做网站用什么软件免费为朋友做的网站
1、安装gedit
brew install gedit
2、配置环境变量,打开~/.zshrc,在末尾添加语句
export PATH=$PATH:/usr/local/ffmpeg/bin
3、执行语句,使环境变量生效
source ~/.zshrc4、终端输入 ffmpeg ,看环境变量是否配置成功。
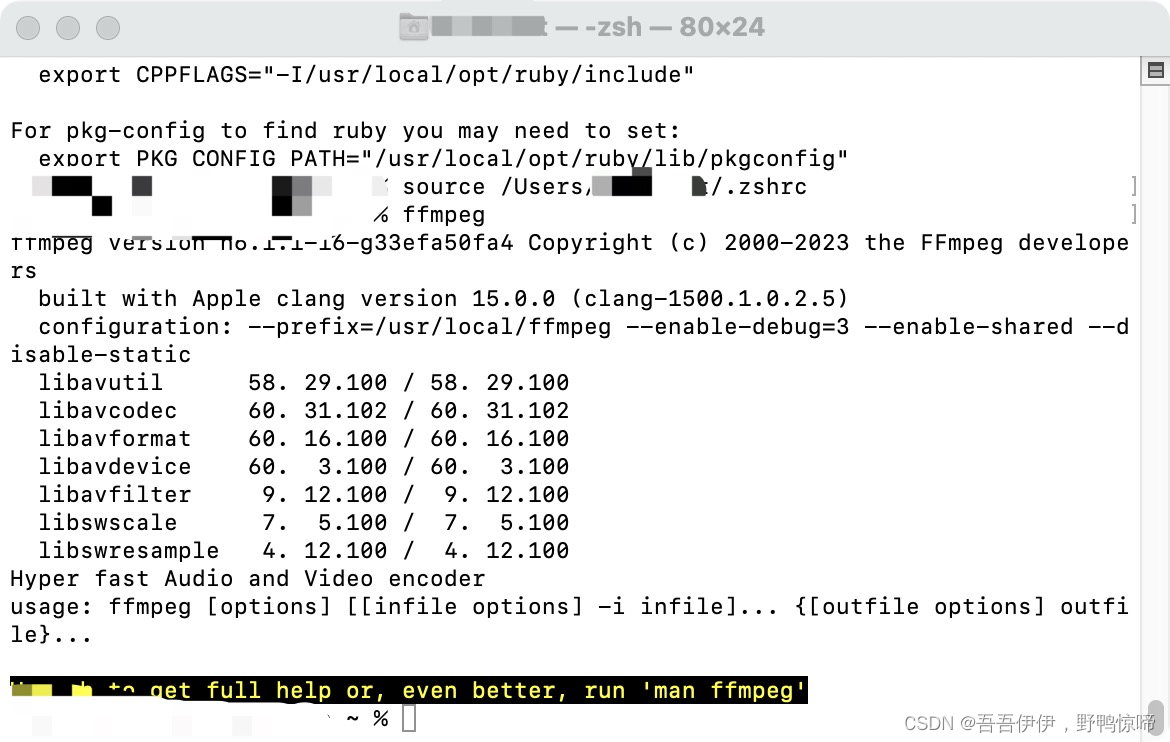
至此,完结
1、安装gedit
brew install gedit
2、配置环境变量,打开~/.zshrc,在末尾添加语句
export PATH=$PATH:/usr/local/ffmpeg/bin
3、执行语句,使环境变量生效
source ~/.zshrc4、终端输入 ffmpeg ,看环境变量是否配置成功。
至此,完结