山东济南网站建设如何网上赚点零花钱
通过给 Ingress 资源指定 Nginx Ingress 所支持的 annotation 可实现金丝雀发布。
需给服务创建2个 Ingress,其中1个常规 Ingress,另1个为带 nginx.ingress.kubernetes.io/canary: "true" 固定的 annotation 的 Ingress,称为 Canary Ingress。
Canary Ingress 一般代表新版本的服务,结合另外针对流量切分策略的 annotation 一起配置即可实现多种场景的金丝雀发布。
以下为相关 annotation 的详细介绍:
-
nginx.ingress.kubernetes.io/canary-by-header
表示如果请求头中包含指定的 header 名称,并且值为always,就将该请求转发给该 Ingress 定义的对应后端服务。如果值为never则不转发,可以用于回滚到旧版。如果为其他值则忽略该 annotation。 -
nginx.ingress.kubernetes.io/canary-by-header-value
该 annotation 可以作为canary-by-header的补充,可指定请求头为自定义值,包含但不限于always或never。当请求头的值命中指定的自定义值时,请求将会转发给该 Ingress 定义的对应后端服务,如果是其它值则忽略该 annotation。 -
nginx.ingress.kubernetes.io/canary-by-header-pattern
与canary-by-header-value类似,区别为该 annotation 用正则表达式匹配请求头的值,而不是只固定某一个值。如果该 annotation 与canary-by-header-value同时存在,该 annotation 将被忽略。 -
nginx.ingress.kubernetes.io/canary-by-cookie
与canary-by-header类似,该 annotation 用于 cookie,仅支持always和never。 -
nginx.ingress.kubernetes.io/canary-weight
表示 Canary Ingress 所分配流量的比例的百分比,取值范围 [0-100]。例如,设置为10,则表示分配10%的流量给 Canary Ingress 对应的后端服务。
一、部署蓝环境版本服务
1、ConfigMap
kind: ConfigMap
apiVersion: v1
metadata:name: nginx-blue-config
data:nginx.conf: |-worker_processes 1;events {accept_mutex on;multi_accept on;use epoll;worker_connections 1024;}http {ignore_invalid_headers off;server {listen 80;location / {access_by_lua 'local header_str = ngx.say("blue")';}}}
2、Deployment
kind: Deployment
apiVersion: apps/v1
metadata:name: nginx-bluelabels:dce.daocloud.io/app: nginx-blueannotations:dce.daocloud.io/last-replicas: '1'deployment.kubernetes.io/revision: '3'kubernetes.io/change-cause: update YAML
spec:replicas: 1selector:matchLabels:dce.daocloud.io/component: nginx-bluetemplate:metadata:name: nginx-bluelabels:dce.daocloud.io/app: nginx-bluedce.daocloud.io/component: nginx-blueannotations:dce.daocloud.io/parcel.egress.burst: '0'dce.daocloud.io/parcel.egress.rate: '0'dce.daocloud.io/parcel.ingress.burst: '0'dce.daocloud.io/parcel.ingress.rate: '0'dce.daocloud.io/parcel.net.type: calicospec:volumes:- name: nginx-blue-configconfigMap:name: nginx-blue-configdefaultMode: 420containers:- name: nginx-blueimage: 'x.x.x.x/library/openresty:1.19.9.1-sw-r4'resources:limits:cpu: 500mmemory: '314572800'requests:cpu: 200mmemory: '314572800'volumeMounts:- name: nginx-blue-configmountPath: /etc/nginx/nginx.confsubPath: nginx.conf3、Service
kind: Service
apiVersion: v1
metadata:name: nginx-blue-defaultlabels:dce.daocloud.io/app: nginx-blueannotations:io.daocloud.dce.serviceSelectorType: service
spec:ports:- name: nginx-nginx-default-80680-80protocol: TCPport: 80targetPort: 80nodePort: 31046selector:dce.daocloud.io/component: nginx-blueclusterIP: 172.31.69.137type: NodePortsessionAffinity: NoneexternalTrafficPolicy: Cluster4、修改pod内容
cd /usr/local/openresty/nginx/html/ls
50x.html index.htmlecho "Hello Blue" > index.htmlcat index.html
Hello Blue二、部署绿环境版本服务
1、ConfigMap
kind: ConfigMap
apiVersion: v1
metadata:name: nginx-green-config
data:nginx.conf: |-worker_processes 1;events {accept_mutex on;multi_accept on;use epoll;worker_connections 1024;}http {ignore_invalid_headers off;server {listen 80;location / {access_by_lua 'local header_str = ngx.say("green")';}}}
2、Deployment
kind: Deployment
apiVersion: apps/v1
metadata:name: nginx-greenlabels:dce.daocloud.io/app: nginx-greenannotations:deployment.kubernetes.io/revision: '5'kubernetes.io/change-cause: update YAML
spec:replicas: 1selector:matchLabels:dce.daocloud.io/component: nginx-greentemplate:metadata:name: nginx-greenlabels:dce.daocloud.io/app: nginx-greendce.daocloud.io/component: nginx-greenenv: greenannotations:dce.daocloud.io/parcel.egress.burst: '0'dce.daocloud.io/parcel.egress.rate: '0'dce.daocloud.io/parcel.ingress.burst: '0'dce.daocloud.io/parcel.ingress.rate: '0'dce.daocloud.io/parcel.net.type: calicodce.daocloud.io/parcel.net.value: default-ipv4-ippoolspec:volumes:- name: nginx-green-configconfigMap:name: nginx-green-configdefaultMode: 420containers:- name: nginx-greenimage: 'x.x.x.x/library/openresty:1.19.9.1-sw-r4'resources:limits:cpu: 500mmemory: '314572800'requests:cpu: 200mmemory: '314572800'volumeMounts:- name: nginx-green-configmountPath: /etc/nginx/nginx.confsubPath: nginx.conf3、Service
kind: Service
apiVersion: v1
metadata:name: nginx-green-defaultlabels:dce.daocloud.io/app: nginx-greenannotations:io.daocloud.dce.serviceSelectorType: service
spec:ports:- name: nginx-nginx-default-15833-80protocol: TCPport: 80targetPort: 80nodePort: 35218selector:dce.daocloud.io/component: nginx-greenclusterIP: 172.31.207.22type: NodePortsessionAffinity: NoneexternalTrafficPolicy: Cluster4、修改pod内容
cd /usr/local/openresty/nginx/html/ls
50x.html index.htmlecho "Hello Green" > index.htmlcat index.html
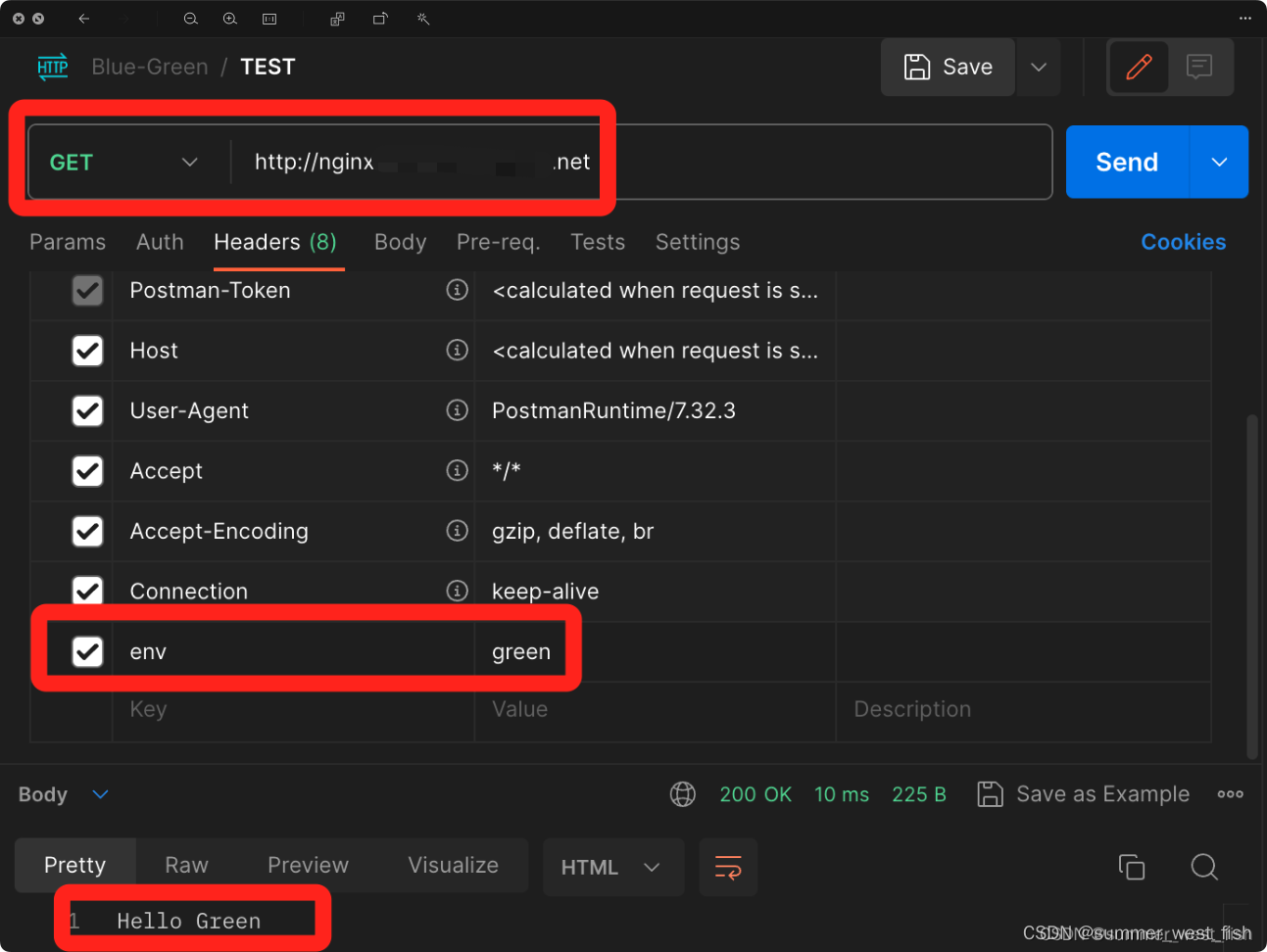
Hello Green三、设置Ingress
1、blue环境Ingress
kind: Ingress
apiVersion: networking.k8s.io/v1beta1
metadata:name: nginx-blue-ingresslabels:dce.daocloud.io/app: nginx-blueannotations:nginx.ingress.kubernetes.io/use-port-in-redirects: 'true'
spec:rules:- host: nginx.ms-sit.xxxxxx.nethttp:paths:- path: /pathType: ImplementationSpecificbackend:serviceName: nginx-blue-defaultservicePort: 802、green环境Ingress
kind: Ingress
apiVersion: networking.k8s.io/v1beta1
metadata:name: nginx-green-ingresslabels:dce.daocloud.io/app: nginx-greenannotations:kubernetes.io/ingress.class: nginxnginx.ingress.kubernetes.io/canary: 'true'nginx.ingress.kubernetes.io/canary-by-header: envnginx.ingress.kubernetes.io/canary-by-header-pattern: green
spec:rules:- host: nginx.ms-sit.xxxxxx.nethttp:paths:- path: /pathType: ImplementationSpecificbackend:serviceName: nginx-green-defaultservicePort: 80四、测试