医疗网站的建设设计要注意什么为什么现在建设银行要下载网站激活
UMLChina受机械工业出版社委托,重新翻译《分析模式》。
Martin Fowler的“Analysis Patterns,Reusable Object Models”,原书出版于1997年,至今为止未出第2版。
2004年,机械工业出版社出版该书中译本《分析模式》。
2020年,人民邮电出版社重新翻译,出版新的中译本《分析模式》。
这一次,为什么又要重新翻译?
因为这一次不只是翻译,还要解决二十多年来读者经常抱怨但一直未解决的问题。
一、书中的模型全部改为UML,而且是中文!
“Analysis Patterns”的写作是在UML规范发布之前,作者从一些方法学中选择了类似于UML类图、序列图、状态机图、活动图、包图的表示法。
“Analysis Patterns”出版后,Martin Fowler在自己的网站上逐渐提供各章的UML图:
图1 MartinFowler.com的链接
但目前为止,只提供了6章(分别为2、3、4、5、6、8)。全书连带附录共18章,其中有15章有模型图。
2004年的机工中译本,在这方面没有做调整:
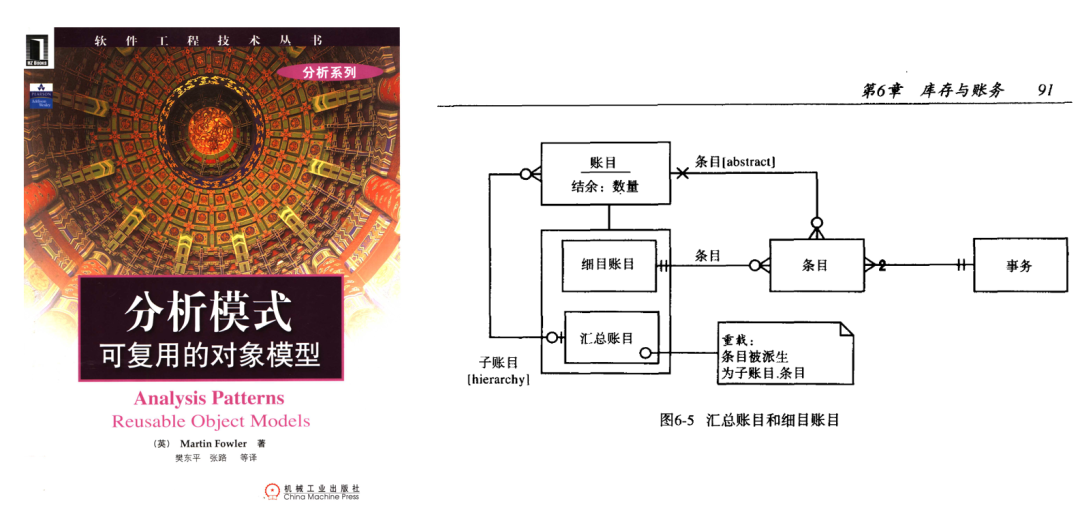
图2 2004年机工中译本第6章截图
到了2020年,人邮中译本在这方面还是没有做调整:
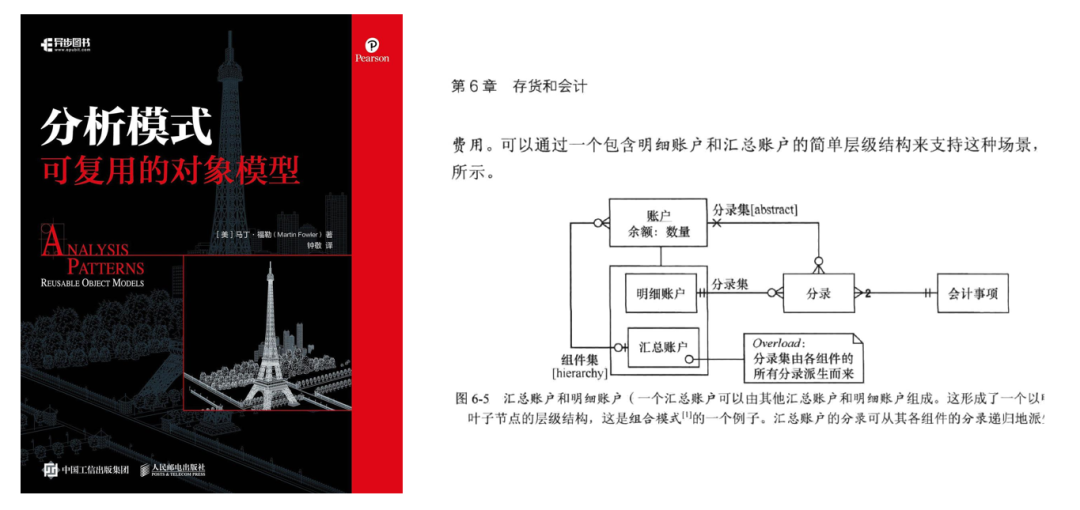
图3 2020年人邮中译本第6章截图
这一次的中译本,我们将
(1)把全部15章的模型图用UML表示
(2)用EA(Enterprise Architect)绘制,并向读者提供有所有图形的模型文件(eap、qea和xml格式)
(3)模型的内容是中文的!
我们可以对比原书第9章的图9-1和用EA绘制的图9-1:
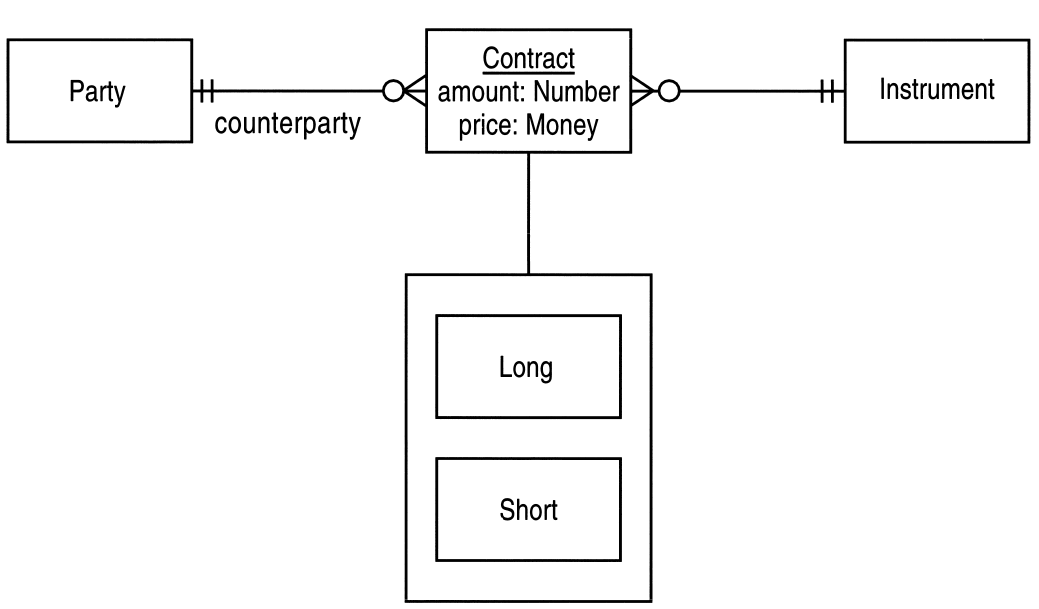
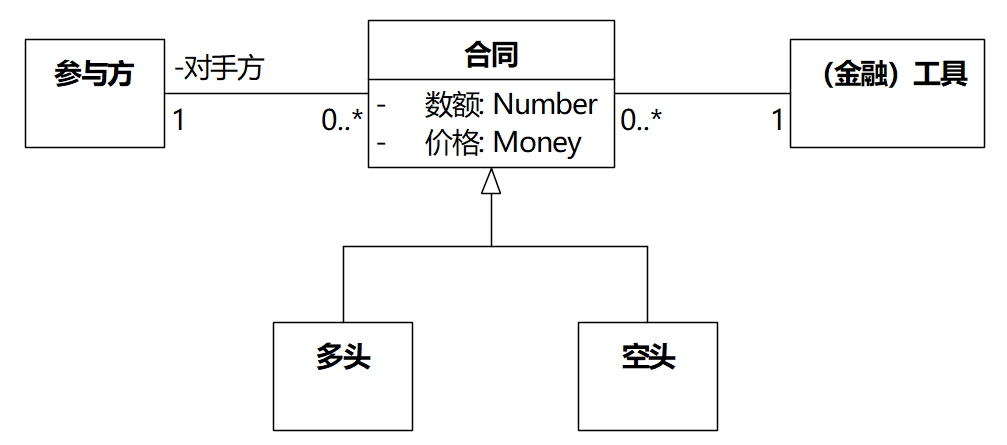
图4 原书模型图和EA绘制的中文模型图
二、修正原文存在的一些问题
在Fowler所写的书中,《分析模式》在读者中的热度远不如《企业应用架构模式》、《UML精粹》、《重构》等书,导致读者在阅读中的一些疑问一直没有得到很好的归集和解决。
本次中译本将解决这些问题。