巩义seo巩义关键词优化公司电话
java 纯代码导出pdf合并单元格
接上篇博客 java导出pdf(纯代码实现) 后有一部分猿友叫我提供一下源码,实际上我的源码已经贴在帖子上了,都是同样的步骤,只是加多一点设置就可以了。今天我再次上传一下相对情况比较完整导出PDF的场景,包含列表,合并单元格,设置边框等,具体请先看效果图:
注:次效果图仅供参考,内容均为测试数据不具有任何意义。
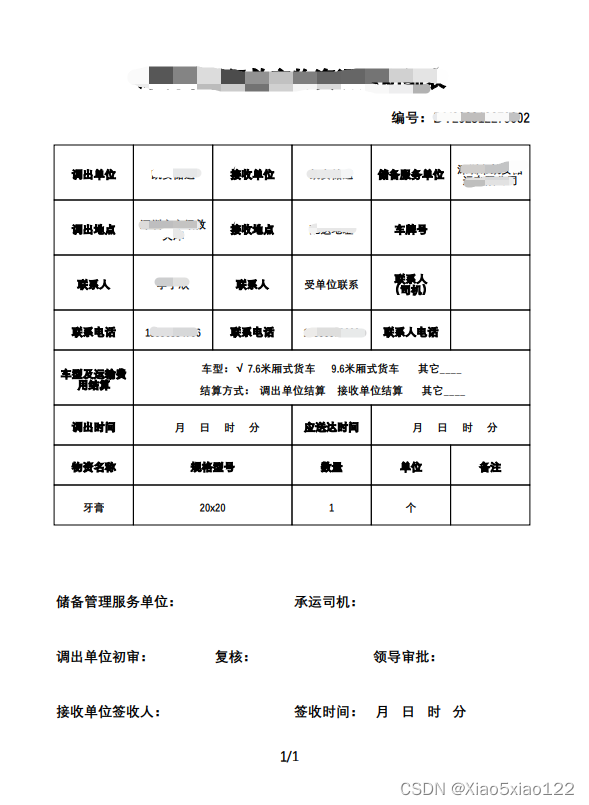
废话不多说,直接上源码:
@SneakyThrows@PostMapping("/download")@ApiOperation(value = "模板下载")public void download(@RequestBody TemplateDownloadDTO downloadDTO, HttpServletRequest request, HttpServletResponse response){//该导出仅针对一条数据故要传id确定数据Assert.notNull(downloadDTO.getId(),"id必传");request.getSession();String fileName = "文件名称";PdfUtil.setResponseContentType(response,fileName);stockOutService.download(downloadDTO,response);}
以下为导出PDF头部设置,具体在另外一个帖子中有
public static void setResponseContentType(HttpServletResponse response, String fileName) throws UnsupportedEncodingException {response.setContentType("application/pdf");response.setCharacterEncoding("utf-8");response.setHeader("Content-Disposition", "attachment;filename=" + URLEncoder.encode(fileName, "utf-8") + ".pdf");response.setHeader("Access-Control-Expose-Headers", "Content-Disposition");}
以下是逻辑部分
/*** 调运明细模板下载** @param downloadDTO 入参* @param response 返回*/@Overridepublic void download(TemplateDownloadDTO downloadDTO, HttpServletResponse response) { //你自己的查询数据的逻辑部分,我这里做了删减不展示List<StockOutDtlVO> vos = BeanUtils.copyListPropertiesByClass(list, StockOutDtlVO.class);vo.setDtls(vos);//定义全局字体静态变量Font titlefont;Font headfont = null;Font headfont1 = null;Font keyfont = null;Font textfont = null;Font textfont1 = null;Font content = null;Font space = null;Font space1 = null;Font space2 = null;Font space3 = null;//最大宽度try {BaseFont font = BaseFont.createFont("STSong-Light", "UniGB-UCS2-H", BaseFont.NOT_EMBEDDED);titlefont = new Font(font, 16, Font.BOLD);//四号headfont = new Font(font, 14, Font.BOLD);headfont1 = new Font(font, 14, Font.NORMAL);//三号content = new Font(font, 16, Font.NORMAL);//小四textfont = new Font(font, 11, Font.BOLD);textfont1 = new Font(font, 11, Font.NORMAL);space = new Font(font, 2, Font.NORMAL);space1 = new Font(font, 10, Font.NORMAL);space2 = new Font(font, 30, Font.NORMAL);space3 = new Font(font, 20, Font.NORMAL);} catch (Exception e) {e.printStackTrace();}BaseFont bf;Font font = null;try {//创建字体bf = BaseFont.createFont("STSong-Light", "UniGB-UCS2-H", BaseFont.NOT_EMBEDDED);font = new Font(bf, 22, Font.BOLD, BaseColor.BLACK);} catch (Exception e) {e.printStackTrace();}Document document = new Document(new Rectangle(PageSize.A4));//设置PDF工作区上下左右和纸张的边距document.setMargins(60, 60, 72, 72);try {PdfWriter writer = PdfWriter.getInstance(document, response.getOutputStream());//页码,具体详见另外一篇帖子writer.setPageEvent(new PdfPageUtil());document.open();Paragraph paragraph = new Paragraph("深圳市市级救灾物资调运明细表", font);paragraph.setAlignment(Element.ALIGN_CENTER);document.add(paragraph);document.add(new Paragraph("\n", space1));Paragraph paragraph1 = new Paragraph(CharSequenceUtil.format("编号:{}", vo.getDjbh()), headfont1);paragraph1.setAlignment(Element.ALIGN_RIGHT);document.add(paragraph1);document.add(new Paragraph("\n", space));float[] widths = {25f, 25f, 25f, 25f, 25f, 25f};PdfPTable table = new PdfPTable(widths);table.setSpacingBefore(20f);table.setWidthPercentage(100.0f);table.setHeaderRows(Element.ALIGN_CENTER);table.getDefaultCell().setHorizontalAlignment(Element.ALIGN_CENTER);PdfPCell cell = null;//第一行cell = new PdfPCell(new Paragraph("调出单位", textfont));cell.setVerticalAlignment(Element.ALIGN_MIDDLE);cell.setHorizontalAlignment(Element.ALIGN_CENTER);cell.setFixedHeight(55);table.addCell(cell);cell = new PdfPCell(new Paragraph(vo.getDcdwmc(), textfont1));cell.setVerticalAlignment(Element.ALIGN_MIDDLE);cell.setHorizontalAlignment(Element.ALIGN_CENTER);table.addCell(cell);cell = new PdfPCell(new Paragraph("接收单位", textfont));cell.setVerticalAlignment(Element.ALIGN_MIDDLE);cell.setHorizontalAlignment(Element.ALIGN_CENTER);table.addCell(cell);cell = new PdfPCell(new Paragraph(vo.getJsdwmc(), textfont1));cell.setVerticalAlignment(Element.ALIGN_MIDDLE);cell.setHorizontalAlignment(Element.ALIGN_CENTER);table.addCell(cell);cell = new PdfPCell(new Paragraph("储备服务单位", textfont));cell.setVerticalAlignment(Element.ALIGN_MIDDLE);cell.setHorizontalAlignment(Element.ALIGN_CENTER);table.addCell(cell);cell = new PdfPCell(new Paragraph("XXXX", textfont1));cell.setVerticalAlignment(Element.ALIGN_MIDDLE);cell.setHorizontalAlignment(Element.ALIGN_CENTER);table.addCell(cell);cell = new PdfPCell(new Paragraph("调出地点", textfont));cell.setVerticalAlignment(Element.ALIGN_MIDDLE);cell.setHorizontalAlignment(Element.ALIGN_CENTER);cell.setFixedHeight(55);table.addCell(cell);cell = new PdfPCell(new Paragraph(vo.getDckdmc(), textfont1));cell.setVerticalAlignment(Element.ALIGN_MIDDLE);cell.setHorizontalAlignment(Element.ALIGN_CENTER);table.addCell(cell);cell = new PdfPCell(new Paragraph("接收地点", textfont));cell.setVerticalAlignment(Element.ALIGN_MIDDLE);cell.setHorizontalAlignment(Element.ALIGN_CENTER);table.addCell(cell);cell = new PdfPCell(new Paragraph(vo.getPsdz(), textfont1));cell.setVerticalAlignment(Element.ALIGN_MIDDLE);cell.setHorizontalAlignment(Element.ALIGN_CENTER);table.addCell(cell);cell = new PdfPCell(new Paragraph("车牌号", textfont));cell.setVerticalAlignment(Element.ALIGN_MIDDLE);cell.setHorizontalAlignment(Element.ALIGN_CENTER);table.addCell(cell);cell = new PdfPCell(new Paragraph(null, textfont));cell.setVerticalAlignment(Element.ALIGN_MIDDLE);cell.setHorizontalAlignment(Element.ALIGN_CENTER);table.addCell(cell);cell = new PdfPCell(new Paragraph("联系人", textfont));cell.setVerticalAlignment(Element.ALIGN_MIDDLE);cell.setHorizontalAlignment(Element.ALIGN_CENTER);cell.setFixedHeight(55);table.addCell(cell);cell = new PdfPCell(new Paragraph("联系人", textfont1));cell.setVerticalAlignment(Element.ALIGN_MIDDLE);cell.setHorizontalAlignment(Element.ALIGN_CENTER);table.addCell(cell);cell = new PdfPCell(new Paragraph("联系人", textfont));cell.setVerticalAlignment(Element.ALIGN_MIDDLE);cell.setHorizontalAlignment(Element.ALIGN_CENTER);table.addCell(cell);cell = new PdfPCell(new Paragraph(vo.getJsdwlxr(), textfont1));cell.setVerticalAlignment(Element.ALIGN_MIDDLE);cell.setHorizontalAlignment(Element.ALIGN_CENTER);table.addCell(cell);cell = new PdfPCell(new Paragraph("联系人\n(司机)", textfont));cell.setVerticalAlignment(Element.ALIGN_MIDDLE);cell.setHorizontalAlignment(Element.ALIGN_CENTER);table.addCell(cell);cell = new PdfPCell(new Paragraph(null, textfont));cell.setVerticalAlignment(Element.ALIGN_MIDDLE);cell.setHorizontalAlignment(Element.ALIGN_CENTER);table.addCell(cell);cell = new PdfPCell(new Paragraph("联系电话", textfont));cell.setVerticalAlignment(Element.ALIGN_MIDDLE);cell.setHorizontalAlignment(Element.ALIGN_CENTER);cell.setFixedHeight(40);table.addCell(cell);cell = new PdfPCell(new Paragraph("1300000000", textfont1));cell.setVerticalAlignment(Element.ALIGN_MIDDLE);cell.setHorizontalAlignment(Element.ALIGN_CENTER);table.addCell(cell);cell = new PdfPCell(new Paragraph("联系电话", textfont));cell.setVerticalAlignment(Element.ALIGN_MIDDLE);cell.setHorizontalAlignment(Element.ALIGN_CENTER);table.addCell(cell);cell = new PdfPCell(new Paragraph(vo.getJsdwlxrdh(), textfont1));cell.setVerticalAlignment(Element.ALIGN_MIDDLE);cell.setHorizontalAlignment(Element.ALIGN_CENTER);table.addCell(cell);cell = new PdfPCell(new Paragraph("联系人电话", textfont));cell.setVerticalAlignment(Element.ALIGN_MIDDLE);cell.setHorizontalAlignment(Element.ALIGN_CENTER);table.addCell(cell);cell = new PdfPCell(new Paragraph(null, textfont));cell.setVerticalAlignment(Element.ALIGN_MIDDLE);cell.setHorizontalAlignment(Element.ALIGN_CENTER);table.addCell(cell);cell = new PdfPCell(new Paragraph("车型及运输费用结算", textfont));cell.setVerticalAlignment(Element.ALIGN_MIDDLE);cell.setHorizontalAlignment(Element.ALIGN_CENTER);cell.setFixedHeight(55);table.addCell(cell);String concent = CharSequenceUtil.format("车型:{} \n\n 结算方式:{}", getCx(vo), getJsfs(vo));cell = new PdfPCell(new Paragraph(concent, textfont1));cell.setVerticalAlignment(Element.ALIGN_MIDDLE);cell.setHorizontalAlignment(Element.ALIGN_CENTER);//合并单元格cell.setColspan(5);cell.setRowspan(1);table.addCell(cell);cell = new PdfPCell(new Paragraph("调出时间", textfont));cell.setVerticalAlignment(Element.ALIGN_MIDDLE);cell.setHorizontalAlignment(Element.ALIGN_CENTER);cell.setFixedHeight(40);table.addCell(cell);cell = new PdfPCell(new Paragraph(" 月 日 时 分", textfont1));cell.setVerticalAlignment(Element.ALIGN_MIDDLE);cell.setHorizontalAlignment(Element.ALIGN_CENTER);cell.setColspan(2);cell.setRowspan(1);table.addCell(cell);cell = new PdfPCell(new Paragraph("应送达时间", textfont));cell.setVerticalAlignment(Element.ALIGN_MIDDLE);cell.setHorizontalAlignment(Element.ALIGN_CENTER);table.addCell(cell);cell = new PdfPCell(new Paragraph(" 月 日 时 分", textfont1));cell.setVerticalAlignment(Element.ALIGN_MIDDLE);cell.setHorizontalAlignment(Element.ALIGN_CENTER);cell.setColspan(2);cell.setRowspan(1);table.addCell(cell);cell = new PdfPCell(new Paragraph("物资名称", textfont));cell.setVerticalAlignment(Element.ALIGN_MIDDLE);cell.setHorizontalAlignment(Element.ALIGN_CENTER);cell.setFixedHeight(40);table.addCell(cell);cell = new PdfPCell(new Paragraph("规格型号", textfont));cell.setVerticalAlignment(Element.ALIGN_MIDDLE);cell.setHorizontalAlignment(Element.ALIGN_CENTER);//后面2个单元格合并cell.setColspan(2);//合并为1个cell.setRowspan(1);table.addCell(cell);cell = new PdfPCell(new Paragraph("数量", textfont));cell.setVerticalAlignment(Element.ALIGN_MIDDLE);cell.setHorizontalAlignment(Element.ALIGN_CENTER);table.addCell(cell);cell = new PdfPCell(new Paragraph("单位", textfont));cell.setVerticalAlignment(Element.ALIGN_MIDDLE);cell.setHorizontalAlignment(Element.ALIGN_CENTER);table.addCell(cell);cell = new PdfPCell(new Paragraph("备注", textfont));cell.setVerticalAlignment(Element.ALIGN_MIDDLE);cell.setHorizontalAlignment(Element.ALIGN_CENTER);table.addCell(cell);//以下为列表数据输出List<StockOutDtlVO> dtl = vo.getDtls();if (dtl.size() > 0) {for (StockOutDtlVO stock : dtl) {PdfPCell cell1 = new PdfPCell(new Paragraph(stock.getWzmc(), textfont1));PdfPCell cell2 = new PdfPCell(new Paragraph(stock.getGgxh(), textfont1));PdfPCell cell3 = new PdfPCell(new Paragraph(stock.getSl().toString(), textfont1));PdfPCell cell4 = new PdfPCell(new Paragraph(stock.getDw(), textfont1));PdfPCell cell5 = new PdfPCell(new Paragraph(stock.getBz(), textfont1));cell1.setHorizontalAlignment(Element.ALIGN_CENTER);cell1.setVerticalAlignment(Element.ALIGN_MIDDLE);cell1.setFixedHeight(40);cell2.setHorizontalAlignment(Element.ALIGN_CENTER);cell2.setVerticalAlignment(Element.ALIGN_MIDDLE);cell2.setColspan(2);cell2.setRowspan(1);
// cell2.setFixedHeight(20);cell3.setHorizontalAlignment(Element.ALIGN_CENTER);cell3.setVerticalAlignment(Element.ALIGN_MIDDLE);
// cell3.setFixedHeight(20);cell4.setHorizontalAlignment(Element.ALIGN_CENTER);cell4.setVerticalAlignment(Element.ALIGN_MIDDLE);
// cell4.setFixedHeight(20);cell5.setHorizontalAlignment(Element.ALIGN_CENTER);cell5.setVerticalAlignment(Element.ALIGN_MIDDLE);
// cell5.setFixedHeight(20);table.addCell(cell1);table.addCell(cell2);table.addCell(cell3);table.addCell(cell4);table.addCell(cell5);}}document.add(table);document.add(new Paragraph("\n", space2));float[] widthes = {25f, 25f};table = new PdfPTable(widthes);table.setSpacingBefore(20f);table.setWidthPercentage(100.0f);PdfPCell cell1 = new PdfPCell(new Paragraph("储备管理服务单位:", headfont1));cell1.setVerticalAlignment(Element.ALIGN_LEFT);cell1.setHorizontalAlignment(Element.ALIGN_MIDDLE);cell1.setFixedHeight(35);//加上该配置不显示单元格边框cell1.setBorder(0);PdfPCell cell2 = new PdfPCell(new Paragraph("承运司机:", headfont1));cell2.setVerticalAlignment(Element.ALIGN_LEFT);cell2.setHorizontalAlignment(Element.ALIGN_MIDDLE);cell2.setBorder(0);table.addCell(cell1);table.addCell(cell2);document.add(table);float[] widthe2 = {25f, 25f, 25f};table = new PdfPTable(widthe2);table.setSpacingBefore(20f);table.setWidthPercentage(100.0f);PdfPCell cell3 = new PdfPCell(new Paragraph("调出单位初审:", headfont1));cell3.setVerticalAlignment(Element.ALIGN_LEFT);cell3.setHorizontalAlignment(Element.ALIGN_MIDDLE);cell3.setFixedHeight(35);cell3.setBorder(0);PdfPCell cell4 = new PdfPCell(new Paragraph("复核:", headfont1));cell4.setVerticalAlignment(Element.ALIGN_LEFT);cell4.setHorizontalAlignment(Element.ALIGN_MIDDLE);cell4.setBorder(0);PdfPCell cell5 = new PdfPCell(new Paragraph("领导审批:", headfont1));cell5.setVerticalAlignment(Element.ALIGN_LEFT);cell5.setHorizontalAlignment(Element.ALIGN_MIDDLE);cell5.setBorder(0);table.addCell(cell3);table.addCell(cell4);table.addCell(cell5);document.add(table);float[] widthe3 = {25f, 25f};table = new PdfPTable(widthe3);table.setSpacingBefore(20f);table.setWidthPercentage(100.0f);PdfPCell cell6 = new PdfPCell(new Paragraph("接收单位签收人:", headfont1));cell6.setVerticalAlignment(Element.ALIGN_LEFT);cell6.setHorizontalAlignment(Element.ALIGN_MIDDLE);cell6.setFixedHeight(35);cell6.setBorder(0);PdfPCell cell7 = new PdfPCell(new Paragraph("签收时间: 月 日 时 分", headfont1));cell7.setVerticalAlignment(Element.ALIGN_LEFT);cell7.setHorizontalAlignment(Element.ALIGN_MIDDLE);cell7.setBorder(0);table.addCell(cell6);table.addCell(cell7);document.add(table);document.close();} catch (Exception e) {e.printStackTrace();}}
该用到的步骤我已经标注的很详细了,即是我自己的学习记录希望能帮到各位猿友。如有不足之处还望多多指教!