建站哪家好就要用兴田德润学生作业 制作一个网站
文章目录
- 🛸虚拟局域网VLAN
- 🍔虚拟局域网VLAN的实现机制
- 🥚IEEE 802.1Q帧
- 🥚以太网交换机的接口类型
- 🗒️例一:在一个交换机上不进行人为的VLAN划分,交换机各接口默认属于VLAN1且类型为Access的情况。
- 🗒️例二:在一个交换机上划分两个不同VLAN的情况
- 🗒️例三:两个交换机通过Trunk类型的接口互连,Trunk接口将802.1Q帧“去标签”后进行转发的情况
- 🗒️例四:两个交换机通过Trunk类型的接口互连,Trunk接口将802.1Q帧直接转发的情况
- ⭐Access接口和Trunk接口的区别

🛸虚拟局域网VLAN
虚拟局域网是一种将局域网内的站点划分成与物理位置无关的逻辑组的技术,一个逻辑组就是一个VLAN,VLAN中的各站点具有某些共同的应用需求
如下图所示
1楼,2楼,3楼分别拥有一个局域网,将它们通过另外一个交换机互联成一个更大的互联网,那么,原来的每一个局域网就成了现在整个局域网的一个网段,网络中的各主机属于同一个广播域
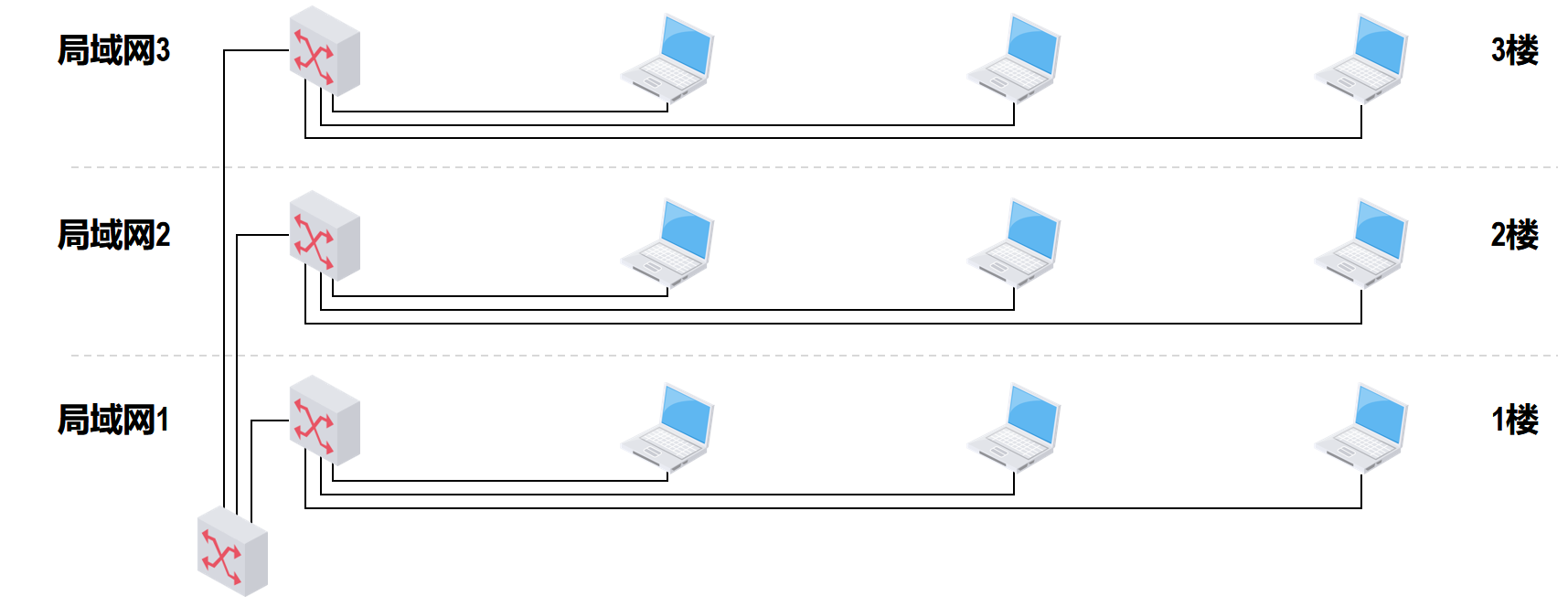
某个主机发送的广播帧,其他所有主机都会收到
根据应用需求,我们将这些主机划分到VLAN1中,将剩余主机划分到VLAN2中
这样,VLAN1中的广播帧就不会传送到VLAN2中了
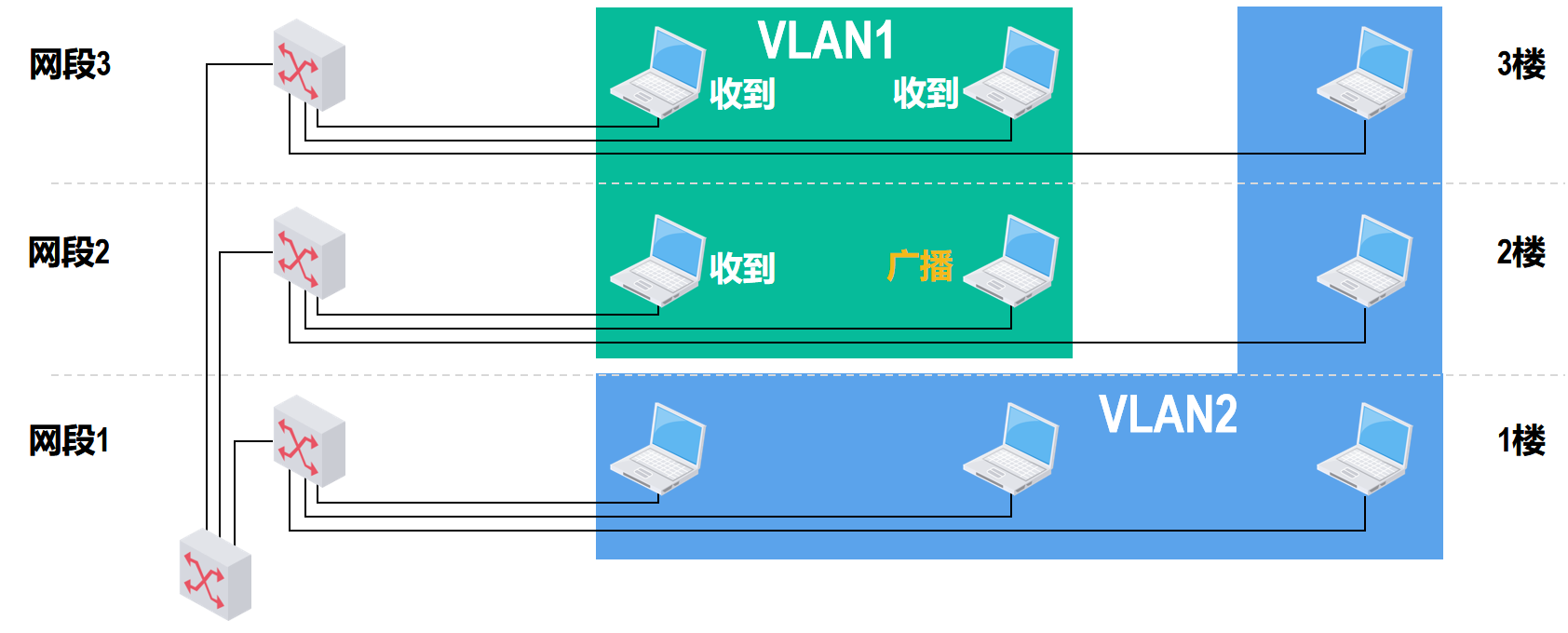
也就是说,属于同一VLAN的站点之间可以直接进行通信,而不同VLAN中的站点之间不能直接通信。

虚拟局域网VLAN并不是一种新型网络,它只是局域网能够提供给用户的一种服务
🍔虚拟局域网VLAN的实现机制

🥚IEEE 802.1Q帧
IEEE 802.1Q帧也称为Dot One Q帧,它对以太网V2的MAC帧格式进行了扩展:在源地址字段和类型字段之间插入了4字节的VLAN标签(tag)字段
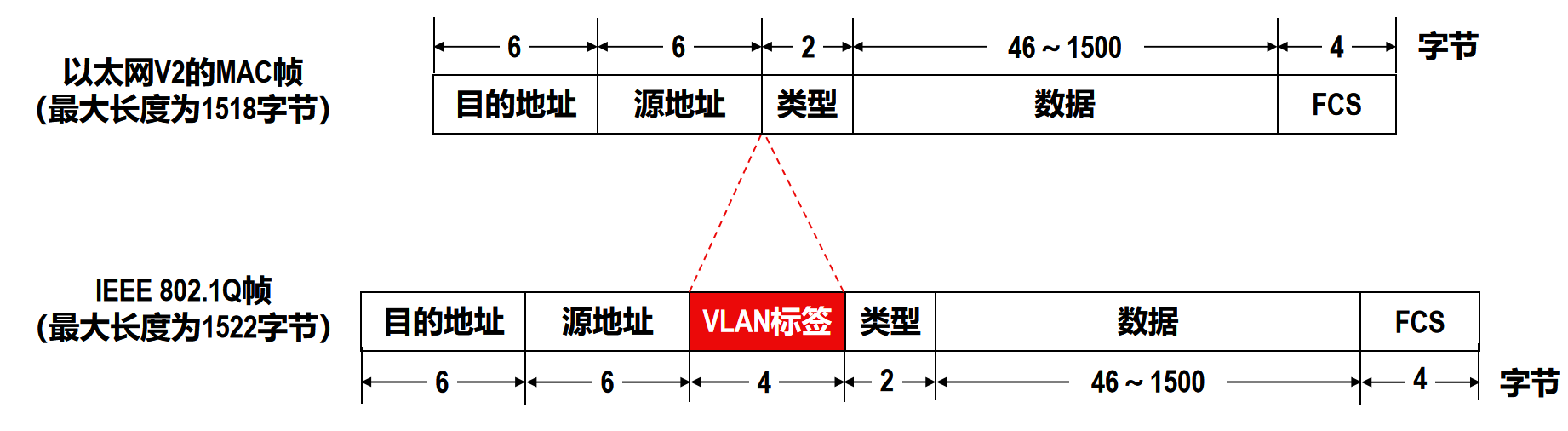
VLAN标签字段由标签协议标识符TPID,优先级PRI,规范格式指示符CFI,虚拟局域网标识VID四部分组成
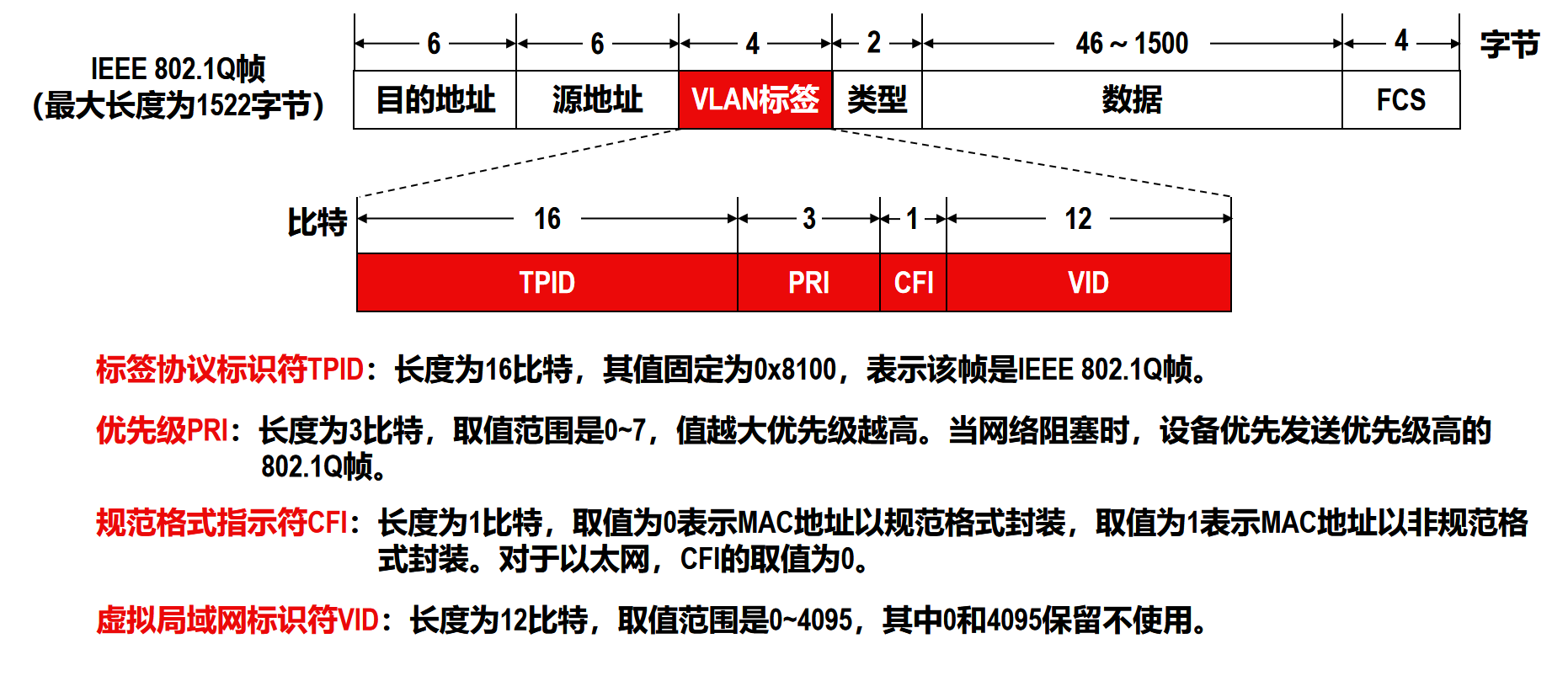

802.1Q帧一般不由用户主机处理,而是由以太网交换机来处理:

🥚以太网交换机的接口类型

交换机的每个接口有且仅有一个PVID
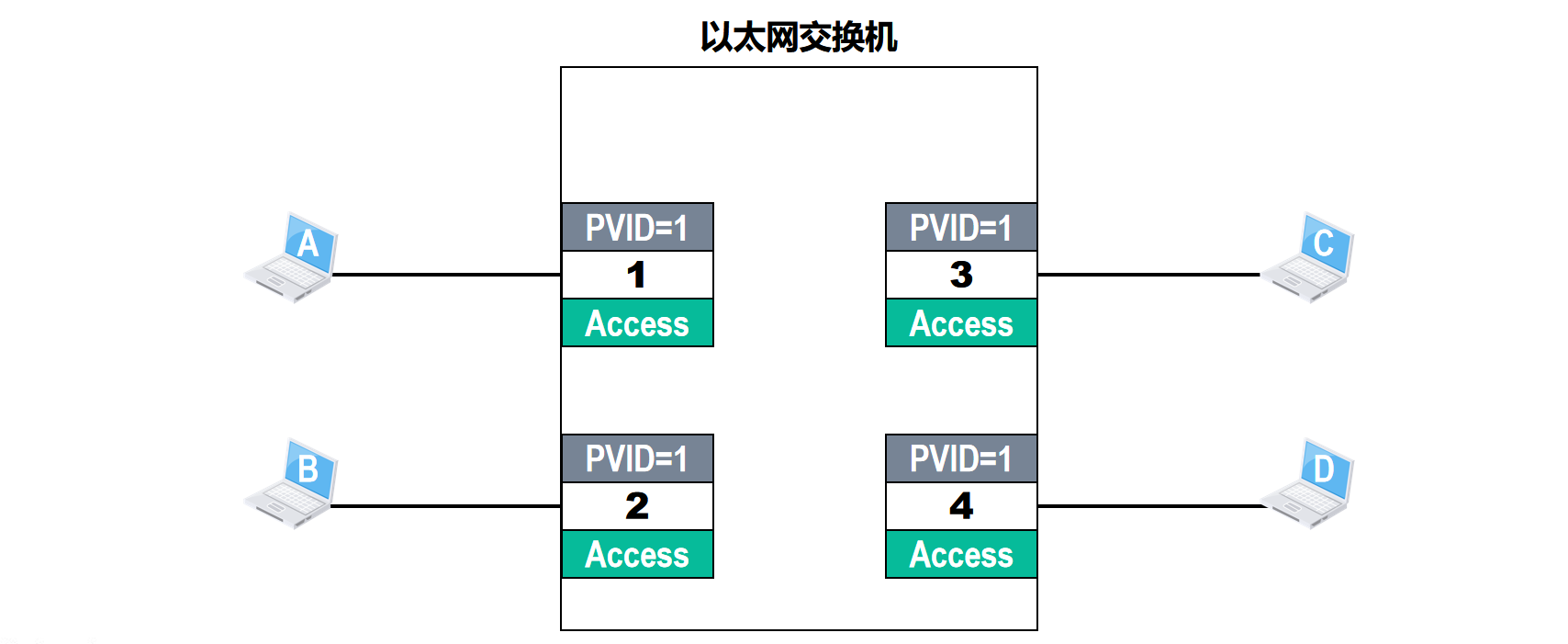
🗒️例一:在一个交换机上不进行人为的VLAN划分,交换机各接口默认属于VLAN1且类型为Access的情况。
主机ABCD分别连接在以太网交换机的一个接口上,交换机首次上电启动后,默认配置各接口属于VLAN1,即各接口的PVID值等于1。默认配置各接口的类型为Access
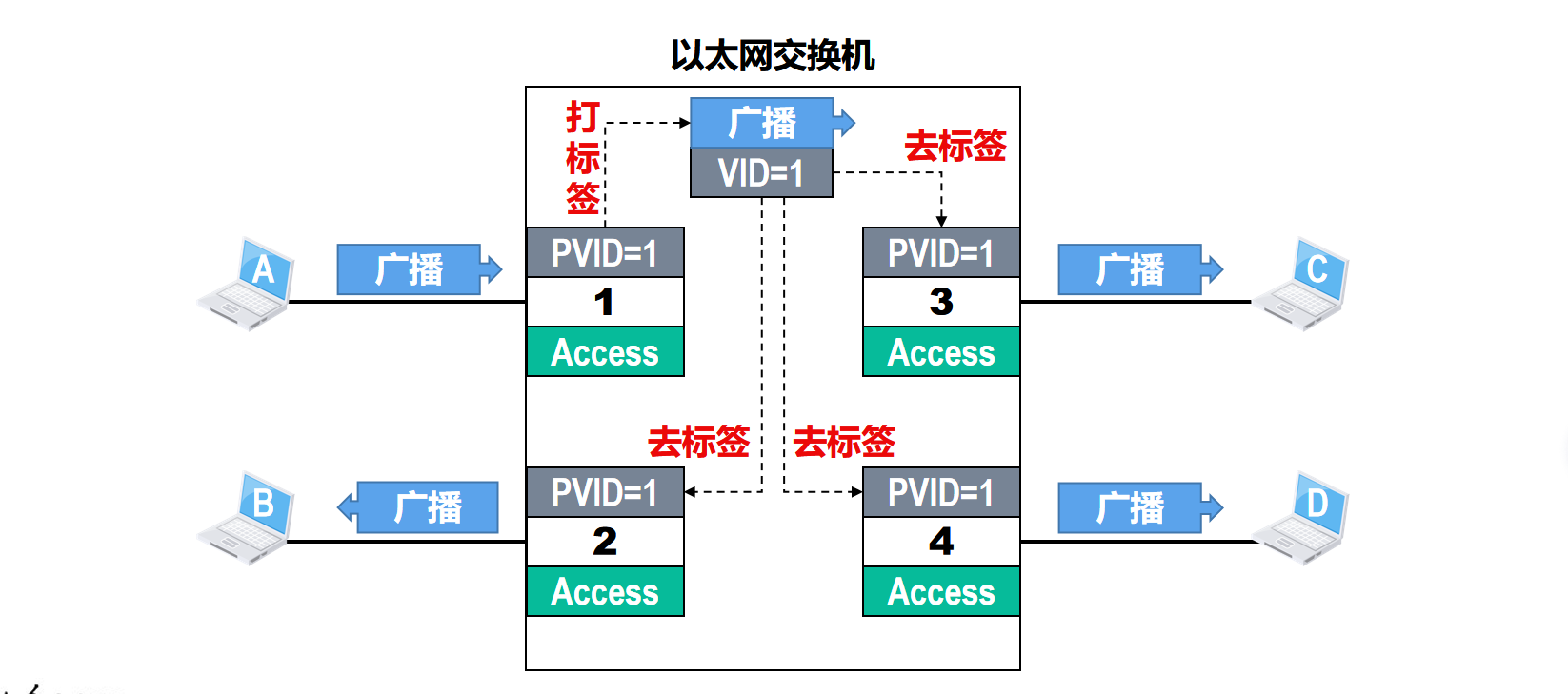
假设主机A发送了一个广播帧,该广播帧从交换机的接口1进入交换机,由于接口1的类型是Access,因此,它会对接受到的 未打标签 的普通以太网MAC帧 打标签,也就是插入4字节的VLAN标签
VLAN标签中的VID值等于接口中的PVID值1
交换机对打了标签的该广播帧进行转发,由于该广播帧中的VID值与交换机接口2 3 4的PVD值都等于1,因此,交换机会从这3个接口对该广播帧进行 去标签 转发
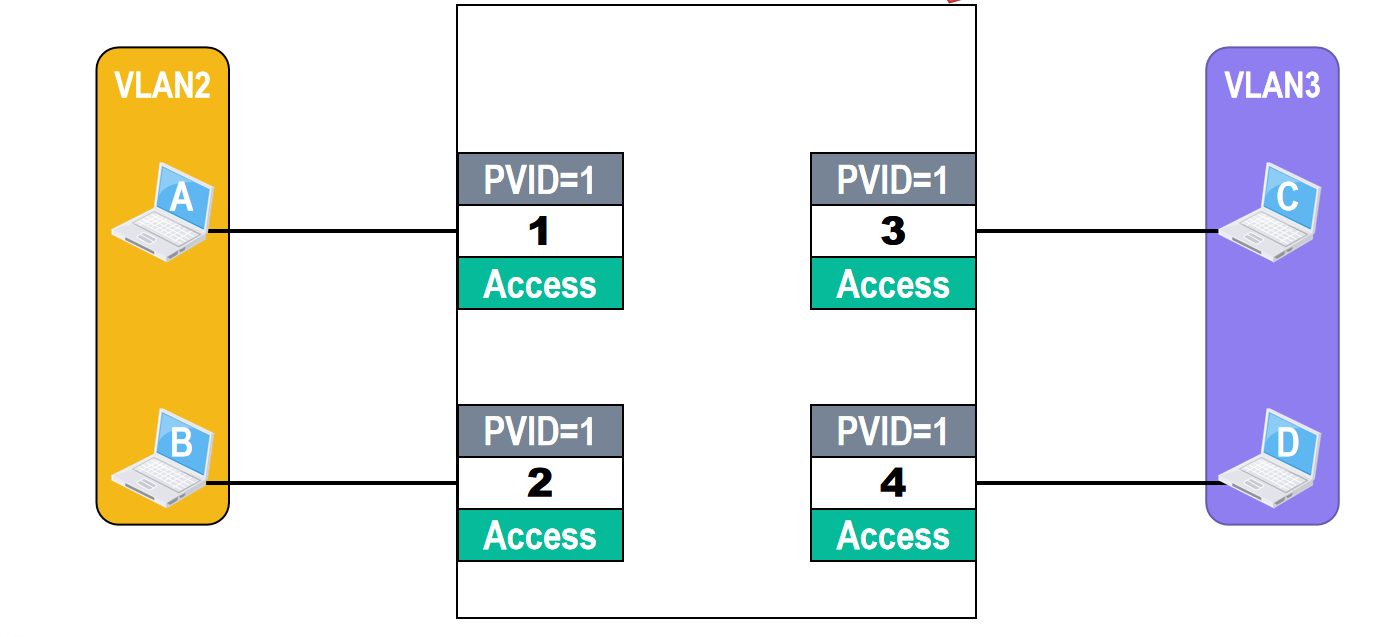
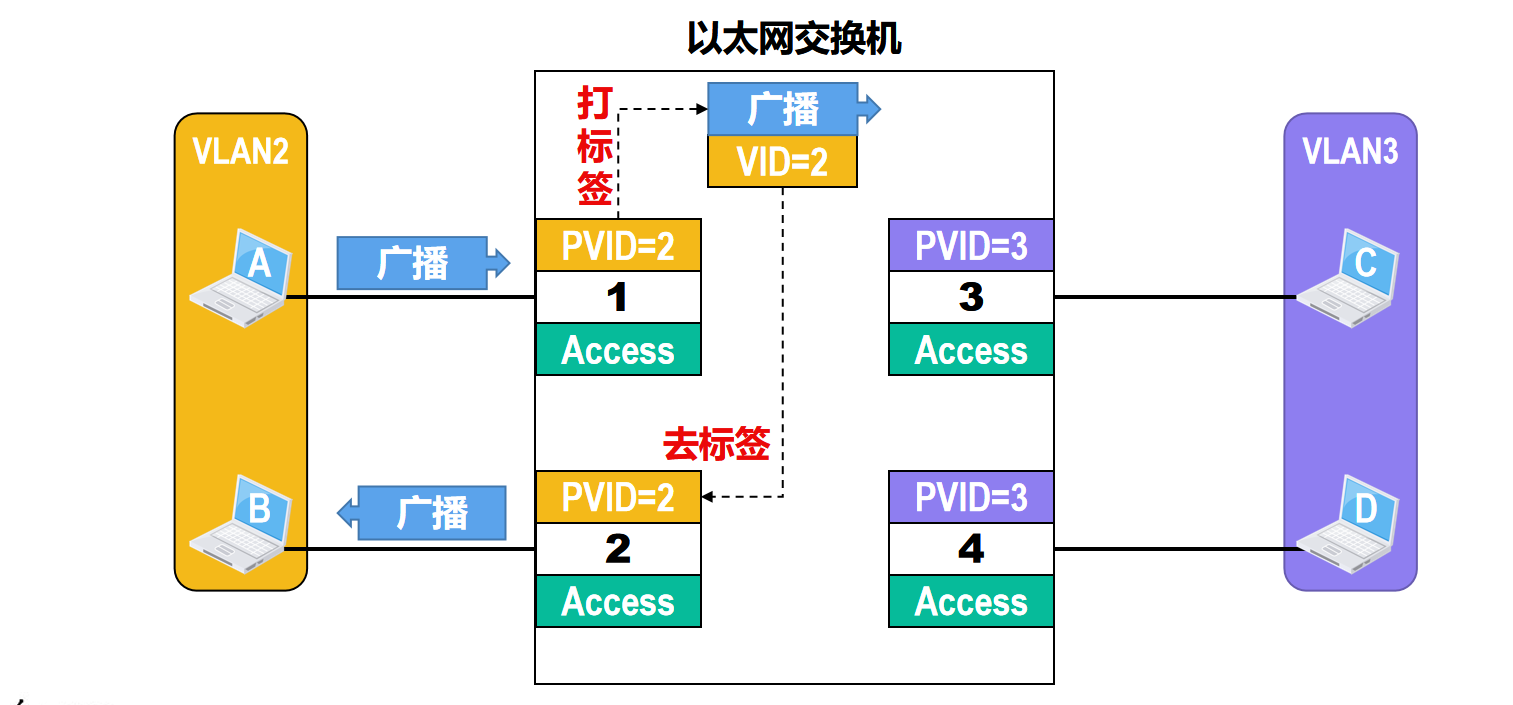
🗒️例二:在一个交换机上划分两个不同VLAN的情况
如图所示,主机ABCD分别连接在以太网交换机的一个接口上
需要将主机A和B划归到VLAN2
将主机C和D划归到VLAN3
这样,VLAN2中的广播帧不会传送到VLAN3中
为了实现这样的应用,可以在交换机上创建VLAN2和VLAN3,然后将交换机的接口1和2划归到VLAN2,接口3和4划归到VLAN3
因此,接口1和2的PVID值等于2,接口3和4的PVID值等于3
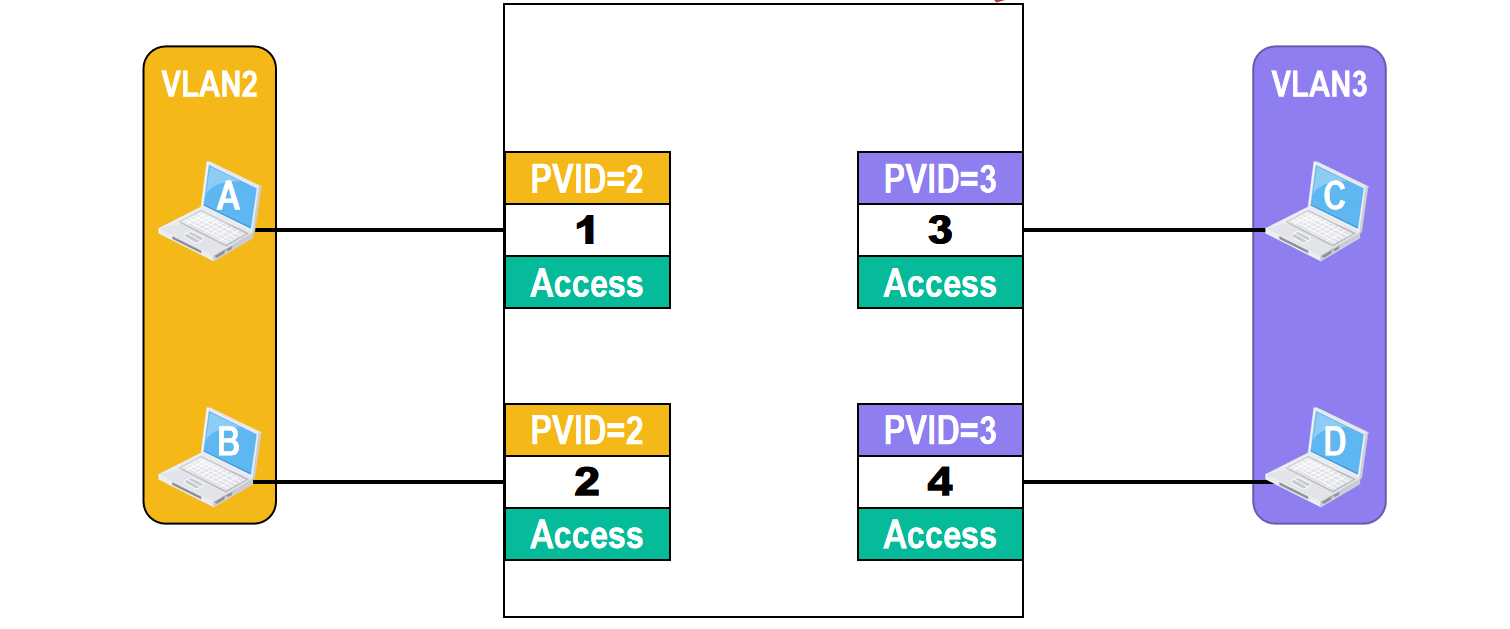
假设主机A发送了一个广播帧,该广播帧从交换机的接口1进入交换机
由于接口1的类型是Access,因此,它会对接受到的 未打标签 的普通以太网MAC帧打标签,也就是插入4字节的VLAN标签
VLAN标签中的VID值等于接口1的PVID值2
交换机对打了标签的该广播帧进行转发,由于广播帧中的VID值与交换机接口2的PVID值都等于2,因此,交换机会从接口2对该广播帧进行 去标签 转发
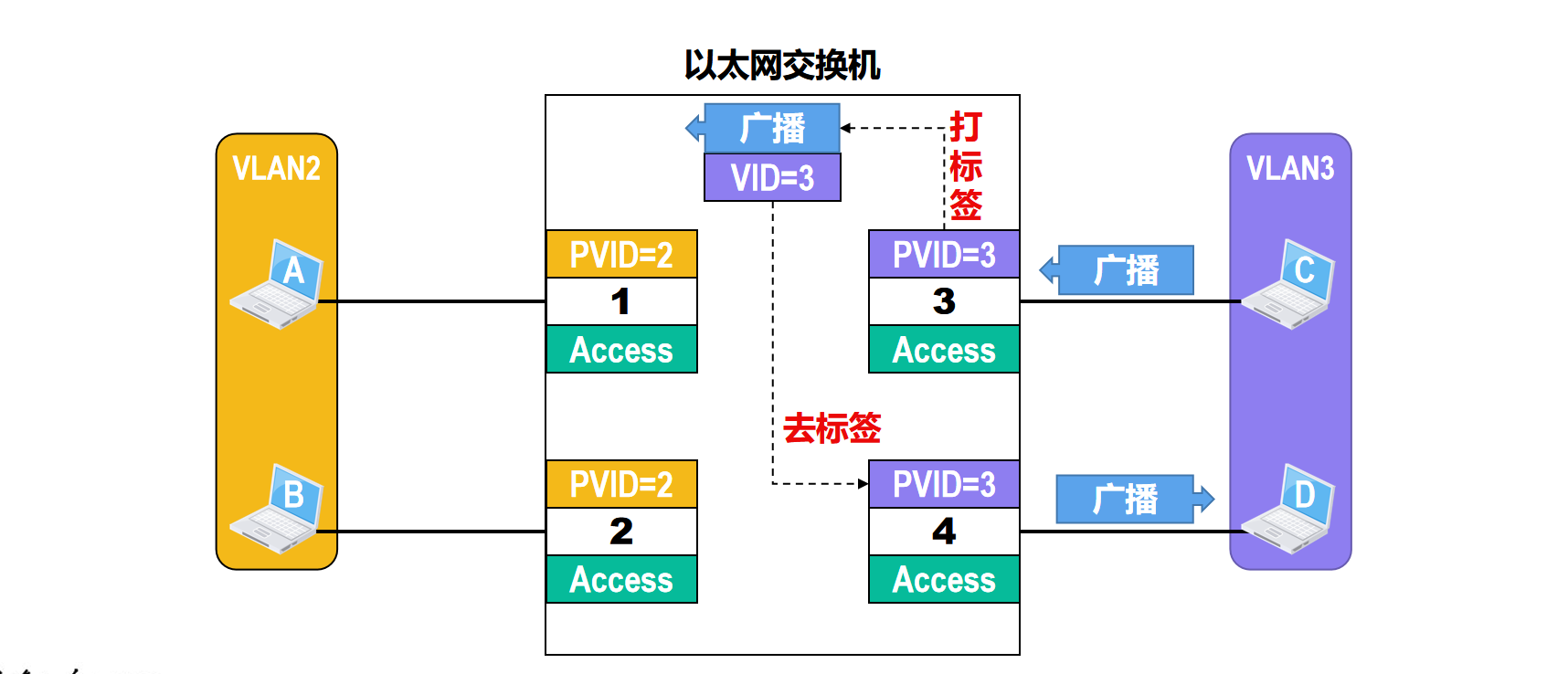
再来看主机C发送广播帧的情况
与主机A发送广播帧的情况是类似的
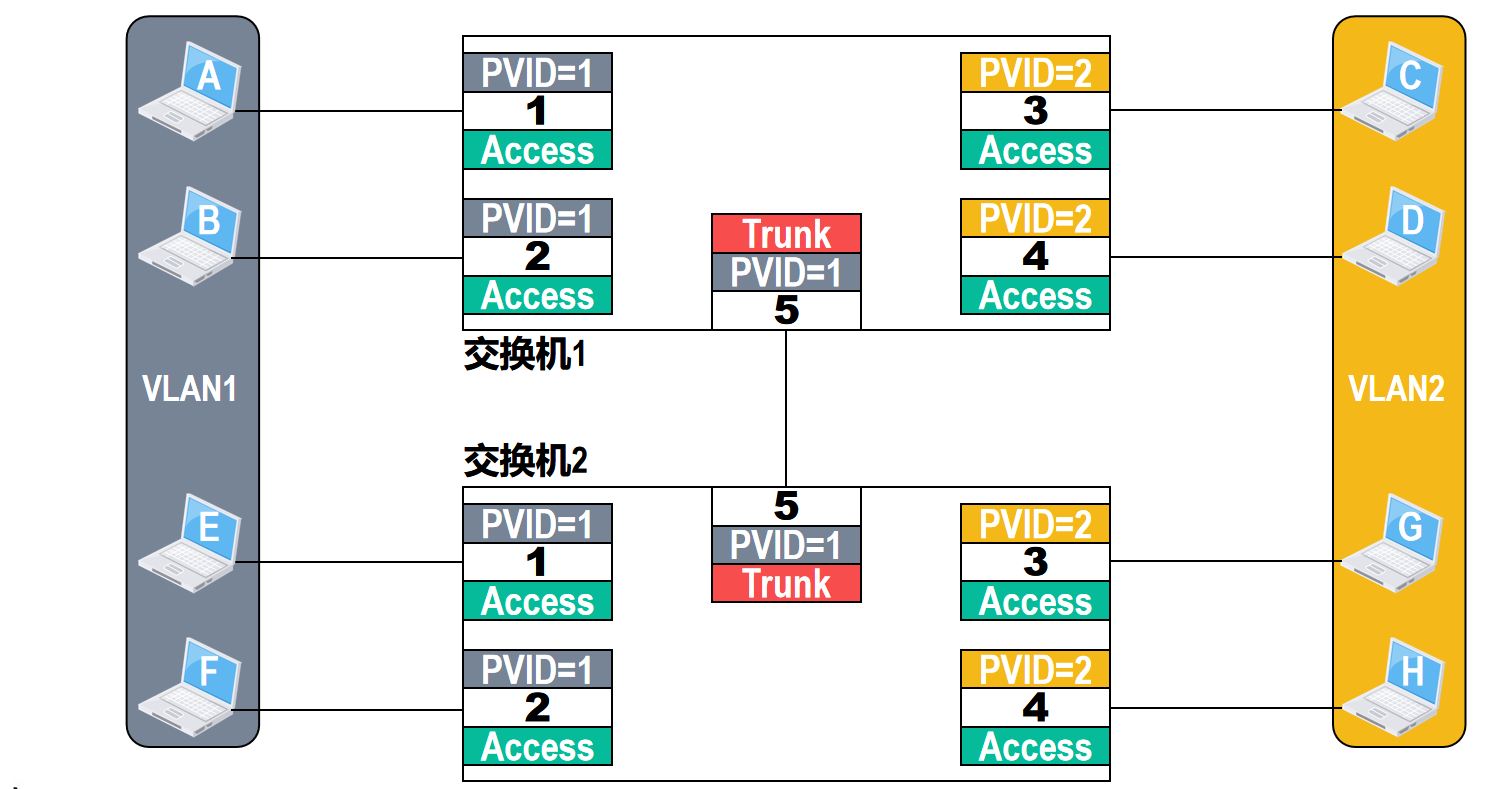
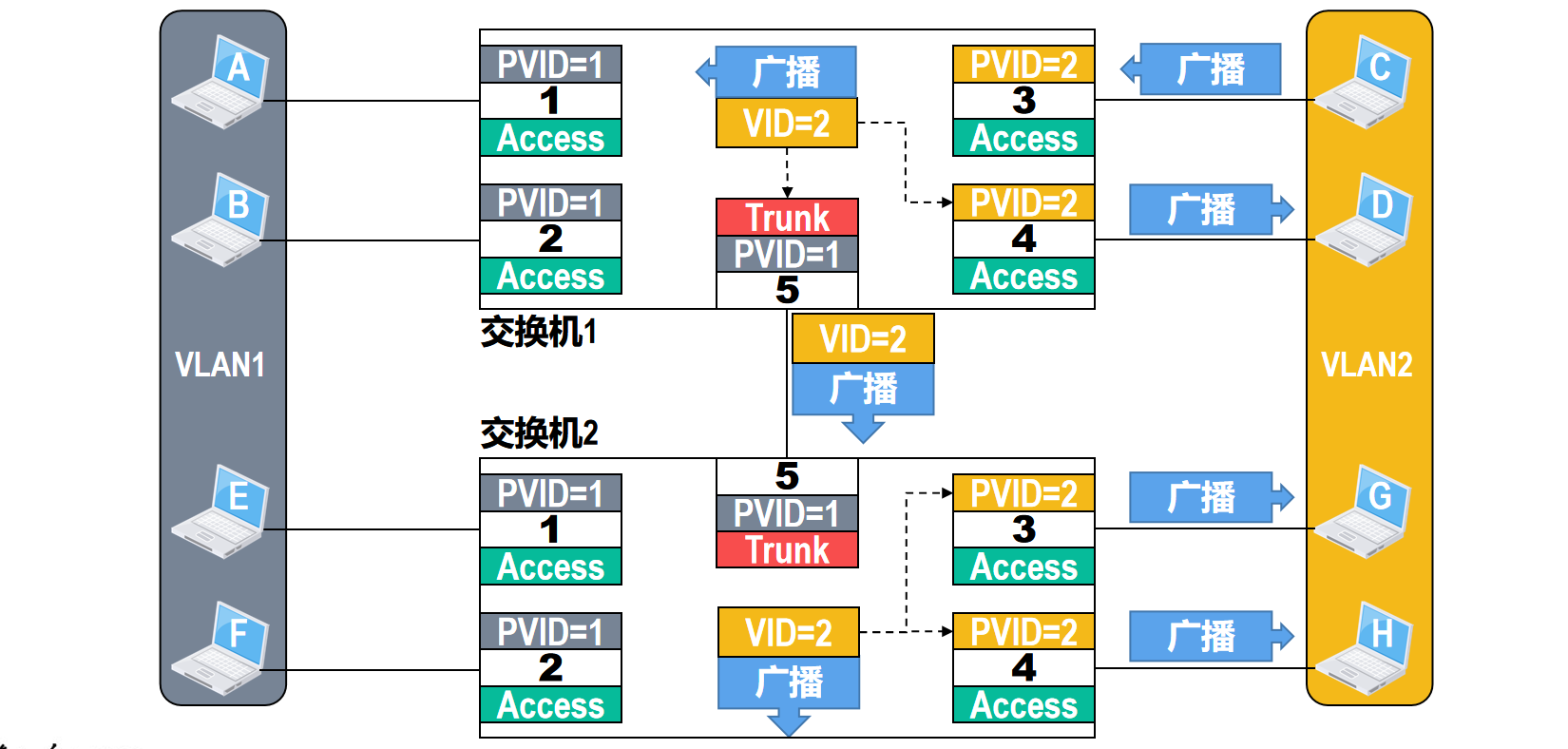
🗒️例三:两个交换机通过Trunk类型的接口互连,Trunk接口将802.1Q帧“去标签”后进行转发的情况
两台以太网交换机和多台主机互联成了一个交换式以太网,应用需求是将主机A,B,E和F划分到VLAN1,而将主机C,D,G和H划归到VLAN2
由于交换机首次上电启动后,默认配置各接口属于VLAN1,其相应的PVID值为1,接口类型为Access,因此,需要对这2台交换机进行相应的VLAN配置,才能满足应用需求
分别在这2台交换机上创建VLAN2,并将它们的接口3和4划归到VLAN2,其相应的PVID值为2
特别需要注意的是,2台交换机各自的接口5,由于它们用于2台交换机之间的连接,因此,需要将它们的接口类型更改为Trunk,而它们的PVID值保持默认值即可。
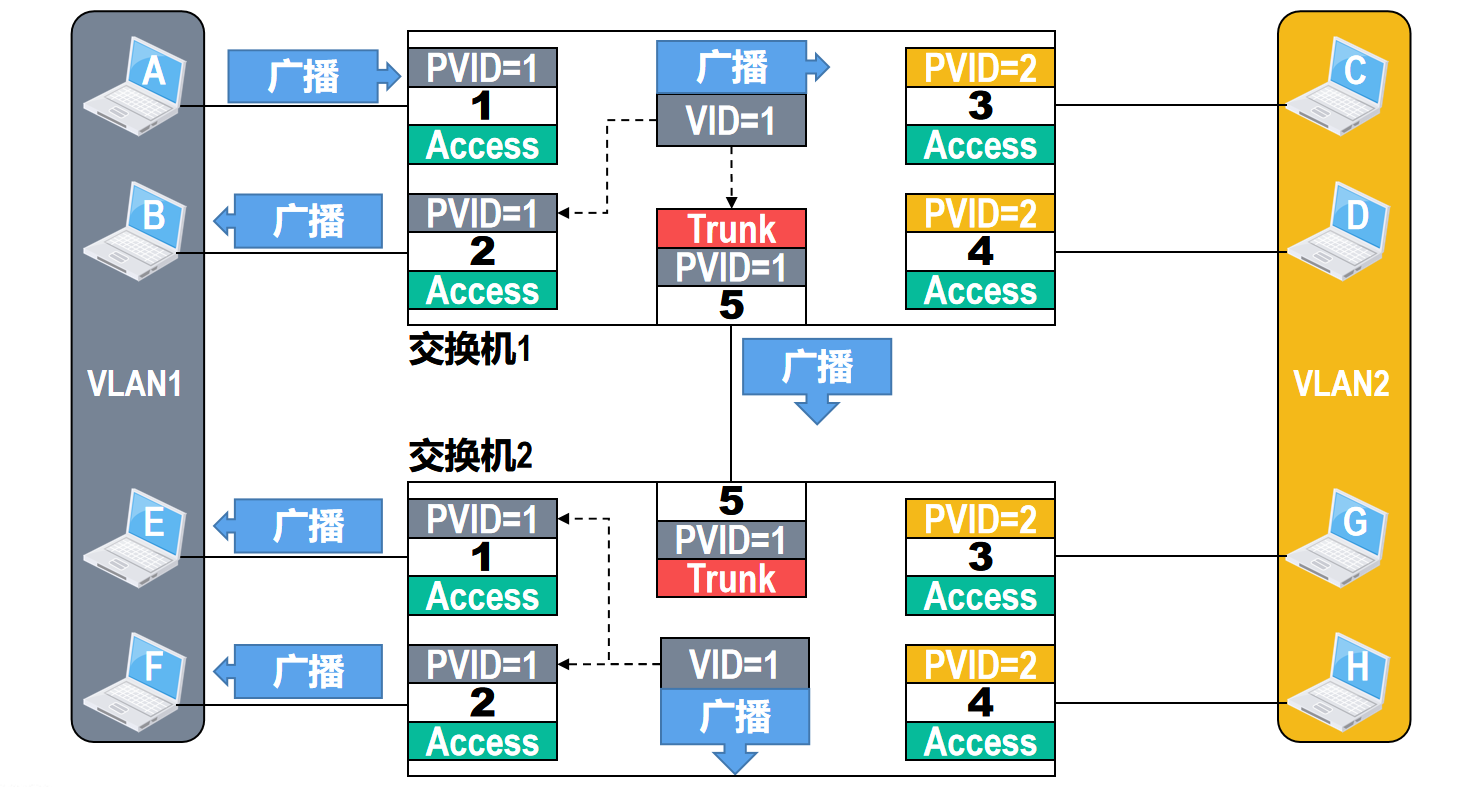
Trunk接口一般用在交换机之间或交换机与路由器之间的互连,Trunk接口可以属于多个VLAN,即Trunk接口可以通过不同VLAN的帧。默认情况下,Trunk接口的PVID值为1,一般不建议用户进行修改,若互联的Trunk接口的PVID值不相等,则可能出现转发错误
假设主机A发送了一个广播帧,交换机1对收到的帧进行处理,由于接口1的类型是Access,因此,它会对接收到的 未打标签 的普通以太网MAC帧打标签,也就是插入4字节的VLAN标签,VLAN标签中的VID值等于接口1的PVID值1
交换机1对打了标签的该广播帧进行转发,由于该广播帧中的VID值与交换机1的接口2的PVID值都等于1,因此,交换机1会从接口2对该广播帧进行 去标签 转发
另外,因为交换机1的接口5是Trunk类型,所以该广播帧还会从交换机1的接口5转发出去
由于接口5的PVID值与该广播帧中的VID值都等于1,因此,交换机1会从接口5对该广播帧进行 去标签 转发
显然,交换机1将该广播帧以普通以太网MAC帧的形式转发给了交换机2,该广播帧从交换机2的接口5进入交换机2,交换机2对收到的帧进行处理。
由于接口5的类型是Trunk,因此,他会对接受到的 未打标签 的普通以太网MAC帧打标签,也就是插入4字节的VLAN标签
VLAN标签中的VID值等于接口5的PVID值1,交换机2对打了标签的该广播帧进行转发。
由于该广播帧中的VID值与交换机2的接口1和2的PVID值都等于1,因此,交换机2会从接口1和2对该广播帧进行 去标签 转发
🗒️例四:两个交换机通过Trunk类型的接口互连,Trunk接口将802.1Q帧直接转发的情况
主机C发送的广播帧从交换机1的接口3进入交换机1,交换机1对收到的帧进行处理,由于接口3的类型是Access,因此,它会对接收到 未打标签 的普通以太网MAC帧打标签,也就是插入4字节的VLAN标签,VLAN标签中的VID值,等于接口3的PVID值2
交换机1对打了标签的该广播帧进行转发,由于该广播帧中的VID值与交换机1的接口4的PVID值都等于2,因此,交换机1会从接口4对该广播帧进行去标签 转发
另外,因为交换机1的接口5是Trunk类型,所以该广播帧还会从交换机1的接口5转发出去,由于接口5的PVID值为1,这与该广播帧中的VID值2不相同,因此,交换机1会从接口5对该广播帧直接转发
显然,交换机1将该广播帧以IEEE802.1Q帧的形式转发给了交换机2,该广播帧从交换机2的接口5进入交换机2,交换机2对该广播帧进行转发
由于该广播帧中的VID值与交换机2的接口3和4的PVID值都等于2,因此,交换机2会从接口3和4对该广播帧进行 去标签 转发
⭐Access接口和Trunk接口的区别

