帝国cms调用网站名称企业网站建设服务内容
设置组件的颜色渐变效果。
说明:
从API Version 7开始支持。后续版本如有新增内容,则采用上角标单独标记该内容的起始版本。
linearGradient
linearGradient(value: { angle?: number | string; direction?: GradientDirection; colors: Array; repeating?: boolean; })
线性渐变。
卡片能力: 从API version 9开始,该接口支持在ArkTS卡片中使用。
系统能力: SystemCapability.ArkUI.ArkUI.Full
参数:
| 参数名 | 类型 | 必填 | 说明 |
|---|---|---|---|
| value | { angle?: number | string, direction?: GradientDirection, colors: Array<[ResourceColor, number]>, repeating?: boolean } | 是 | 线性渐变。 - angle: 线性渐变的起始角度。0点方向顺时针旋转为正向角度。 默认值:180 - direction: 线性渐变的方向,设置angle后不生效。 默认值:GradientDirection.Bottom - colors: 指定某百分比位置处的渐变色颜色,设置非法颜色直接跳过。 - repeating: 为渐变的颜色重复着色。 默认值:false |
sweepGradient
sweepGradient(value: { center: Array; start?: number | string; end?: number | string; rotation?: number | string; colors: Array; repeating?: boolean; })
角度渐变。
卡片能力: 从API version 9开始,该接口支持在ArkTS卡片中使用。
系统能力: SystemCapability.ArkUI.ArkUI.Full
参数:
| 参数名 | 类型 | 必填 | 说明 |
|---|---|---|---|
| value | { center: Point, start?: number | string, end?: number | string, rotation?: number | string, colors: Array<[ResourceColor, number]>, repeating?: boolean } | 是 | 角度渐变,仅绘制0-360度范围内的角度,超出时不绘制渐变色,只绘制纯色。 - center:为角度渐变的中心点,即相对于当前组件左上角的坐标。 - start:角度渐变的起点。 默认值:0 - end:角度渐变的终点。 默认值:0 - rotation: 角度渐变的旋转角度。 默认值:0 - colors: 指定某百分比位置处的渐变色颜色,设置非法颜色直接跳过。 - repeating: 为渐变的颜色重复着色。 默认值:false 说明: 设置为小于0的值时,按值为0处理,设置为大于360的值时,按值为360处理。 当start、end、rotation的数据类型为string,值为"90"或"90%",与90效果一致 |
radialGradient
radialGradient(value: { center: Array; radius: number | string; colors: Array; repeating?: boolean })
径向渐变。
卡片能力: 从API version 9开始,该接口支持在ArkTS卡片中使用。
系统能力: SystemCapability.ArkUI.ArkUI.Full
参数:
| 参数名 | 类型 | 必填 | 说明 |
|---|---|---|---|
| value | { center: Point, radius: number | string, colors: Array<[ResourceColor, number]>, repeating?: boolean } | 是 | 径向渐变。 - center:径向渐变的中心点,即相对于当前组件左上角的坐标。 - radius:径向渐变的半径。 取值范围:[0,+∞) 说明: 设置为小于的0值时,按值为0处理。 - colors: 指定某百分比位置处的渐变色颜色,设置非法颜色直接跳过。 - repeating: 为渐变的颜色重复着色。 默认值:false |
说明:
colors参数的约束:
ResourceColor表示填充的颜色,number表示指定颜色所处的位置,取值范围为[0,1.0],0表示需要设置渐变色的容器的开始处,1.0表示容器的结尾处。想要实现多个颜色渐变效果时,多个数组中number参数建议递增设置,如后一个数组number参数比前一个数组number小的话,按照等于前一个数组number的值处理。
示例
// xxx.ets
@Entry
@Component
struct ColorGradientExample {build() {Column({ space: 5 }) {Text('linearGradient').fontSize(12).width('90%').fontColor(0xCCCCCC)Row().width('90%').height(50).linearGradient({angle: 90,colors: [[0xff0000, 0.0], [0x0000ff, 0.3], [0xffff00, 1.0]]})Text('linearGradient Repeat').fontSize(12).width('90%').fontColor(0xCCCCCC)Row().width('90%').height(50).linearGradient({direction: GradientDirection.Left, // 渐变方向repeating: true, // 渐变颜色是否重复colors: [[0xff0000, 0.0], [0x0000ff, 0.3], [0xffff00, 0.5]] // 数组末尾元素占比小于1时满足重复着色效果})}.width('100%').padding({ top: 5 })}
}
@Entry
@Component
struct ColorGradientExample {build() {Column({ space: 5 }) {Text('sweepGradient').fontSize(12).width('90%').fontColor(0xCCCCCC)Row().width(100).height(100).sweepGradient({center: [50, 50],start: 0,end: 359,colors: [[0xff0000, 0.0], [0x0000ff, 0.3], [0xffff00, 1.0]]})Text('sweepGradient Reapeat').fontSize(12).width('90%').fontColor(0xCCCCCC)Row().width(100).height(100).sweepGradient({center: [50, 50],start: 0,end: 359,rotation: 45, // 旋转角度repeating: true, // 渐变颜色是否重复colors: [[0xff0000, 0.0], [0x0000ff, 0.3], [0xffff00, 0.5]] // 数组末尾元素占比小于1时满足重复着色效果})}.width('100%').padding({ top: 5 })}
}
// xxx.ets
@Entry
@Component
struct ColorGradientExample {build() {Column({ space: 5 }) {Text('radialGradient').fontSize(12).width('90%').fontColor(0xCCCCCC)Row().width(100).height(100).radialGradient({center: [50, 50],radius: 60,colors: [[0xff0000, 0.0], [0x0000ff, 0.3], [0xffff00, 1.0]]})Text('radialGradient Repeat').fontSize(12).width('90%').fontColor(0xCCCCCC)Row().width(100).height(100).radialGradient({center: [50, 50],radius: 60,repeating: true,colors: [[0xff0000, 0.0], [0x0000ff, 0.3], [0xffff00, 0.5]] // 数组末尾元素占比小于1时满足重复着色效果})}.width('100%').padding({ top: 5 })}
}
最后,有很多小伙伴不知道学习哪些鸿蒙开发技术?不知道需要重点掌握哪些鸿蒙应用开发知识点?而且学习时频繁踩坑,最终浪费大量时间。所以有一份实用的鸿蒙(Harmony NEXT)资料用来跟着学习是非常有必要的。
这份鸿蒙(Harmony NEXT)资料包含了鸿蒙开发必掌握的核心知识要点,内容包含了(ArkTS、ArkUI开发组件、Stage模型、多端部署、分布式应用开发、音频、视频、WebGL、OpenHarmony多媒体技术、Napi组件、OpenHarmony内核、Harmony南向开发、鸿蒙项目实战等等)鸿蒙(Harmony NEXT)技术知识点。
希望这一份鸿蒙学习资料能够给大家带来帮助,有需要的小伙伴自行领取,限时开源,先到先得~无套路领取!!
获取这份完整版高清学习路线,请点击→纯血版全套鸿蒙HarmonyOS学习资料
鸿蒙(Harmony NEXT)最新学习路线
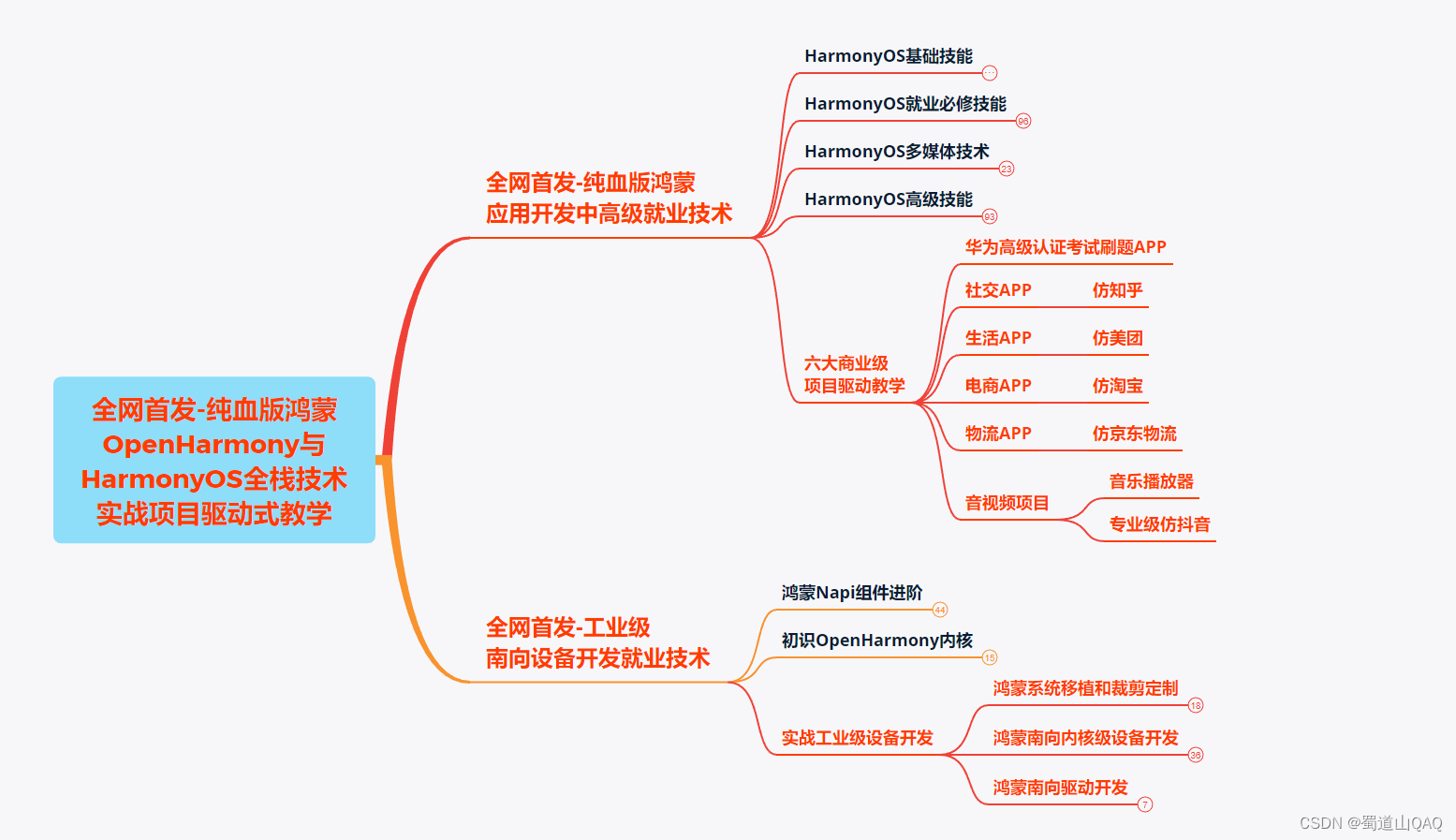
-
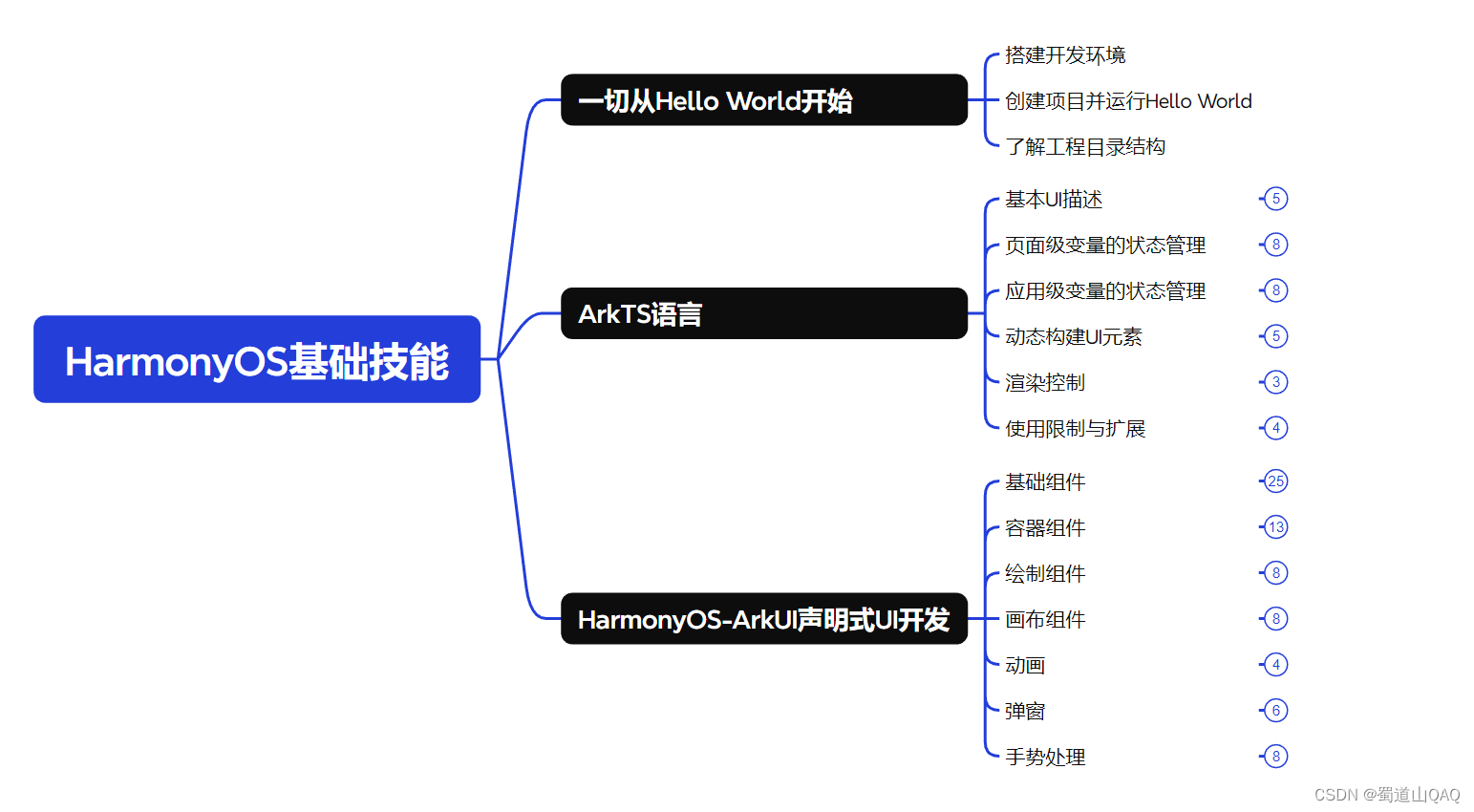
HarmonOS基础技能
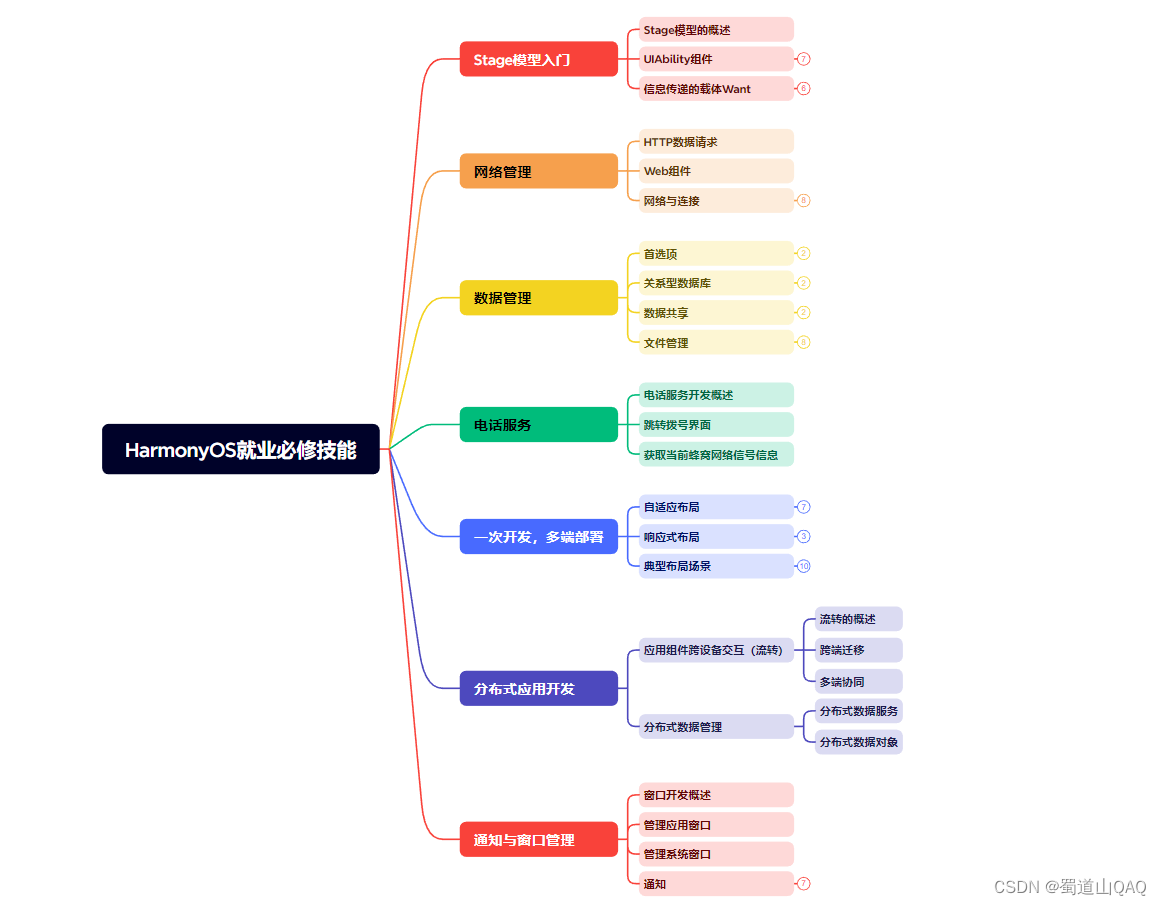
- HarmonOS就业必备技能
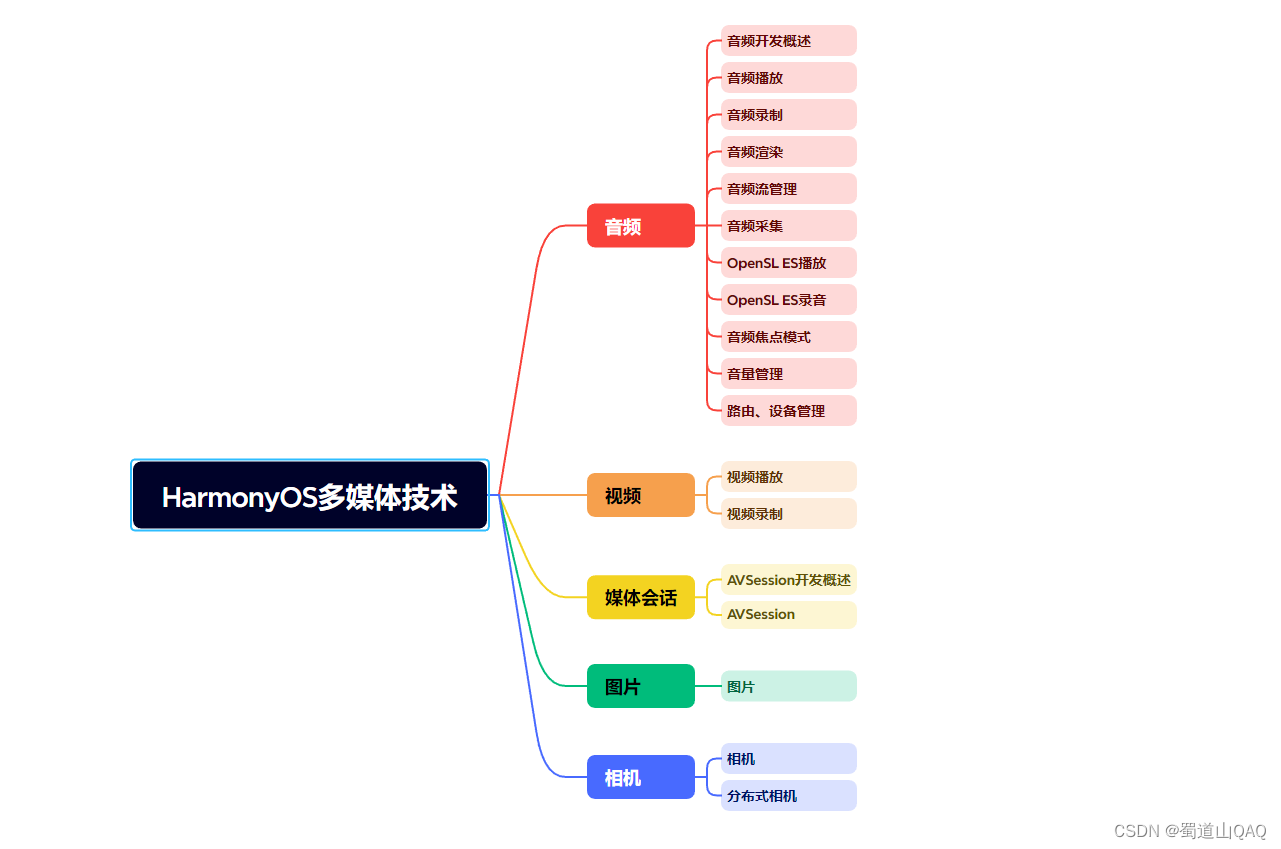
- HarmonOS多媒体技术
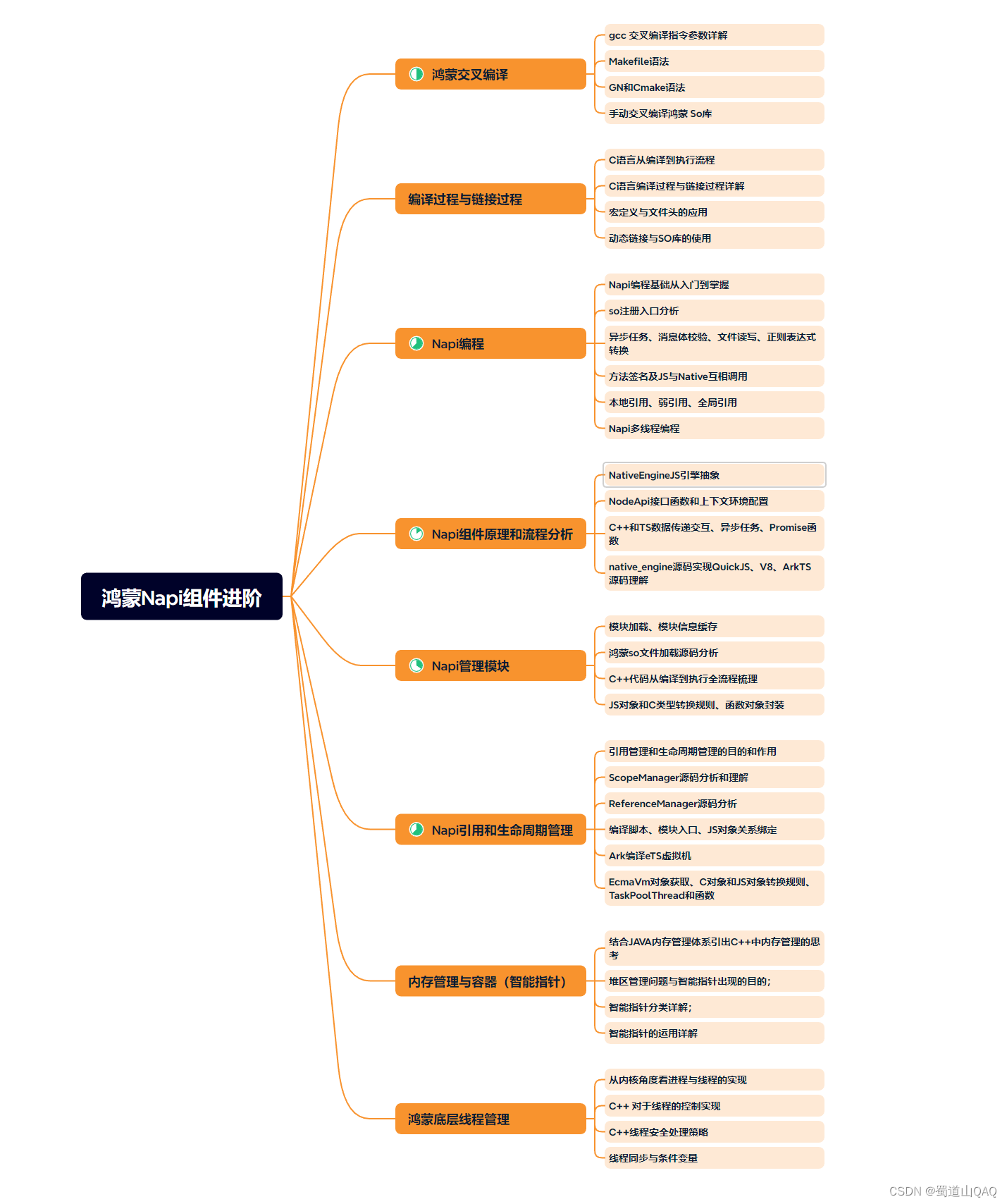
- 鸿蒙NaPi组件进阶
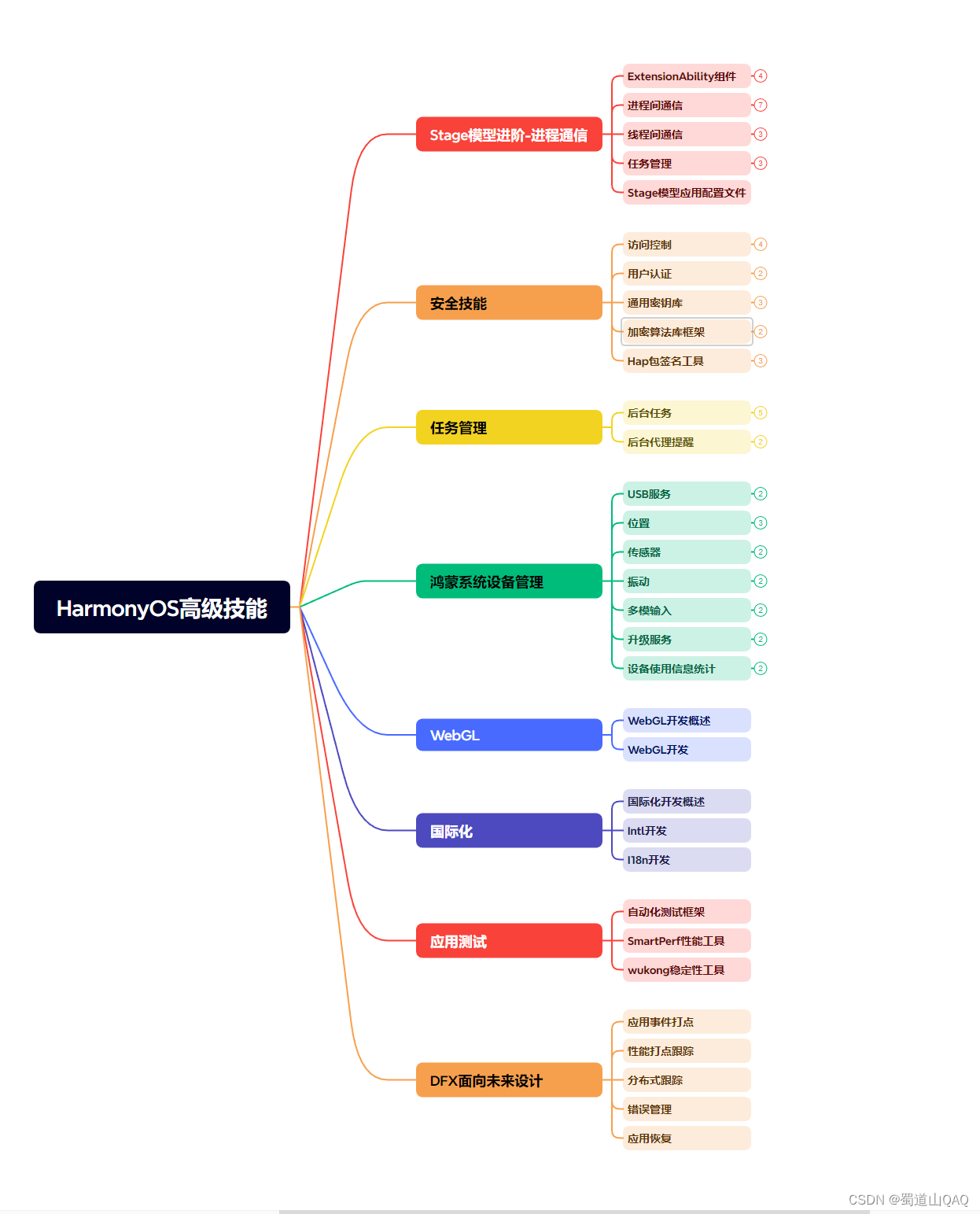
- HarmonOS高级技能
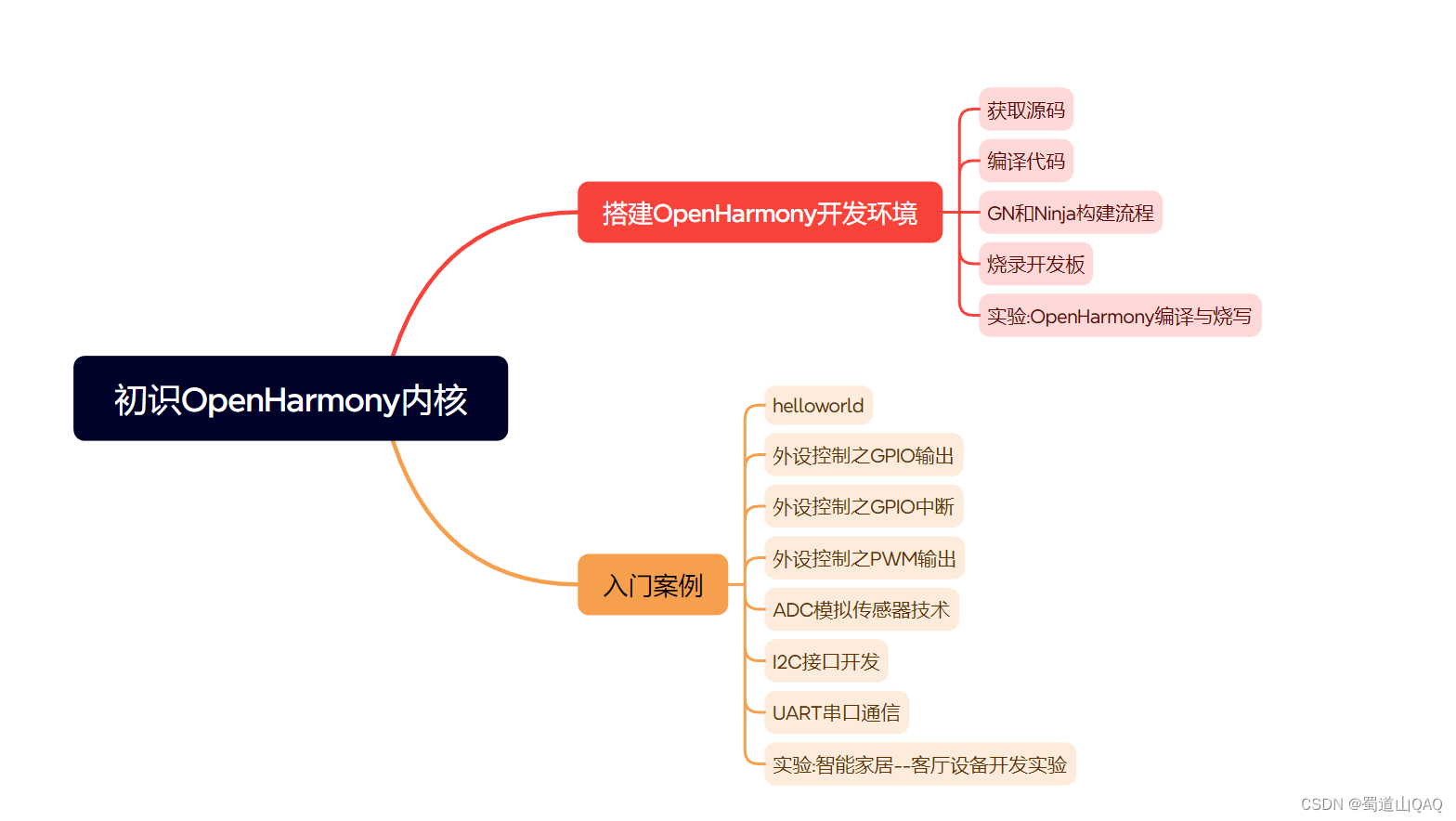
- 初识HarmonOS内核
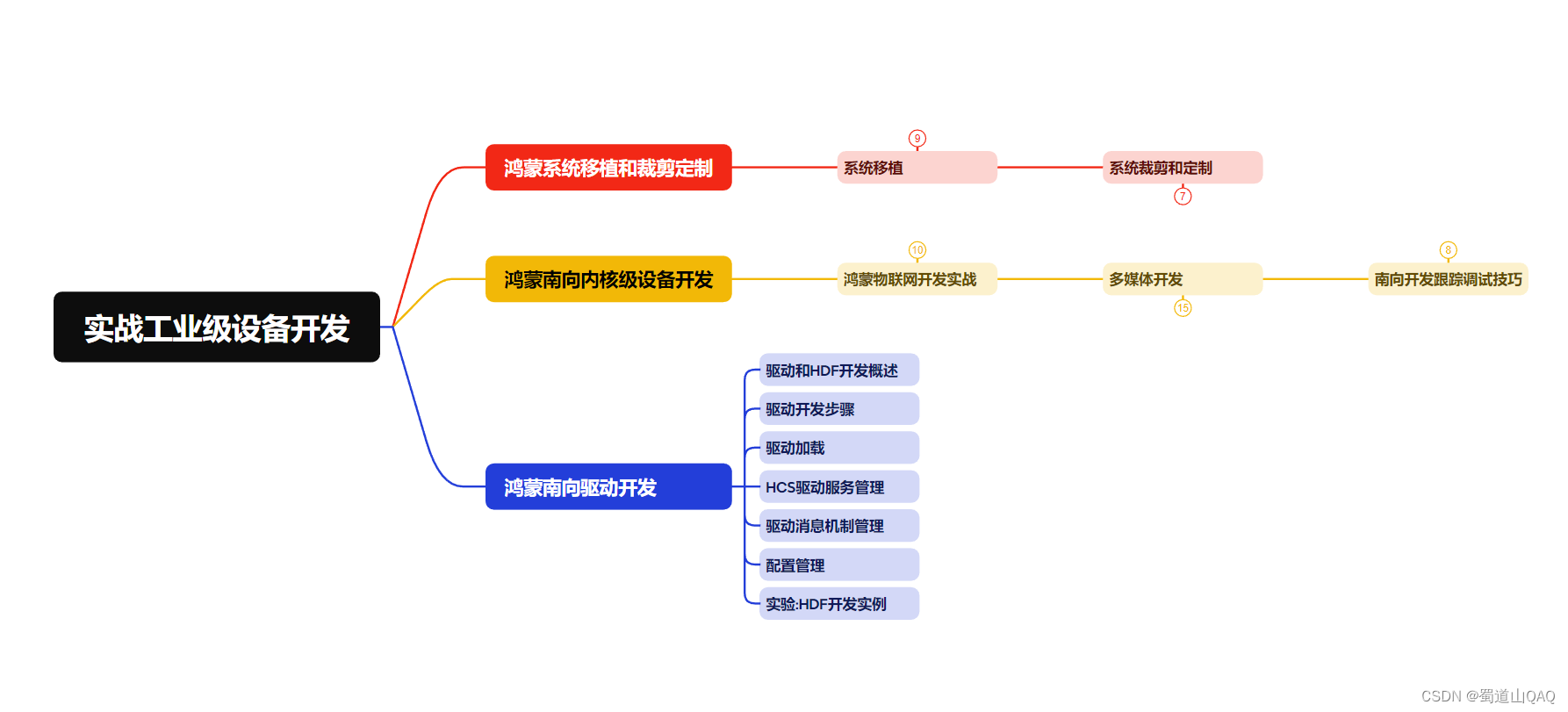
- 实战就业级设备开发
有了路线图,怎么能没有学习资料呢,小编也准备了一份联合鸿蒙官方发布笔记整理收纳的一套系统性的鸿蒙(OpenHarmony )学习手册(共计1236页)与鸿蒙(OpenHarmony )开发入门教学视频,内容包含:ArkTS、ArkUI、Web开发、应用模型、资源分类…等知识点。
获取以上完整版高清学习路线,请点击→纯血版全套鸿蒙HarmonyOS学习资料
《鸿蒙 (OpenHarmony)开发入门教学视频》

《鸿蒙生态应用开发V2.0白皮书》

《鸿蒙 (OpenHarmony)开发基础到实战手册》
OpenHarmony北向、南向开发环境搭建
《鸿蒙开发基础》
- ArkTS语言
- 安装DevEco Studio
- 运用你的第一个ArkTS应用
- ArkUI声明式UI开发
- .……
《鸿蒙开发进阶》
- Stage模型入门
- 网络管理
- 数据管理
- 电话服务
- 分布式应用开发
- 通知与窗口管理
- 多媒体技术
- 安全技能
- 任务管理
- WebGL
- 国际化开发
- 应用测试
- DFX面向未来设计
- 鸿蒙系统移植和裁剪定制
- ……

《鸿蒙进阶实战》
- ArkTS实践
- UIAbility应用
- 网络案例
- ……

获取以上完整鸿蒙HarmonyOS学习资料,请点击→纯血版全套鸿蒙HarmonyOS学习资料
总结
总的来说,华为鸿蒙不再兼容安卓,对中年程序员来说是一个挑战,也是一个机会。只有积极应对变化,不断学习和提升自己,他们才能在这个变革的时代中立于不败之地。
