宁波专业网站推广平台咨询商务网站制作工程师
在之前我们认识了docker的容器,了解了docker的相关概念:镜像,容器,仓库:面试官让你介绍一下docker,别再说不知道了
之后又带大家动手体验了一下docker从零开始玩转 Docker:一站式入门指南,带你快速掌握镜像、容器与仓库
但是在这之前都有一个前提,那就是我们本地已经安装好了docker,所以这篇文章教大家在Windows上安装docker,之前的教程太老了,这次来更新一下。
第一步,下载安装包
在Windows中docker有个桌面程序叫做Docker Desktop,这个是在mac和Windows上面独有的程序,在Linux上面是没有的,所以我们点击下载之后,我们会得到一个exe安装包

第二步,准备环境
先打开两个设置,控制面板》程序》启用或关闭windows功能》图中倒数第二和第三个点击勾选》重启电脑即可。

到本文发布截止时间,官网的exe包是4.33.1的版本,如果你的电脑太老了,这个时候就会出现下面的情况,这个时候我们需要安装4.24.1以下的版本。
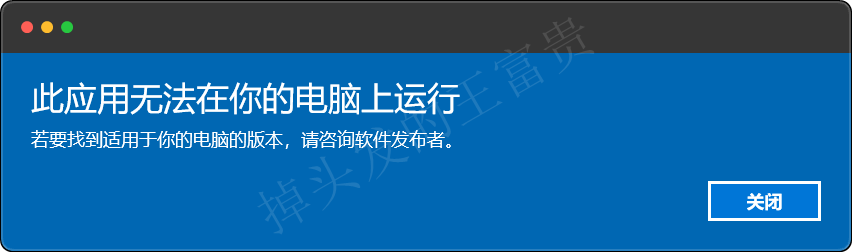
这里我们选的是4.24.0版本的,成功安装,老版本给大家分享一下,关注公众号 掉头发的王富贵 回复docker即可领取
第三步,安装
安装完成后就是这样的,页面叫我们注销一下以启用docker,我们按照他的提示执行就行了

第四步,注册账号
上面我们安装完成并且重启之后,进入这个软件,他会让我们注册一个账户,如果我们没有就可以先跳过这个环境以后注册也是可以的,跳过注册之后就是这样的一个页面了(不同版本的页面可能不同,但是大差不差的)
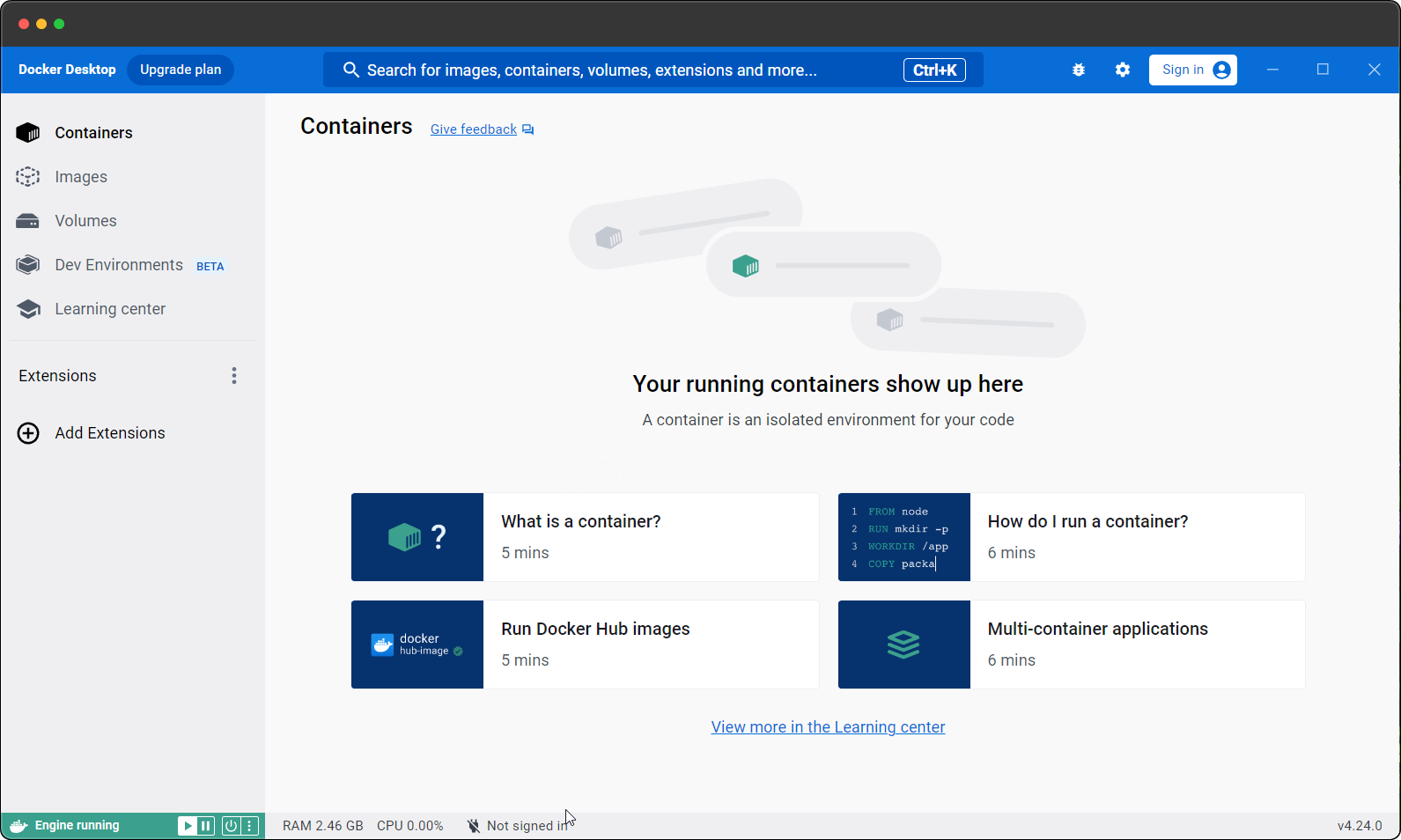
注册这个账号的目的就是可以推送你自己的镜像到docker的中央仓库(和maven的中央仓库差不多),如果后面我们需要注册一个账号的话大概就是这个样子,点击右上角的sign in浏览器自动就会跳出这个页面,如果我们需要注册我们就点击sign up:

之后会让我们输入邮箱,用户名和密码

第五步,验证是否可以使用
登录/跳过登录之后 这个时候我们看左下角显示的事engine running,意思就是docker以及启动起来了
之后我们用cmd运行docker images命令,出现下面的情况就算成功安装了

第六步,配置国内镜像源
docker的默认仓库也是在国外,所以国内有时候甚至经常pull拉不了镜像,就像github一样

所以我们需要配置国内的镜像库,但是前段时候听说docker镜像很多不能用了,但是博主还是找了一个目前可以用的镜像库,有可能以后要经常换,这个是暂时没有办法的
在docker右上角的设置里面选择docker engine,加入蓝色框框框住的文字,下面已贴出

,"registry-mirrors": ["https://docker.m.daocloud.io"]
注意有个逗号,之后右下角的 Apply & restart 就会亮起,我们点击等他重启即可,之后我们cmd 输入docker info就会出现我们刚刚配置的镜像

我们再重新拉取一下nginx的镜像:
docker pull nginx
之后发现嘎嘎快了!!

成功拉下来了!!!

至此,我们的docker环境已经在Windows 10安装好了,之后就可以开始我们的docker之旅了,对了这篇文章算是从零开始玩转 Docker:一站式入门指南,带你快速掌握镜像、容器与仓库的插叙,可以接着无缝衔接去看这一篇文章哦
