宁波网站建设设计价格定制网站建设案例课堂
详情点击链接:基于MAXENT模型的生物多样性生境模拟与保护优先区甄选、自然保护区布局优化及未来气候变化下评估中的应用及论文写作
一:生物多样性保护格局与自然保护区格局优化
1.我国生物多样性格局与分布;
2.我国自然保护区格局与分布;
3.自然保护区存在问题与及其原因分析;
4.自然保护区格局优化与国家公园建设进展;
5.自然保护区优化调整案例分享;
二:生物多样性生境模拟基础技术一
1.ArcGIS概念、功能及其应用;
2.ArcGIS软件安装;
3.ArcGIS操作界面、辅助模块及其他辅助软件;
4.ArcGIS数据形式与数据格式、数据格式之间的相互转换;
5.新地图要素的创建、数据加载、数据层操作与保存等;
6.数据属性表的编辑与查询;
7.投影/坐标系统基础;
8.投影系统处理策略;
9.投影系统的查看及转换方法;
三:生物多样性生境模拟基础技术二
1.各种格式空间数据的剪裁、拼接及提取;
2.矢量数据、删格数据的符号化;
3.专题图制作;
4.专题图版面设计、制图数据操作、地图标注、图幅整饰;
四:生物多样性生境模拟高级技术一
1.图层运算与叠加分析方法;
2.缓冲区分析技术;
3.插值技术;
五:生物多样性生境模拟高级技术二
1.基于DEM地理信息提取;
2.图层运算与叠加;
3.分区技术;
六:Maxent模型与数据收集
1.Maxent模型及安装;
2.生物多样性数据的收集和预处理;
3.影响生物多样性分布的自变量的收集和处理;

七:Maxent模型输入参数处理及模型运行
1.Maxent模型输入参数处理;
2.Maxent模型运行、输入与输出;
3.Maxent模型的参数设置、优化;
八:基于Maxent模型生物多样性热点模拟和保护区格局优化技术
1.Maxent模型的精度验证;
2.Maxent模型结果解读、优化;
3.基于Maxent模型的生物多样性热点区域呈现;
4.基于Maxent模型的自然保护区格局优化方法;

九:基于Marxan模型保护区优化与保护空缺甄选技术
1.Marxan模型的运行、输入和输出;
2.Marxan模型的参数设置、优化;
3.Marxan模型的精度验证;
4.Marxan模型结果优化;

十:Maxent模型在保护优先区甄选、自然保护区布局优化项目中的应用及论文写作
自然保护区的结构调整与布局优化,
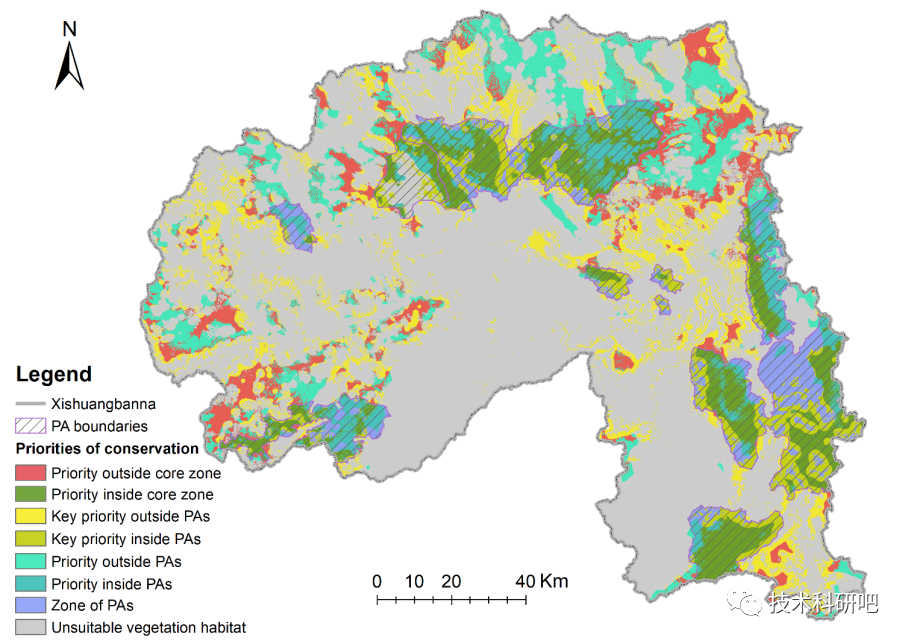
十一:Maxent模型在未来气候变化情景下自然保护区优化评估中的应用及论文写作
气候变化和人类活动共同影响未来生物多样性分布格局,自然保护区的结构调整和布局优化是一个动态而长期的过程。
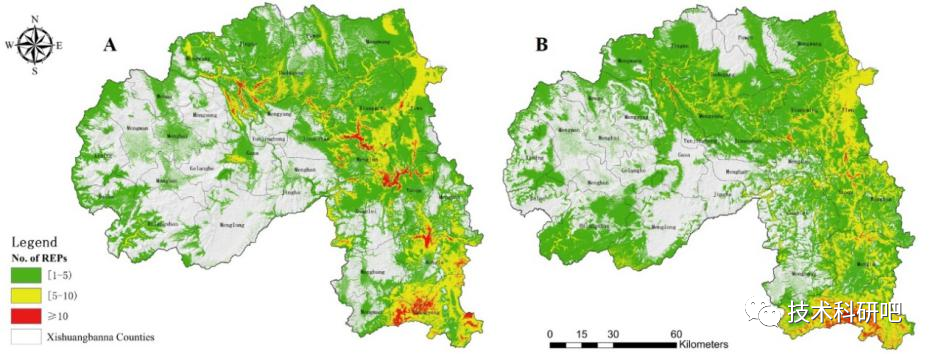
当前(左)和未来(右)生物多样性热点对比