扬州商城网站制作网站需求分析报告

本篇文章主要讲述重复消费的原因,以及如何去测试这个场景,最后也会告诉大家,目前互联网项目关于如何避免重复消费的解决方案。
Mq为什么会有重复消费的问题?
Mq 常见的缺点之一就是消息重复消费问题,产生这种问题的原因是什么呢?有以下几点:
工作流程
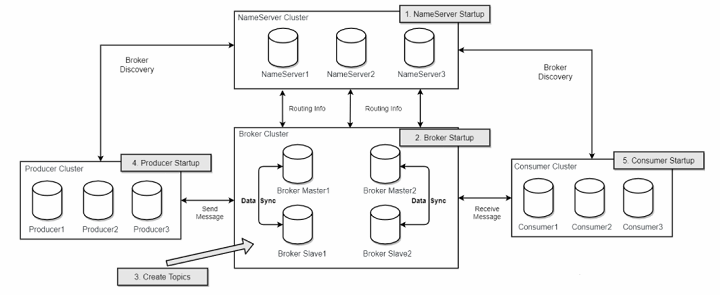
1、producer 生成数据,发送到broker集群,当遇到网络抖动超时,可能会重复发送。
为了保证数据的可靠性一般都会配置重试机制如下:
rocketmq:producer:group: sanyouProducer#发送消息超过5秒未接收到broker返回的成功消息send-message-timeout: 5000#重试最大次数retry-times-when-send-failed: 2max-message-size: 4194304name-server: 172.30.34.10:9876;172.30.35.37:9876;172.30.35.30:9876#发送消息超时时长,意思是超过5秒钟未收到broker返回的发送成功的消息,#producer会重复发送,但并不是一直发送,会根据retry-times-when-send-failed次数,#最多重试多少次
极端情况下,网络出现抖动,生产者超过设置的时间未收到broker返回的成功消息,会重新发送消息。
2、消费者宕机,未提交offset给broker
由上图可知,broker接收到producer 发送的消息后,会把消息发送给消费者,一般情况下,消费者消费完一条数据,会提交一个offset给到broker,告诉它,这条消息我消费了,但是,极端情况下,消费者消费一条消息成功,提交offset之前,宕机了或者网络抖动超时了,broker未收到offset,就认为这条消息没人消费,当消费者重启服务器或网络恢复,那么broker还会发送这条消息给消费者重新消费。
3、业务上的bug,可能会导致重复消费。
生产者producer的上游系统,突然出现了bug,导致重复调用生产者所在服务的接口,生产者收到请求后,继续发送消息给broker。
当然了,重复消费的原因有很多,以上只是常见的几种原因,那怎么去测试呢?
怎么测试重复消费场景?
假如有这么一个场景,采购员在采购系统的前端页面进行采购单下单操作,下单成功后,采购系统这边会保留一份采购单数据,然后发送一条mq给到wms 仓库系统,那么生产者就是采购系统,消费者就是wms仓库系统,wms消费到采购单的消息,落入数据库wms_purchase表中,为了简化,我只设计了三个字段。
建表ddl:
CREATE TABLE `wms_purchase` (`id` bigint(11) NOT NULL AUTO_INCREMENT COMMENT '仓库采购单id',`purchase_id` bigint(20) NOT NULL COMMENT '采购单id',`purchase_name` varchar(255) DEFAULT NULL,PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=237 DEFAULT CHARSET=utf8;
怎么测试呢?很简单,我们只要编写生产者工具,在工具里加个循环,尽量循环多次,如下:
@RestController
@RequestMapping("/mq")
public class ProducerController {// 自动注入 RocketMQTemplate模板类,用于生产消息@Autowiredprivate RocketMQTemplate mqTemplate;// 模拟生产者重复消费问题,前提是数据库没有唯一索引,并且项目未做幂等性校验@RequestMapping("/send")public String testSend(@RequestBody WmsPurchaseDto params) {try {for (int i = 0; i <100 ; i++) {mqTemplate.convertAndSend("fourbrothertopic", params);}return "success";} catch (Exception e) {e.printStackTrace();return "fail";}}
解读:
requestmapping对外暴露一个web接口,地址是localhost:8080/demo/mq/send,
post请求,参数是json格式,类似
{
"purchaseId": "256465",
"purchaseName": "测试"
}
这种形式,然后起个for循环,循环调用convertAndSend方法,发送同样的消息,最终结果如下图:
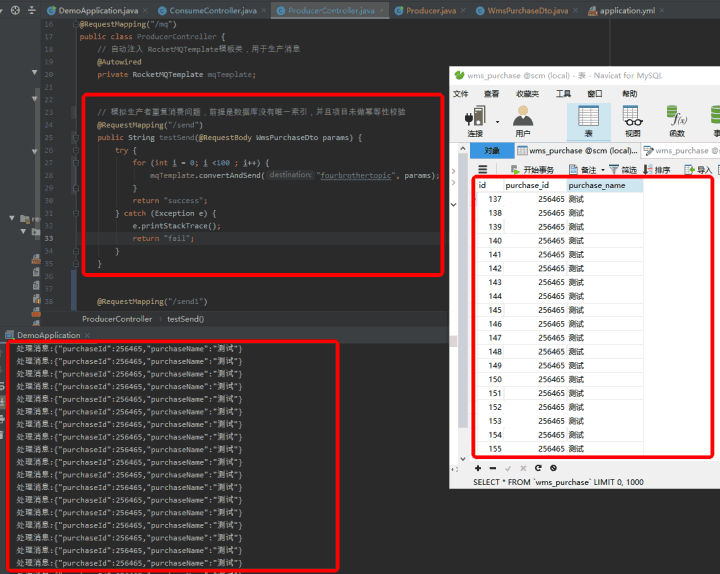
这里模拟producer重复发送的场景,前提是数据库没有对采购单id做唯一索引,并且项目未做幂等性校验。数据库里出现很多采购单id一样的数据,业务上这是不允许的。
假如说,项目出现了这么一种bug,开发那边是怎么修复的呢?
Mq如何保证幂等性?
分享几种解决方案的具体代码demo:
1、数据库unique key(表里不允许重复列出现)来保证幂等性。
很简单,我们只要在wms_purchase里,对purchaseId添加唯一索引即可,提示:在添加唯一索引之前,需清理完表里的数据。

也可以使用ddl语句:
ALTER TABLE `wms_purchase` ADD UNIQUE ( `purchaseId` ) 代码不变,调用以下接口:
localhost:8080/demo/mq/send post请求
{"purchaseId": "256465","purchaseName": "测试"
}得到以下结果:
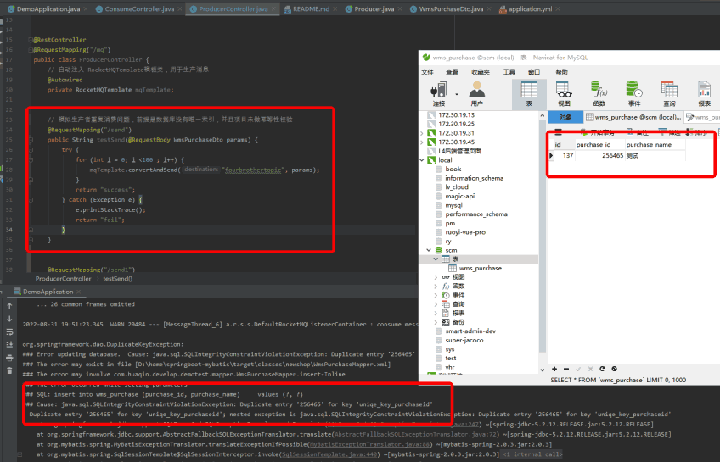
上图中,循环生产同一条采购单数据,但是右边表中只出现了一条采购单id是256465的数据,说明添加唯一索引确实保证了幂等性,但是代码里却出现大量类似Duplicate entry '256465' for key 'uniqe_key_purchaseid' 日志,是因为触发了数据设置的唯一索引,
由于触发了唯一索引,导致消费者未提交offset给broker,那么broker会认为这条消息未被消费,后续会持续不断地推送消息给消费者,也就意味着会持续不断地报错。
另外这种持续无效的请求数据库会占用数据库的连接资源,在高并发的场景下,会严重拖垮系统响应效率。
虽然保证了幂等性,但是日志里总是报错,太不讲究、也不雅观,那怎么解决呢?
2、数据库unique key+redis 来保证幂等性。
如截图:
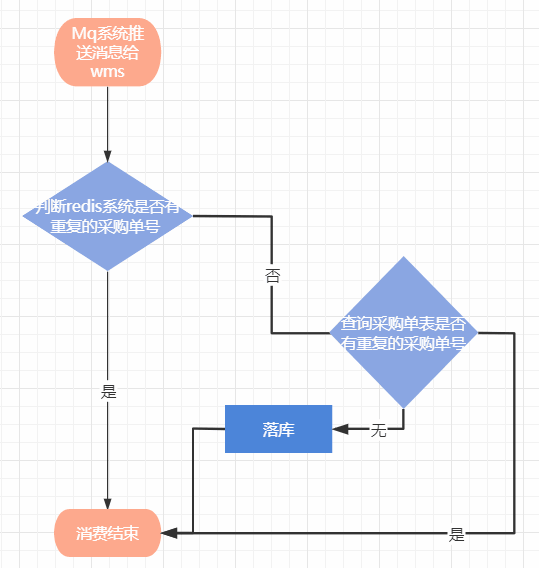
通俗的理解就是,消费者在进行数据库落库操作之前,会判断redis是有这条采购单数据,如果有就直接放过这条消息不做处理,没有这条数据,那就进行落库操作,但在落库之前还要进一步判断数据库是否有这条采购单数据,没有那就进行落库,落库成功,再把采购单的id当做key,采购单数据当做value set 进redis缓存里,设置一定的过期时间。
redis基于内存,操作数据特别快,在进行落库之前查询redis,可以避免很多无效的请求数据库,但是为啥要设置过期时间?因为redis的内存资源有限,并且很宝贵,所以我们希望设置的数据能在一段时间内定期失效,即使失效,也没关系,还有数据库的唯一索引兜底。
这样就很好的保证了幂等性,也避免了大量的日志报错。伪代码如下:
@Component
//mq的监听器,指定topic是TopicTest,消费者组consumerGroupTest
@RocketMQMessageListener(topic = "fourbrothertopic", consumerGroup = "consumerGroupTest")
@Slf4j
public class ConsumeController implements RocketMQListener {@Autowiredprivate WmsPurchaseMapper wmsPurchaseMapper;@Autowiredprivate RedisTemplate redisTemplate;@Overridepublic void onMessage(String message) {log.info("------- Consumer: {}", message);//将message消息映射成WmsPurchase实体WmsPurchase wmsPurchase = JSONObject.parseObject(message, WmsPurchase.class);//首先判断redis里面是否有这条采购单数据,通过PurchaseId查询,有数据,则直接放过不做处理if (redisTemplate.opsForValue().get(wmsPurchase.getPurchaseId().toString())==null){//然后再使用PurchaseId查询数据库,有数据,则直接放过不做处理if (null == wmsPurchaseMapper.selectByPurchaseId(wmsPurchase.getPurchaseId())){//数据库没有数据,就进行插入操作,if (wmsPurchaseMapper.insert(wmsPurchase)>0){//插入成功就把purchaseid塞进redis里,过期时间是72小时redisTemplate.opsForValue().set(wmsPurchase.getPurchaseId(),wmsPurchase.toString(),72, TimeUnit.HOURS);}}else {//能走到这个判断分支,说明缓存里的采购单数据已经失效,如果还有消息重复消费//那就再放入缓存一次,72h过期redisTemplate.opsForValue().set(wmsPurchase.getPurchaseId(),wmsPurchase.toString(),72, TimeUnit.HOURS);log.info("数据库已保留该数据");// 触发重复消费告警机制}}else {log.info("缓存已保留该数据");// 触发重复消费告警机制}}
}
思路很简单,如代码中注释。当然这种方法也有缺点,就是过于依赖redis,有些系统没有使用redis组件,那么还得维护一套redis组件,并且还得保证redis集群高可用。那项目只有mysql,能不能依靠数据库去维护保证幂等性呢?当然可以!
3、还有一种方法叫去重表+唯一索引,顾名思义就是另外维护一张表,记录已经消费的采购单数据,其实和上述方法差不多,上述方法查询缓存,取重表查询数据库取重表。
伪代码 如下:
@Component
//mq的监听器,指定topic是TopicTest,消费者组consumerGroupTest
@RocketMQMessageListener(topic = "fourbrothertopic", consumerGroup = "consumerGroupTest")
@Slf4j
public class ConsumeController implements RocketMQListener {@Autowiredprivate WmsPurchaseMapper wmsPurchaseMapper;@Autowiredprivate UniquePurchaseMapper uniquePurchaseMapper;@Autowiredprivate RedisTemplate redisTemplate;@SneakyThrows@Overridepublic void onMessage(String message) {log.info("------- Consumer: {}", message);//将message消息映射成WmsPurchase实体WmsPurchase wmsPurchase = JSONObject.parseObject(message, WmsPurchase.class);log.info("映射后实体消息"+ JSON.toJSONString(wmsPurchase));if (uniquePurchaseMapper.selectByPurchaseId(wmsPurchase.getPurchaseId().intValue()) == null){if (null == wmsPurchaseMapper.selectByPurchaseId(wmsPurchase.getPurchaseId())){//数据库没有数据,就进行插入操作,if (wmsPurchaseMapper.insert(wmsPurchase)>0){//插入成功就把purchaseid塞进unique_purchaseUniquePurchase uniquePurchase = new UniquePurchase();uniquePurchase.setPurchaseId(wmsPurchase.getPurchaseId().intValue());log.info("插入取重表消息:"+ JSON.toJSONString(uniquePurchase));uniquePurchaseMapper.insert(uniquePurchase);}}else {log.info("数据库已保留该数据");//自动触发告警机制}}else {log.info("取重表已有这条采购单数据");}}
代码已上传至gitee,感兴趣可以自行阅读。
上述方式在查询取重表时,并发不安全,极端情况下还是会触发唯一索引错误,比如说,消费者要消费大量消息(线程),执行上述代码,A线程执行完23行,挂起了,cpu把执行权给了B线程,B执行到25行并插入成功,那么这时A线程被唤起,也执行到了23行,结果触发了唯一索引错误。那怎么避免呢?
我们可以让所有线程别并发执行,串行执行,那就用到redis的分布式锁技术。
4、分布式锁+uniquekey
伪代码如下
@Component
//mq的监听器,指定topic是TopicTest,消费者组consumerGroupTest
@RocketMQMessageListener(topic = "fourbrothertopic", consumerGroup = "consumerGroupTest")
@Slf4j
public class ConsumeController implements RocketMQListener {@Autowiredprivate WmsPurchaseMapper wmsPurchaseMapper;@Autowiredprivate RedissonClient redisson;@Autowiredprivate UniquePurchaseMapper uniquePurchaseMapper;@Autowiredprivate RedisTemplate redisTemplate;@SneakyThrows@Overridepublic void onMessage(String message) {log.info("------- Consumer: {}", message);//将message消息映射成WmsPurchase实体WmsPurchase wmsPurchase = JSONObject.parseObject(message, WmsPurchase.class);
// 注入redisson
// 获取锁对象RLock lock = redisson.getLock("lockName");try {// 1. 最常见的使用方法//lock.lock();// 2. 支持过期解锁功能,10秒钟以后自动解锁, 无需调用unlock方法手动解锁//lock.lock(10, TimeUnit.SECONDS);// 3. 尝试加锁,最多等待2秒,上锁以后8秒自动解锁boolean res = lock.tryLock();if (res) { //成功//然后再使用PurchaseId查询数据库,有数据,则直接放过不做处理if (null == wmsPurchaseMapper.selectByPurchaseId(wmsPurchase.getPurchaseId())){//数据库没有数据,就进行插入操作,if (wmsPurchaseMapper.insert(wmsPurchase)>0){//插入成功就把purchaseid塞进redis里,过期时间是72小时redisTemplate.opsForValue().set(wmsPurchase.getPurchaseId().toString(),wmsPurchase.toString(),1, TimeUnit.HOURS);}}else {redisTemplate.opsForValue().set(wmsPurchase.getPurchaseId().toString(),wmsPurchase.toString(),1, TimeUnit.HOURS);log.info("数据库已保留该数据");//自动触发告警机制}}} catch (Exception e) {e.printStackTrace();} finally {//释放锁RLock lockName = redisson.getLock("lockName");if (lockName.isLocked()) {if (lockName.isHeldByCurrentThread()) {lockName.unlock();}}}
}
这种也是比较常见的一种,缺点也很明显,在高并发,大请求量的场景下,所有线程串行执行,处理效率势必会降低。当然了,技术没有好坏,只有合不合适。如果你的项目并发量一般,可以尝试使用上述方法。
具体代码demo已上传至gitee平台,地址如下:
https://gitee.com/lv1792017548/rocketmq-demo.git
总结
本文主要分享了如何测试mq消息队列重复性消费,以及避免重复消费常见的解决方案。
最后感谢每一个认真阅读我文章的人,礼尚往来总是要有的,虽然不是什么很值钱的东西,如果你用得到的话可以直接拿走:

这些资料,对于【软件测试】的朋友来说应该是最全面最完整的备战仓库,这个仓库也陪伴上万个测试工程师们走过最艰难的路程,希望也能帮助到你!