建 SSLUtils.java 文件。
import cn.hutool.core.io.FileUtil;
import com.alibaba.cloud.commons.lang.StringUtils;
import org.bouncycastle.jce.provider.BouncyCastleProvider;
import org.bouncycastle.openssl.PEMKeyPair;
import org.bouncycastle.openssl.PEMParser;
import org.bouncycastle.openssl.jcajce.JcaPEMKeyConverter;
import org.springframework.core.io.ClassPathResource;import javax.net.ssl.KeyManagerFactory;
import javax.net.ssl.SSLContext;
import javax.net.ssl.SSLSocketFactory;
import javax.net.ssl.TrustManagerFactory;
import java.io.BufferedInputStream;
import java.io.File;
import java.io.FileReader;
import java.security.KeyPair;
import java.security.KeyStore;
import java.security.Security;
import java.security.cert.CertificateFactory;
import java.security.cert.X509Certificate;/*** @author chenzhongchao* @program hierway-guacamole* @description* @packagename com.hierway.modbus.client* @date 2023-08-25 16:51**/
public class SSLUtils {public static SSLSocketFactory getSocketFactory( String caCrtFile,String crtFile, String keyFile, String password)throws Exception {Security.addProvider(new BouncyCastleProvider());if (StringUtils.isEmpty(password)){password = "";}// load CA certificateX509Certificate caCert = null;String path = System.getProperty("user.dir");if (!FileUtil.exist(caCrtFile)){if (!FileUtil.exist(path+File.separator+caCrtFile)){ClassPathResource classPathResource = new ClassPathResource(caCrtFile);caCrtFile = classPathResource.getPath();}else{caCrtFile = path+File.separator+caCrtFile;}}BufferedInputStream bis = FileUtil.getInputStream(caCrtFile);CertificateFactory cf = CertificateFactory.getInstance("X.509");while (bis.available() > 0) {caCert = (X509Certificate) cf.generateCertificate(bis);}// load client certificateif (!FileUtil.exist(crtFile)){if (!FileUtil.exist(path+File.separator+crtFile)){ClassPathResource classPathResource = new ClassPathResource(crtFile);crtFile = classPathResource.getPath();}else{crtFile = path+File.separator+crtFile;}}bis = FileUtil.getInputStream(crtFile);X509Certificate cert = null;while (bis.available() > 0) {cert = (X509Certificate) cf.generateCertificate(bis);}// load client private keyif (!FileUtil.exist(keyFile)){if (!FileUtil.exist(path+File.separator+keyFile)){ClassPathResource classPathResource = new ClassPathResource(keyFile);keyFile = classPathResource.getPath();}else{keyFile = path+File.separator+keyFile;}}PEMParser pemParser = new PEMParser(new FileReader(FileUtil.file(keyFile)));Object object = pemParser.readObject();JcaPEMKeyConverter converter = new JcaPEMKeyConverter().setProvider("BC");KeyPair key = converter.getKeyPair((PEMKeyPair) object);pemParser.close();// CA certificate is used to authenticate serverKeyStore caKs = KeyStore.getInstance(KeyStore.getDefaultType());caKs.load(null, null);caKs.setCertificateEntry("ca-certificate", caCert);TrustManagerFactory tmf = TrustManagerFactory.getInstance("X509");tmf.init(caKs);// client key and certificates are sent to server so it can authenticateKeyStore ks = KeyStore.getInstance(KeyStore.getDefaultType());ks.load(null, null);ks.setCertificateEntry("certificate", cert);ks.setKeyEntry("private-key", key.getPrivate(), password.toCharArray(),new java.security.cert.Certificate[]{cert});KeyManagerFactory kmf = KeyManagerFactory.getInstance(KeyManagerFactory.getDefaultAlgorithm());kmf.init(ks, password.toCharArray());// finally, create SSL socket factorySSLContext context = SSLContext.getInstance("TLSv1.2");context.init(kmf.getKeyManagers(), tmf.getTrustManagers(), null);return context.getSocketFactory();}} MemoryPersistence persistence = new MemoryPersistence();try {//当未设置标识时随机一个if (StringUtils.isEmpty(clientId)) {clientId = UUID.randomUUID().toString().replace("-", "");}mqttAsyncClient = new MqttAsyncClient(serverURI, clientId, persistence);// MQTT 连接选项MqttConnectOptions connOpts = new MqttConnectOptions();//设置MQTT连接账号密码connOpts.setUserName(userName);if (!StringUtils.isEmpty(password)){connOpts.setPassword(password.toCharArray());}connOpts.setCleanSession(true);if (serverURI.indexOf("ssl")>=0){SSLSocketFactory socketFactory = SSLUtils.getSocketFactory(cacert, clientCert, clientKey, clientPassword);connOpts.setSocketFactory(socketFactory);}connOpts.setAutomaticReconnect(true);// 设置心跳秒数connOpts.setKeepAliveInterval(60);// 设置回调mqttReconnectCallback =new MqttReconnectCallback();mqttAsyncClient.setCallback(mqttReconnectCallback);mqttAsyncClient.connect(connOpts);} catch (Exception e) {}