做关于灯饰的网站wordpress安装在windows上
定时器
定时器时我们日常开发中会用到的组件工具,类似于一个"闹钟",设定一个时间,等到了时间,定时器最自动的去执行某个逻辑,比如博客的定时发布,就是使用到了定时器
Java标准库里面也提供了定时器的实现
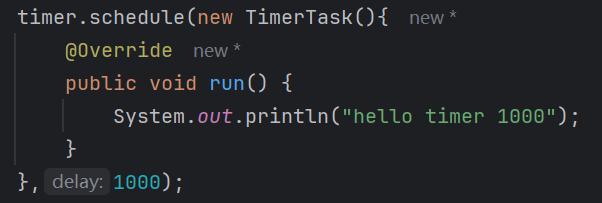
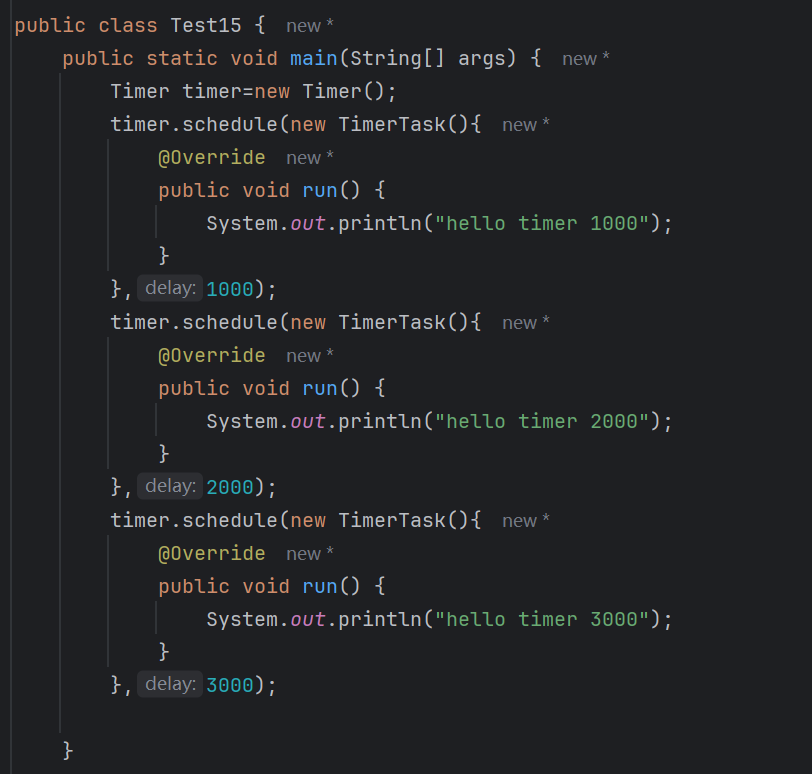
定义一个timer,添加多个任务,每个任务都带有一个时间定义任务的时候可以使用lambde表达式吗?
- 答案是不能的,lambde只能用于创建函数式接口的实例,如果非要用lambde表达式创建一个类的实例的话,可以用lambde先创建出一个函数式接口的实例,再把这个函数式接口赋值给类的变量,如下图,我们的源代码里面Timer就是一个实现了Runnable函数式接口的一个抽象类,是不可以使用lambde表达式的

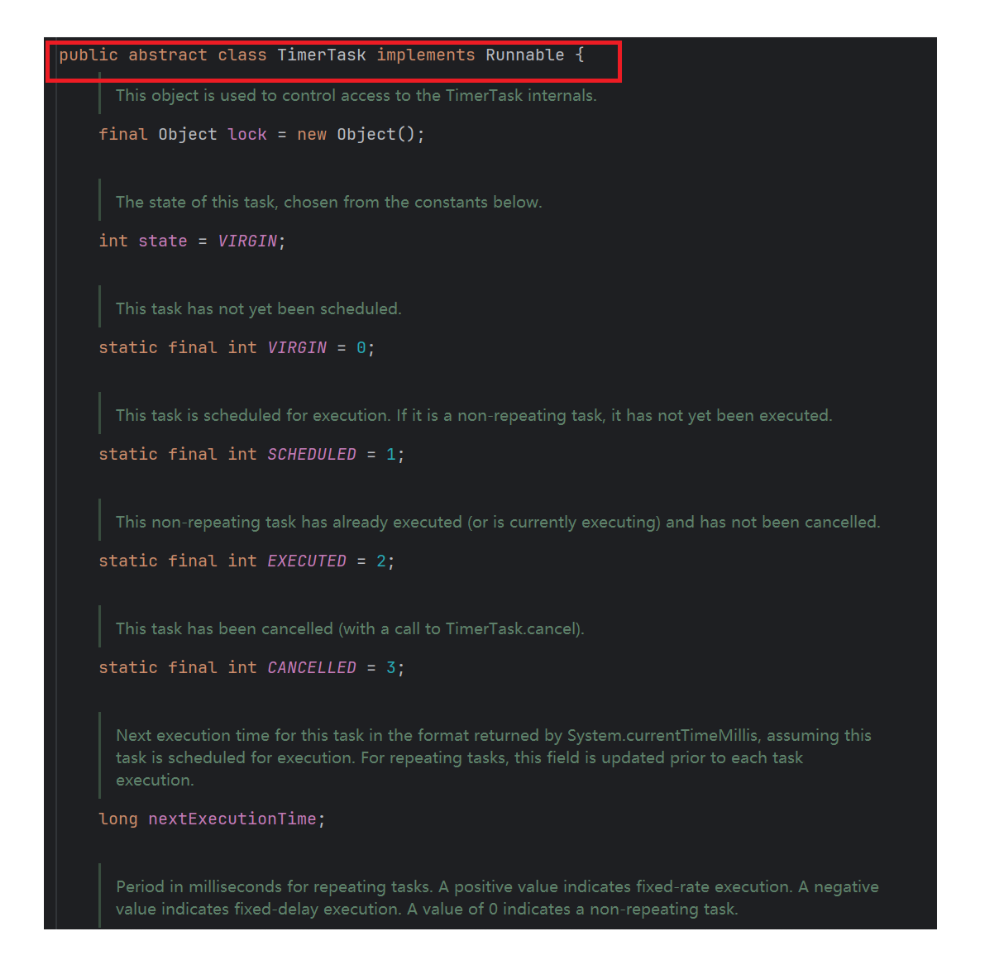
内置了前台线程
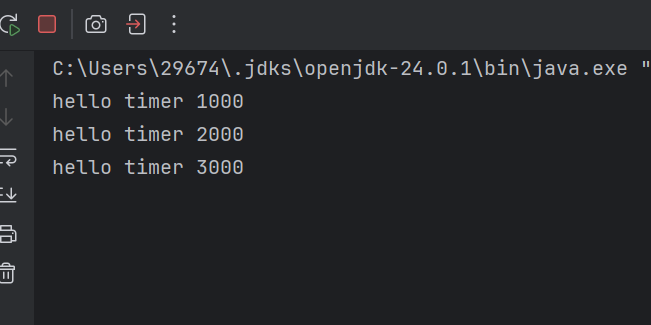
我们上图代码的执行结果如下
我们发现,控制台打印了我们的三个任务以后,并没有进程结束的提示,说明我们的进程并没有结束,原因是Timer里面内置了前台线程,它会阻止进程的结束但是我们往timer里面添加的任务都执行完了,也不会结束吗?
- 因为我们的timer也不知道你是否还会添加新任务进来,所以它不能结束,必须严阵以待,也就是不能结束,于是内置了前台线程
但是就没有办法让timer结束吗?
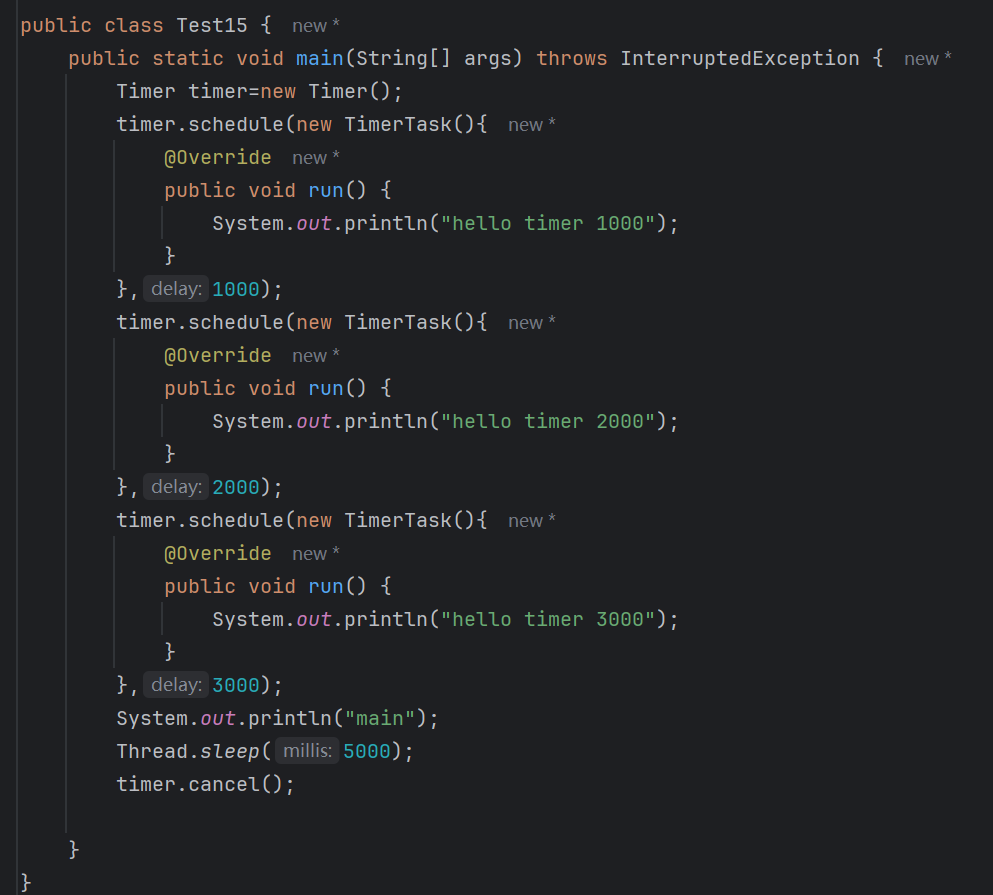
- timer里面有一个cancel方法,可以手动调用来结束进程
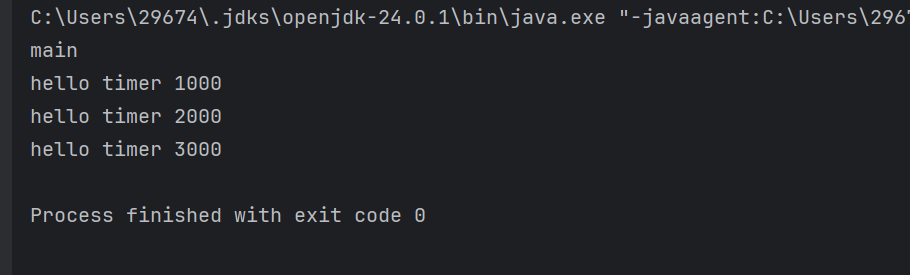
上述代码我们调用了cancel后,进程会结束(如下图)
需要主动调用cancel让线程主动结束,要不然Timer不知道是否还有其他地方要添加任务的
定时器的实现
我们先思考一下,实现一个定时器需要哪些的内容
- 首先我们需要一个线程,帮助我们掐算时间,时间一到的话,这个线程就会执行该任务
- 其次我们需要一个容器,能够保存schedule进来的任务
我们直观的来想的话,我们这个线程就要不断的遍历我们这个容器,看看任务的时间是否到了,如果到了,就执行这个任务
但是如果我们容器里面的元素很多呢?要是遍历的话,时间复杂度就是o(n)了,开销就很大了
我们此时就需要用到优先级队列了,我们的每个任务都有实现,先执行时间小的,后执行时间大的,有了优先级队列,必须是小根堆,队首元素就是执行时间最小的元素,我们每次只需要看一下队首元素是否到时间了,要是队首元素也没有到时间的话,其他的任务一定没有到时间我们现在的优先级队列有两个选择:
- PriorityQueue(线程不安全)
- PriorityBloskingQueue(线程安全)
虽然PriorityBloskingQueue是线程安全的,但是我们这里要使用 PriorityQueue,使用PriorityBloskingQueue不太好控制,容易出问题,我们这里手动给PriorityQueue加锁即可
上面是我们写的一个类,用来描述一个任务我们这个类直接实现Runnable也是可以的,我们这里是让这个类持有了Runnable
而且我们这个任务类是需要将其放到优先级队列里面的,所以要求我们这个类是可以比较的,我们这里也实现了Comparable接口,并且重写了CompareTo方法,这里的比较的规则就是时间的大小
如果是TreeSet和TreeMap的话我们要求元素是可以比较的,我们就需要实现Comparable和Comparator接口
如果是HsahSet和HashMap的话,就要求元素是可以比较相等的和可哈希的,这时候就要equals和hashCode方法了,有时候为了让hsah更加高效的话,需要重写这两个方法
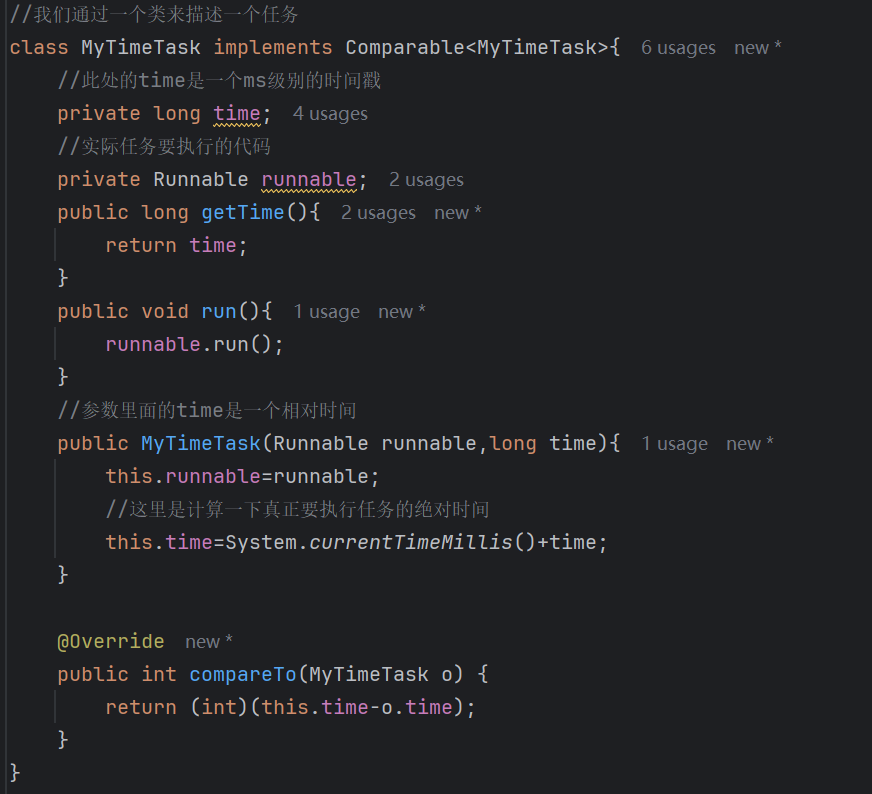
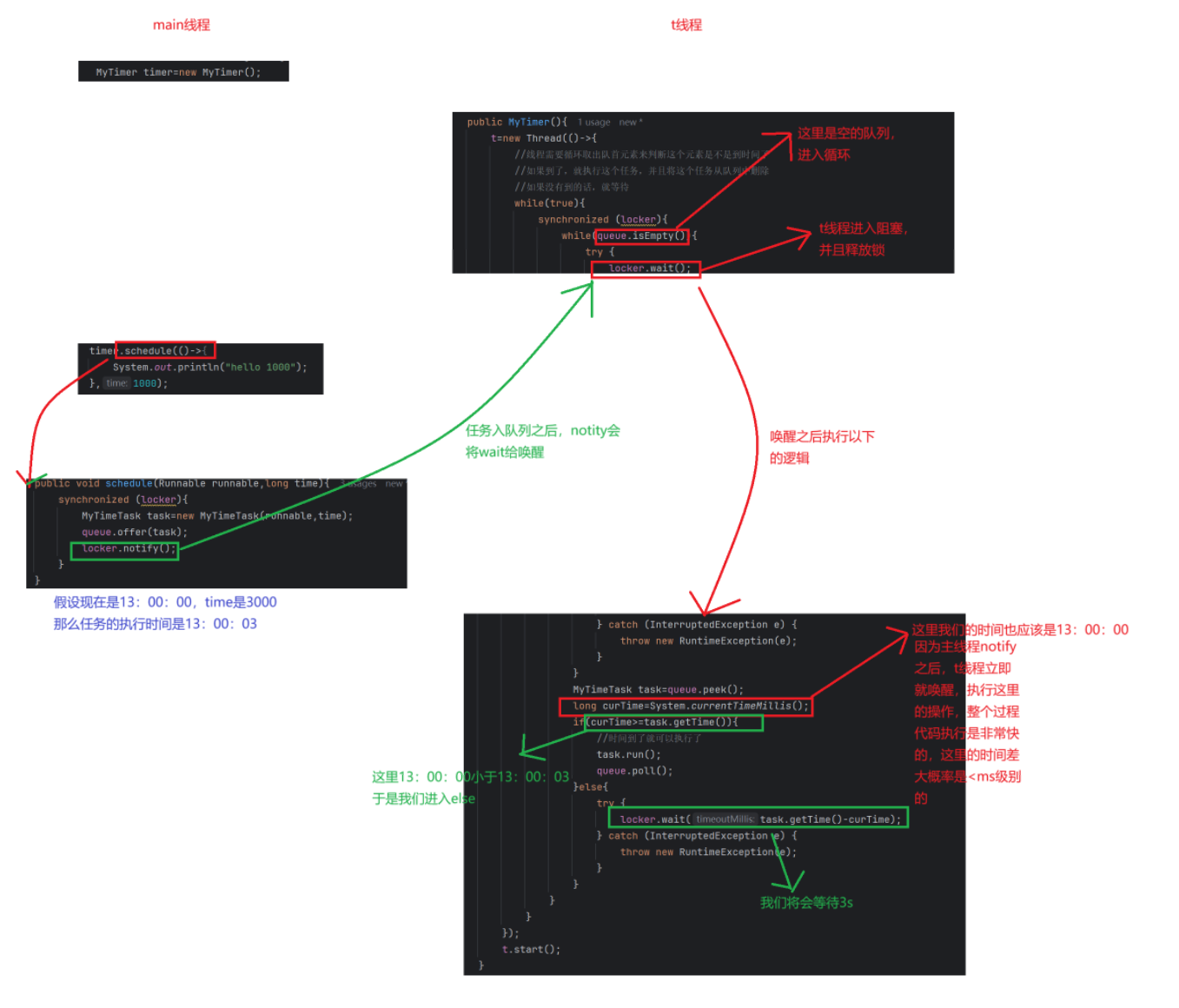
这是我们写的构造方法,在这里面我们创建了一个线程,这个线程就是我们的判断和执行任务的线程
加锁
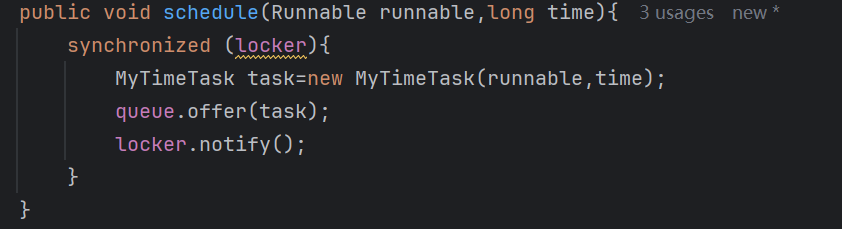
由于我们的加入任务的操作(如下图)和我们的执行并且删除任务的操作都是对同一个队列进行操作,可能会有线程安全问题
可以发现我们都给这两个方法加上锁了
当我们线程如果发现队列里面是空的,locker.wait就会释放锁,于是scedule就可以获取到锁了,获取到锁之后就可以往队列里面添加任务,添加完任务之后,notify就可以将线程唤醒
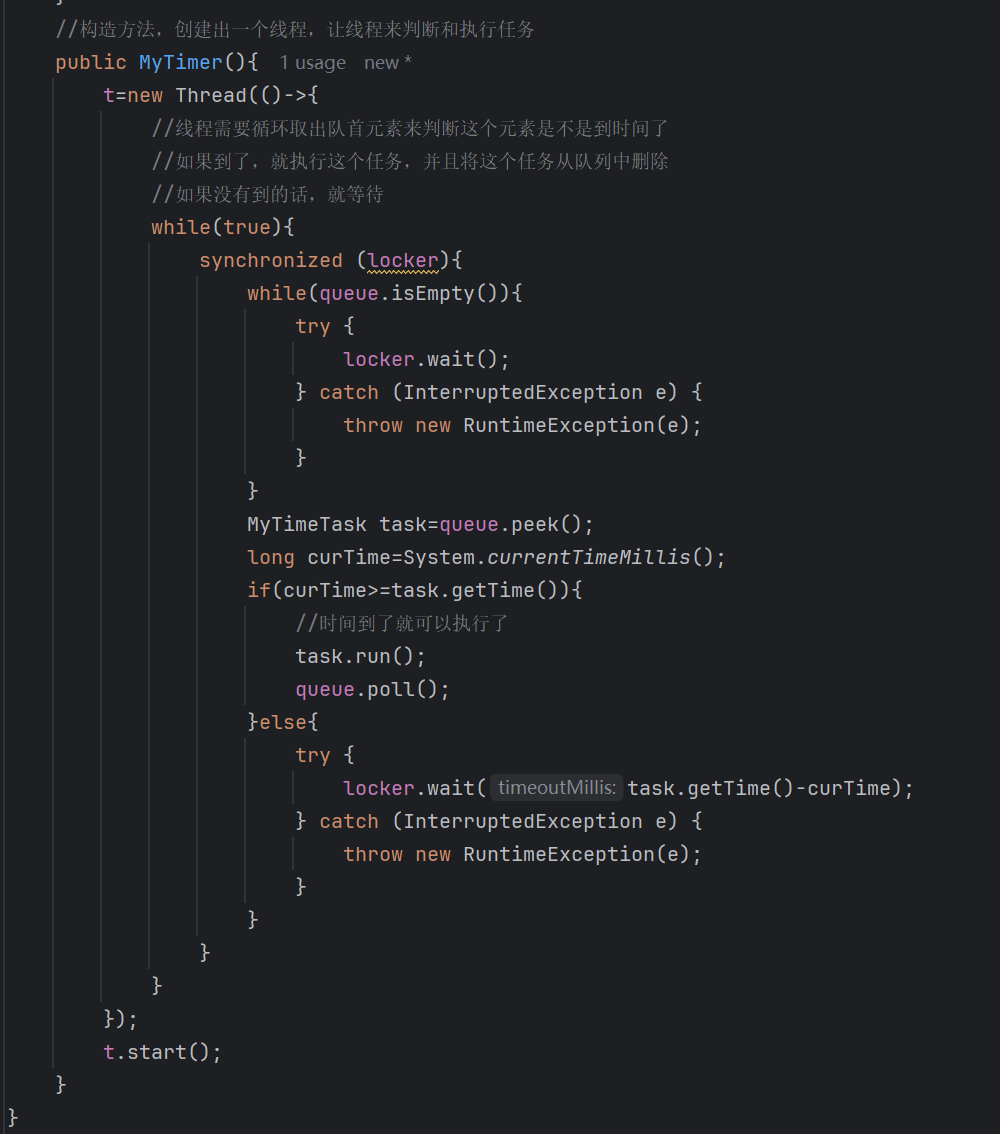
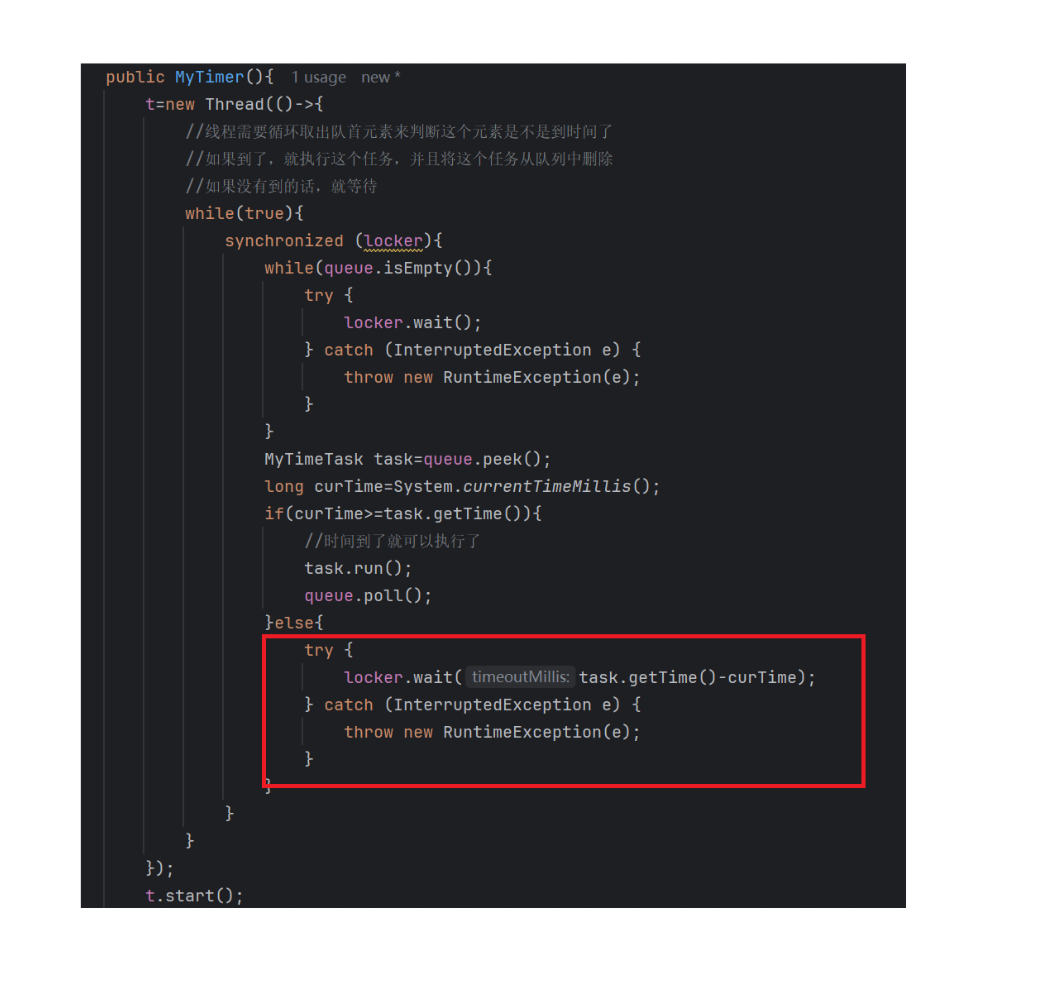
我们红框部分的地方也要用到wait,是有时间限制的wait,这里有两种情况:
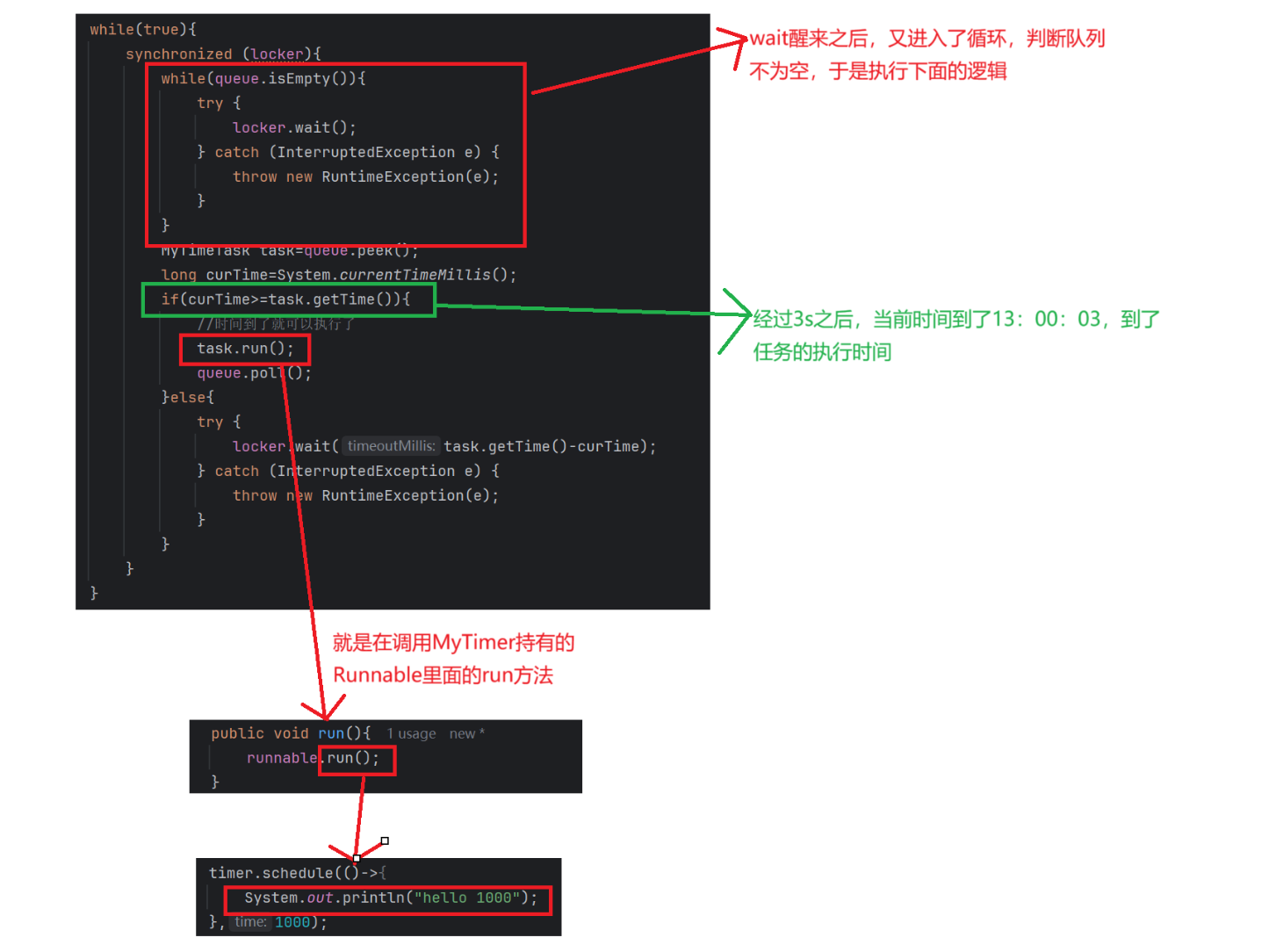
- 我们能进入else就说明还没有到首队列元素的执行时间,此时我们需要等待(任务执行时间-当前时间)这么多的时间,等到了我们wait的时间,wait就会自动唤醒,再次进入循环取出队首元素,发现到时间了,于是就执行任务,并且将任务从队列里面删除
- 我们进入else,执行wait释放锁并且阻塞的时候,此时又有一个任务通过schedule进入到了队列,schedule里面的notify就会将我们的线程唤醒,线程唤醒之后又进入循环,由于我们加入了新的任务,这个新任务的时间有可能比我们原来的队首任务的时间小,也有可能大,这时我们的队首任务就会发生变化,于是又peek一下,取队首元素,看看是否到了时间,在根据条件执行下面的逻辑
如果我们else里面什么都不加的话,只有一个coontinue,这时我的CPU只是在忙等,虽然在等,但是CPU很忙,因为此时线程的情况是进入了死循环,不如将CPU的资源让出来,给其他的线程使用,这就是我们wait的另一个作用
使用sleep可以吗?
不可以,sleep虽然也可以实现等待的结果,但是sleep没有释放锁,如果我们中间有一个schedule又加入了一个任务,这个任务的执行时间是10:20:00,比如现在是10:00:00,我们的首队列元素的执行时间是10:30:00,此时我们进入else执行到了sleep,按照我们上面wait的代码,我们这里要sleep30分钟,这个过程中,锁没有被释放,是被判断的线程持有的,这就导致我们的schedule方法获取不到锁,无法将新的任务添加到队列,等sleep到了时间被唤醒的时候,已经过了10:20:00了,这个任务就错过了
执行过程详解
执行到这里以后我们会进入到漫长的3s的等待,3s结束之后,wait就自动唤醒了