阳东城乡规划建设局网站莱芜网站建设案例
作者:来自 Elastic Josh Asres
了解在 Elasticsearch 中为你的搜索用例提取数据的所有不同方式。
对于搜索用例,高效采集和处理来自各种来源的数据的能力至关重要。无论你处理的是 SQL 数据库、CRM 还是任何自定义数据源,选择正确的数据采集工具都会对你的 Elasticsearch 体验产生重大影响。在本博客中,我们将探索 Elastic Stack 的三种搜索数据采集工具:Logstash、客户端 API 以及我们的 Elastic Native Connectors + Elastic Connector Framework。我们将深入探讨它们的优势、理想用例以及它们最擅长处理的数据类型。
Logstash,集中、转换和存储你的数据

概述
Logstash 是一个功能强大的开源数据处理管道,可采集、转换数据并将数据发送到各种输出。Logstash 是 Elastic Stack 的瑞士军刀,被广泛用于日志和事件数据处理,为数据采集提供了多功能的 ETL 工具。
主要功能和优势
Logstash 的突出功能之一是其丰富的插件生态系统,支持各种输入、过滤和输出插件。这个广泛的插件库允许在数据处理中实现显著的自定义和灵活性。用户可以使用管道配置文件定义复杂的数据转换和丰富管道,使其成为原始数据需要大量预处理的场景的理想选择。
请参阅下面的 Logstash 管道示例,该管道从文件中提取访问日志,使用过滤器丰富数据,并将其发送到 Elasticsearch。
input {file {path => "/tmp/access_log"start_position => "beginning"}
}filter {if [path] => "access" {mutate { replace => { "type" = "apache_access" } }grok {match => { "message" = "${ COMBINEDAPACHELOG}" }}}date {match => [ "timestamp", "dd/MMM/yyyy: HH: mm:ss Z" ]}
}output {elasticsearch {{cloud id => "<cloud id›" cloud_auth => "<cloud auth>"}}
}一个常见的用例是从数据库中提取数据。让我们以前面的示例为例,并对其进行修改以使用 Logstash 的 JDBC 输入插件,该插件允许你从任何具有 JDBC 接口的数据库(例如 Oracle DB)中提取数据。使用 SQL 查询,你可以定义要提取的数据。
input {jdbc {jdbc_driver_library => "mysql-connector-java-5.1.36-bin.jar"jdbc_driver_class => "com.mysql.jdbc.Driver"jdbc_connection_string => "jdbc:mysql://localhost:3306/mydb"jdbc_user => "mysql"parameters => { "favorite_artist" => "Beethoven" }schedule => "* * * * *"statement => "SELECT * from songs where artist = :favorite_artist"}
}output {elasticsearch {{cloud id => "<cloud id›" cloud_auth => "<cloud auth>"}}
}Logstash 的另一个用例是结合使用 Elasticsearch 输入和输出插件,这允许你将数据从一个 Elasticsearch 集群提取和迁移到另一个 Elasticsearch 集群。
input {elasticsearch {# Specify the host information of the source ES cluster. hosts => ["http://localhost:9200"]# Specify auth for the source ES cluster. user => "xxxxxx"password => "xxxxxx"index = "«source_index_name>"scroll = "5m"size = 1000}
}
output {elasticsearch {# Specify the host information of the destination ES cluster. hosts => ["http://destination.cluster:9200"]# Specify auth for the destination ES cluster. user => "xxxxxx"password => "xxxxxx"index => "<destination_index_name>"action => "index"scroll = "5m"size = 1000}
}最适合
Logstash 最适合在将数据索引到集群之前需要大量丰富数据或希望集中从各种来源获取数据的用例。但需要记住的一点是,Logstash 确实需要你在基础设施中的某个 VM 中托管和管理它(无论是本地还是云提供商)。如果你正在为你的用例寻找更轻量级的东西,请继续阅读以了解有关我们的语言客户端和连接器的更多信息!
Elasticsearch 客户端

Elasticsearch 客户端是 Elastic 提供的官方库,允许开发人员从他们喜欢的编程环境与 Elasticsearch 集群进行交互。这些客户端支持 Java、JavaScript、Python、Ruby、PHP 等语言,提供一致且简化的 API 来与 Elasticsearch 进行通信。
我们的客户端提供众多优势,可简化和增强你与 Elasticsearch 集群的交互。简化的 API、特定于语言的库、性能优化和全面支持使它们成为开发人员不可或缺的工具。这使开发人员能够根据你的特定需求构建强大、高效且可靠的搜索应用程序。
我们目前提供以下编程语言的语言客户端:
-
Java Client
-
Java Low Level REST Client
-
JavaScript Client
-
Ruby Client
-
Go Client
-
.NET Client
-
PHP Client
-
Perl Client
-
Python Clients
-
Rust Client
-
Eland Client
原生连接器和连接器框架
https://www.elastic.co/guide/en/enterprise-search/current/connectors-apis.html
概述
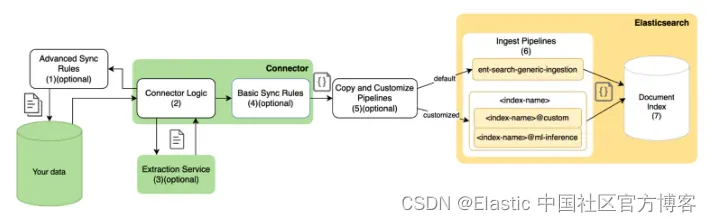
Elastic Native Connectors 是 Elasticsearch 中的内置集成,可帮助将数据从各种来源直接无缝传输到 Elasticsearch 索引中。这些连接器设计为开箱即用,只需极少的设置和配置,并针对 Elastic Stack 中的性能进行了优化。
除了我们的 Native Connectors,我们还有 Elastic Connector Framework,它使开发人员能够自定义现有的 Elastic 连接器客户端或使用我们基于 Python 的框架为不受支持的第三方数据源构建全新的连接器。
主要功能和优势
Elastic Native Connectors 最显著的优势之一是易于使用。你需要做的就是进入 Kibana 并使用我们简单的配置 UI 连接数据源(或者如果你更喜欢配置为代码,你可以使用我们的 Connector APIs)。
我们的连接器的另一个强大优势是支持各种第三方的连接器数量,例如:
- MongoDB
- 各种 SQL DBMS,例如 MySQL、PostgreSQL、MSSQL 和 OracleDB
- Sharepoint Online
- Amazon S3
- 还有更多。完整列表可在此处查看
我们的原生连接器支持完整和增量同步以及同步调度,并且能够通过同步规则过滤要导入 Elastic 的数据。另一个强大的功能是能够将我们的导入管道与原生连接器结合使用,这允许你在导入数据时对数据执行各种转换。这还包括使用推理管道,供那些想要将这些文档中的文本向量化以执行语义搜索的人使用。
最适合
Elastic Native Connectors 为数据采集提供了许多好处,包括与 Elastic Stack 的无缝集成、简化的设置、广泛的受支持数据源、优化的性能和强大的安全功能。这些优势使其成为希望简化数据采集流程和增强搜索功能的组织的绝佳选择。使用我们的连接器框架,你还可以进一步定制现有的连接器或构建新的连接器。尽管如上所述,该框架是基于 Python 的,因此如果你想使用更熟悉的语言来采集数据,我们建议你查看语言客户端。
总结
选择正确的数据采集工具取决于你的用例的具体需求以及数据所在的位置。Logstash 在需要通过集中采集进行复杂数据转换的场景中表现出色,但确实带来了管理开销,并且其配置文件也有些复杂。我们的 Elasticsearch 客户端让你可以最大程度地自由地使用你最熟悉的编程语言构建自己的采集功能。最后,Elastic Native Connectors 为第三方数据源提供了简化的集成和管理,而我们的 Connector Framework 允许与尚未支持的数据源进行自定义集成。
通过了解每种工具的优势和最佳用例,你可以做出明智的决策,确保你的数据得到有效采集、索引并准备好进行搜索,从而能够更快、更准确地洞察以解决你的用例。
有关更深入的信息,请查看 Logstash、Elastic Native Connectors + Connector Framework 和我们的官方语言客户端的官方文档。
你可以使用来自任何来源的数据构建搜索。查看此网络研讨会以了解 Elasticsearch 支持的不同连接器和来源。
准备好亲自尝试一下了吗?开始免费试用。
原文:Elasticsearch Data Ingestion - What's the Best Tool for the Job? — Elastic Search Labs