嘉兴 企业网站 哪家比较好的设计网站推荐

直接寻址很少用于数组处理,因为用常数偏移量来寻址多个数组元素时,直接寻址并不实用。取而代之的是使用寄存器作为指针(称为间接寻址(indirect addressing) ) 并控制该寄存器的值。如果一个操作数使用的是间接寻址, 就称之为间接操作数(indie ct operand) 。
间接操作数
保护模式下任何一个32位通用寄存器(EAX、EBX、ECX、EDX、ESI、EDI、EBP及ESP) 用中括号括起来就成为间接操作数。寄存器中包含的是数据的地址
.386
.model flat,stdcall
option casemap:none.data
byteVal BYTE 10hExitProcess PROTO,dwExitCode:DWORD .code
main PROC mov esi, OFFSET byteVal mov al, [esi] ;AL=10h,[esi]表示esi地址中的数据INVOKE ExitProcess,0
main ENDP
END main
如果目的操作数使用间接寻址,则新值将存入由寄存器指向的内存位置。
.386
.model flat,stdcall
option casemap:none.data
byteVal BYTE 10hExitProcess PROTO,dwExitCode:DWORD .code
main PROC mov bl,88hmov esi , OFFSET byteValmov [esi],bl ;把bl中的值存入esi表示的地址中mov al,[esi] ;al=88hINVOKE ExitProcess,0
main ENDP
END main
PTR与间接操作数一起使用
PTR与间接操作数一起使用一个操作数的大小可能无法从指令的上下文直接看出来。
下面的指令会导致汇编器产生“operand must have size”(操作数必须有大小) 的报错消息:
inc [esi]
![]()
汇编器不知道ESI指向的是字节、字、双字, 或其他数据大小。
PTR操作符则可以确定操作数的大小,如下例所示:
.386
.model flat,stdcall
option casemap:none.data val BYTE 12h ExitProcess PROTO,dwExitCode:DWORD .code
main PROC mov esi,OFFSET valinc BYTE PTR [esi] ;指明BYTE大小mov eax,[esi] ;EAX = 00000013INVOKE ExitProcess,0
main ENDP
END main
数组
间接操作数是步进遍历数组的理想工具。
.386
.model flat,stdcall
option casemap:none.data arrayB BYTE 10h, 20h, 30h
arrayW WORD 1000h, 2000h, 3000hExitProcess PROTO,dwExitCode:DWORD .code
main PROC mov esi, OFFSET arrayB mov al, [esi] ;al=10hinc esimov al, [esi] ;al=20hinc esimov al, [esi] ;al=30hmov esi, OFFSET arrayW mov ax, [esi] ;ax=1000hadd esi, 2mov ax, [esi] ;ax=2000hadd esi, 2mov ax, [esi] ;ax=3000hINVOKE ExitProcess,0
main ENDP
END main
变址操作数
变址操作数(indexed operand) 是指在寄存器上加上常量, 从而产生一个有效地址。任何32位通用寄存器都可用作变址寄存器。MASM允许使用以下两种基本格式(括号是符号表示的一部分):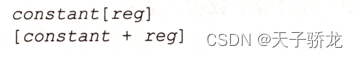
变址操作数能以两种不同格式之一出现,即或者是变量名与寄存器相结合,或者是整数常量与寄存器相结合。在前一种格式中,变量名由汇编器转换为常量,表示变量的偏移量。下面的例子显示了两种表示形式:
变址操作数非常适合用于数组处理。在访问第一个数组元素之前,变址寄存器应初始化为0:
.386
.model flat,stdcall
option casemap:none.data
arrayW WORD 1000h, 2000h, 3000hExitProcess PROTO,dwExitCode:DWORD .code
main PROC mov esi, OFFSET arrayW mov ax, [esi] ;ax=1000hmov ax, [esi+2] ;ax=2000hmov ax, [esi+4] ;ax=3000hmov ax, [4+esi] ;ax=3000hINVOKE ExitProcess,0
main ENDP
END main

下标法
.386
.model flat,stdcall
option casemap:none.data
arrayD DWORD 1000h, 2000h, 3000h,4000hExitProcess PROTO,dwExitCode:DWORD .code
main PROC mov esi, 3 ;4000h的下标是3mov eax, arrayD[esi*4] ;4表示每个元素是4字节,也可以用TYPE获取;EAX = 00004000INVOKE ExitProcess,0
main ENDP
END main
