网站建设l临沂做网站发广告
目录
一.部署单体项目
1.远程数据库
1.1远程连接数据库
1.2 新建数据库运行sql文件
2.部署项目到服务器中
3.启动服务器运行
二.部署前后端分离项目
1.远程数据库和部署到服务器
2.利用node环境启动前端项目
3.解决主机无法解析服务器localhost问题
方法一
编辑
方法二
一.部署单体项目
1.远程数据库
先远程连接我们的数据库,这里使用navicat将我们的sql文件导入运行在我们的虚拟机的数据库中
1.1远程连接数据库

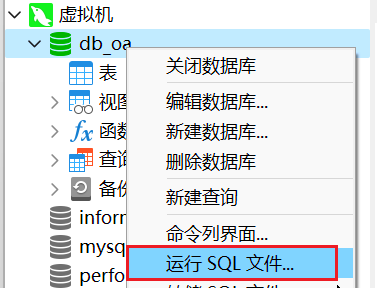
1.2 新建数据库运行sql文件

注:创建数据库时一定要确认是否与打包好的项目配置数据库名称是否相同
运行sql文件
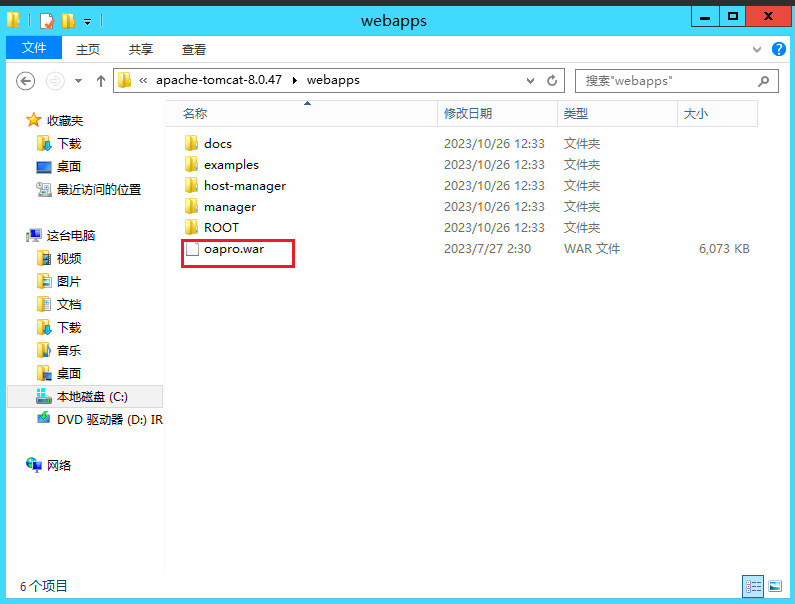
2.部署项目到服务器中
以Tomcat为例,将提前准备好的项目包放到Tomcat目录下的webapps中
3.启动服务器运行
在虚拟机中找到tomcat服务器的bin目录下的startup.bat,双击运行后,回到我们的主机在浏览器中输入ip地址+访问路径即可访问


小结:在项目中可以提前将所有的配置信息放在同一个以properties结尾的文件中,在tomcat进行部署项目时会将我们打包好的项目进行解析,并以文件夹的形式存在与当前目录,当出现配置信息不同时,我们可以找到我们的配置文件进行修改
二.部署前后端分离项目
1.远程数据库和部署到服务器
参考上面部署单体项目
2.利用node环境启动前端项目
利用node.js在服务器中启动前端项目,然后通过ip地址在虚拟机上进行访问
3.解决主机无法解析服务器localhost问题
方法一
我们可以利用反向代理服务器进行部署,使主机访问反向代理服务器
这里我们使用nginx,将里面的conf文件夹中的nginx.conf文件进行修改,将服务器本机的8081端口号给反向服务器进行代理,使我们的主机能够访问到

当设置好后启动nginx
启动:start nginx
停止:nginx.exe -s stop 或者 nginx.exe -s quit
重启:nginx.exe -s reload
在主机使用80端口进行访问
![]()
方法二
将前端项目中的index.js中访问限制进行修改,将localhost修改成0.0.0.0 就可以在我们的主机上进行访问了
