越秀网站建设优化马连洼网站建设
一、(左、右和全)连接概念
内连接: 假设A和B表进行连接,使用内连接的话,凡是A表和B表能够匹配上的记录查询出来。A和B两张表没有主付之分,两张表是平等的。

关键字:inner join on
语句:select * from a_table a inner join b_table b on a.a_id = b.b_id;
说明:组合两个表中的记录,返回关联字段相符的记录,也就是返回两个表的交集(阴影)部分。
左连接(左外连接,表示左边的这张表是主表): 假设A和B表进行连接,使用外连接的话,A,B两张表中有一张主表,一张副表,主要查询主表中数据,捎带着查询副表。当副表中数据没有和主表中的数据匹配上,副表自动模拟出NULL与之匹配。外连接主要特点: 主表中的数据无条件全部查询出来。

关键字:left join on / left outer join on
语句:select * from a_table a left join b_table b on a.a_id = b.b_id;
说明:left join 是left outer join的简写,称是左外连接,是外连接中的一种。
左(外)连接,左表(a_table)的记录将会全部表示出来,而右表(b_table)只会显示符合搜索条件的记录。右表记录不足的地方均为NULL。
右连接(右外连接,表示右边的这张表是主表)

关键字:right join on / right outer join on
语句:select * from a_table a right outer join b_table b on a.a_id = b.b_id;
说明:right join是right outer join的简写,全称是右外连接,是外连接中的一种。
与左(外)连接相反,右(外)连接,左表(a_table)只会显示符合搜索条件记录,而右表(b_table)的记录将会全部表示出来。左表记录不足的地方均为NULL。
全连接(全外连接)MySQL目前不支持此种方式,可以用其他方式替代解决。

全外连接:左表和右表都不做限制,所有记录都显示,两表不足地方用null 填充,也就是:
左外连接=左表全部记录+相关联结果 ;右外连接=右表全部记录+相关联结果
综上:
- 内连接:只返回两个表中匹配的行,即两个表中连接字段相等的行。
- 全连接:返回两个表中所有的行,无论是否有匹配的行。如果某个表中没有匹配的行,对应的结果集中该表的部分会使用NULL填充。
二、连表查询SQL实例
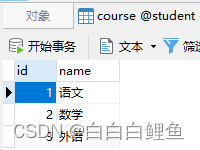
问题:根据下列的三张表,求出总分最高的学生。


-- create
CREATE TABLE course(
id INTEGER PRIMARY KEY,
name TEXT NOT NULL
);
CREATE TABLE student (
id INTEGER PRIMARY KEY,
name TEXT NOT NULL
);
CREATE TABLE score(
id INTEGER PRIMARY KEY,
course_id INTEGER NOT NULL,
student_id INTEGER NOT NULL,
score INTEGER NOT NULL
);INSERT INTO course VALUES(1, "语文"), (2, "数学"), (3, "外语");
INSERT INTO student VALUES(1, "小张"), (2, "小王"), (3, "小马");
INSERT INTO score VALUES(1, 1, 1, 80), (2, 2, 1, 90), (3, 3, 1, 70);
INSERT INTO score VALUES(4, 1, 2, 70), (5, 2, 2, 90), (6, 3, 2, 80);
INSERT INTO score VALUES(7, 1, 3, 80), (8, 2, 3, 60), (9, 3, 3, 70);SELECT *FROM course;
SELECT *FROM student;
SELECT *FROM score;当然这里面包含两种情况,到底是单科总分最高,还是所有科总分加起来最高,如果面试官没有讲清楚,还是先别急于回答,或者把这两个情况都分析一遍:
①、求所有科目总分最高的学生
SELECT s.name, t.total_score
FROM student s
RIGHT JOIN (SELECT student_id, SUM(score) AS total_score FROM score GROUP BY student_id HAVING SUM(score) = (SELECT SUM(score) FROM score GROUP BY student_id ORDER BY SUM(score) DESC LIMIT 1)) t ON s.id = t.student_id;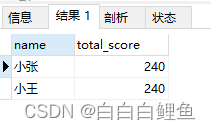
具体SQL的解释如下:
这个查询的目的是找到总成绩排名第一的学生,并返回该学生的姓名和总成绩。
-
子查询
t:首先,我们执行一个子查询来计算每个学生的总成绩。
子查询从
score表中获取每个学生的学生 ID (student_id) 和对应的成绩总和 (SUM(score) AS total_score)。使用GROUP BY student_id对成绩进行分组,以便计算每个学生的总成绩。然后,通过HAVING SUM(score) = (SELECT SUM(score) FROM score GROUP BY student_id ORDER BY SUM(score) DESC LIMIT 1)这一行筛选出总成绩最高的学生,确保只选择总成绩等于所有学生中最高总成绩的学生。 -
主查询:在主查询中,我们使用
RIGHT JOIN将学生表 (student) 和子查询t关联起来。这样,我们可以获取到总成绩最高的学生以及他们的总成绩。通过ON s.id = t.student_id来建立关联条件,确保学生 ID 匹配。 -
结果过滤:在最终结果中,我们选择了学生的姓名 (
s.name) 和对应的总成绩 (t.total_score)。
②、求单科科目总分最高的学生
SELECT s.name, c.name , s2.max_score FROM score s1
RIGHT JOIN (SELECT MAX(score) max_score, course_id FROM score GROUP BY course_id) s2
ON s1.course_id = s2.course_id AND s1.score = s2.max_score
LEFT JOIN course c ON c.id = s1.course_id
LEFT JOIN student s ON s1.student_id = s.id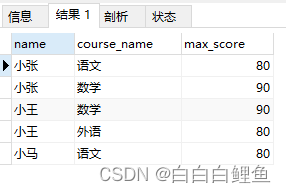
具体SQL的解释如下:
SELECT s.name, c.name AS course_name, s2.max_score: 这部分定义了要选择的列。s.name表示学生的姓名,c.name AS course_name表示课程的名称(使用别名course_name),s2.max_score表示最高分数。FROM score s1: 这表示从score表中查询数据,并为其创建别名s1。(SELECT MAX(score) max_score, course_id FROM score GROUP BY course_id) s2: 这是一个子查询,它计算每门课程的最高分,并将结果存储在s2中。它选择了每个课程的最高分数(使用别名max_score)和课程ID。

RIGHT JOIN: 这是一个右连接,将s1和s2进行连接。它基于课程ID和最高分数匹配。ON s1.course_id = s2.course_id AND s1.score = s2.max_score: 这是连接条件,用于将s1和s2进行连接,使得课程ID和最高分数相匹配。JOIN student s ON s1.student_id = s.id: 这是一个内连接,将s1和student表连接起来。它基于学生ID匹配 (可以展示出 学生的姓名)。LEFT JOIN course c ON c.id = s1.course_id: 这是一个左连接,将s1和course表连接起来。它基于课程ID匹配(可以展示出 课程的名称)。- 最后的查询结果将包含学生的姓名、课程名称和最高分。
如果将原来的 LEFT JOIN 连接操作更改为 RIGHT JOIN,则结果中将显示右表(即子查询 s2)的所有记录,而左表(即 score s1)在右表中没有匹配的记录将被包含为 NULL 值。具体来说,右连接(RIGHT JOIN)会返回右表中满足连接条件的记录,并且左表中不满足连接条件或没有匹配的记录将被包含为 NULL 值。
在这种情况下,由于 s2 是一个子查询,它计算了每门课程的最高分,并且只包含具有最高分的信息,所以使用 RIGHT JOIN 可能不会得到预期的结果。因为右表中的记录数量较少,而左表中的记录数量较多。
如果我们想要获取所有的学生姓名和对应课程的最高分,并将它们与课程名称进行匹配,那么使用 LEFT JOIN 是更常见和合适的选择。