如何建设小说网站厦门网站建设厦门seo
加速网盘下载
相信经常玩游戏的小伙伴都知道「Cheat Engine」这款游戏内存修改器,它除了能对游戏进行内存扫描、调试、反汇编 之外,还能像变速齿轮那样进行本地加速。

这款专注游戏的修改器,被大神发现竟然还能加速百度网盘资源下载,简直离了大谱,所以万物都能加速是真的!
教程开始
1.先在百度网盘客户端随便下载一个文件,这时显示的下载速度为100kb/s,先不用管!
2.打开任务管理器,可以在开始菜单-右键 -打开任务管理器,在状态栏上右键勾选显示软件PID号!
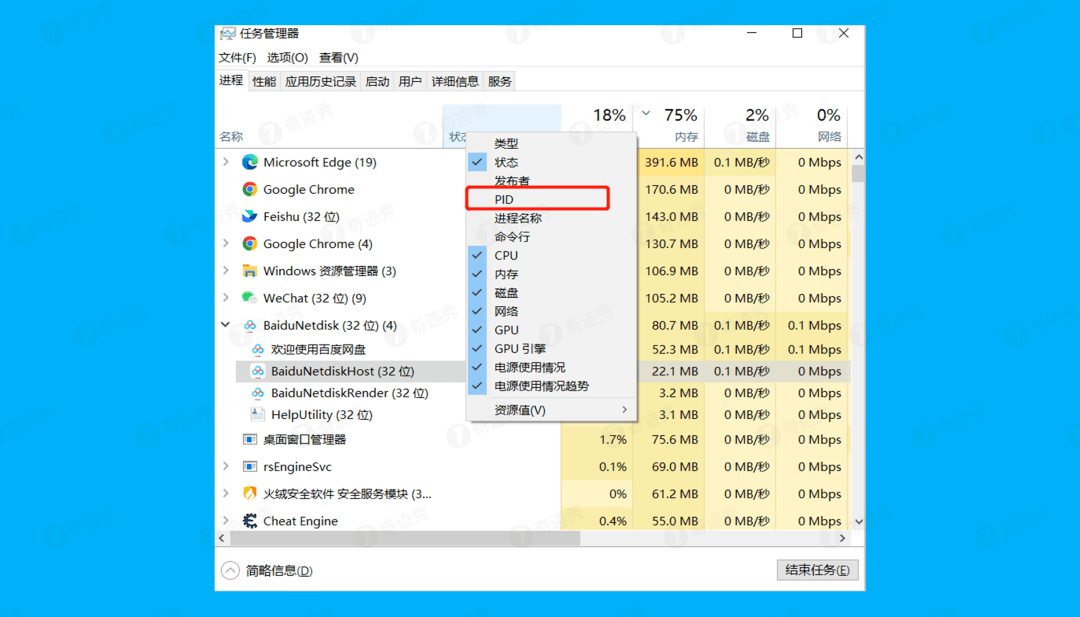
3.找到 BaiduNetDiskHost 对应的PID, 这里每台电脑不是统一的,我这里为25620,可以看到网速为0.1MB/S
4.打开 Cheat Engine软件,点击左上角图标, 在当前进程窗口右键选择Convert PID to decimal。
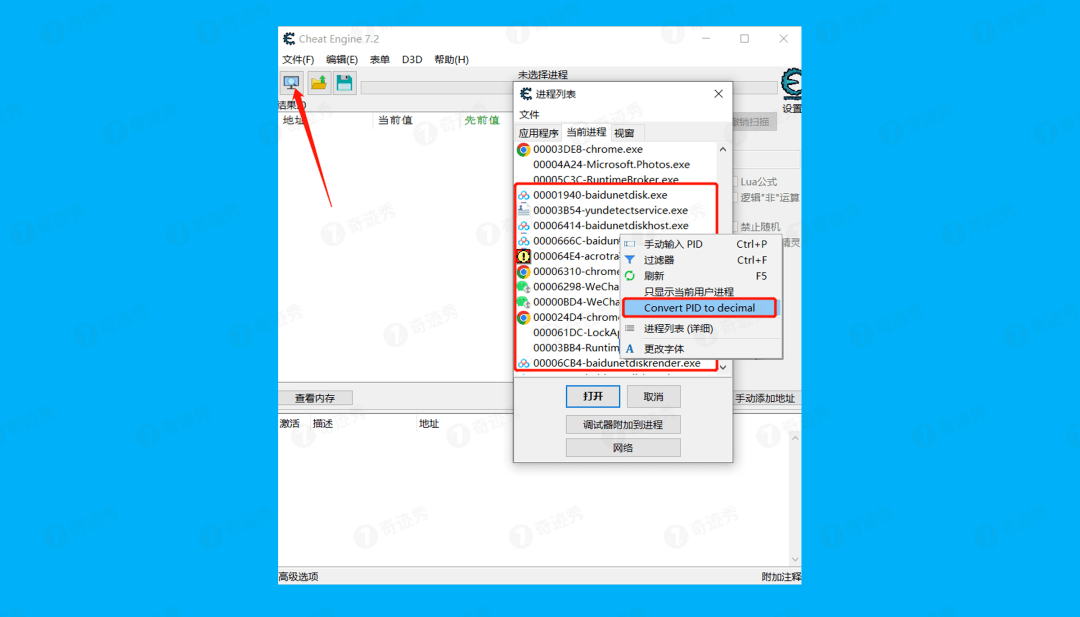
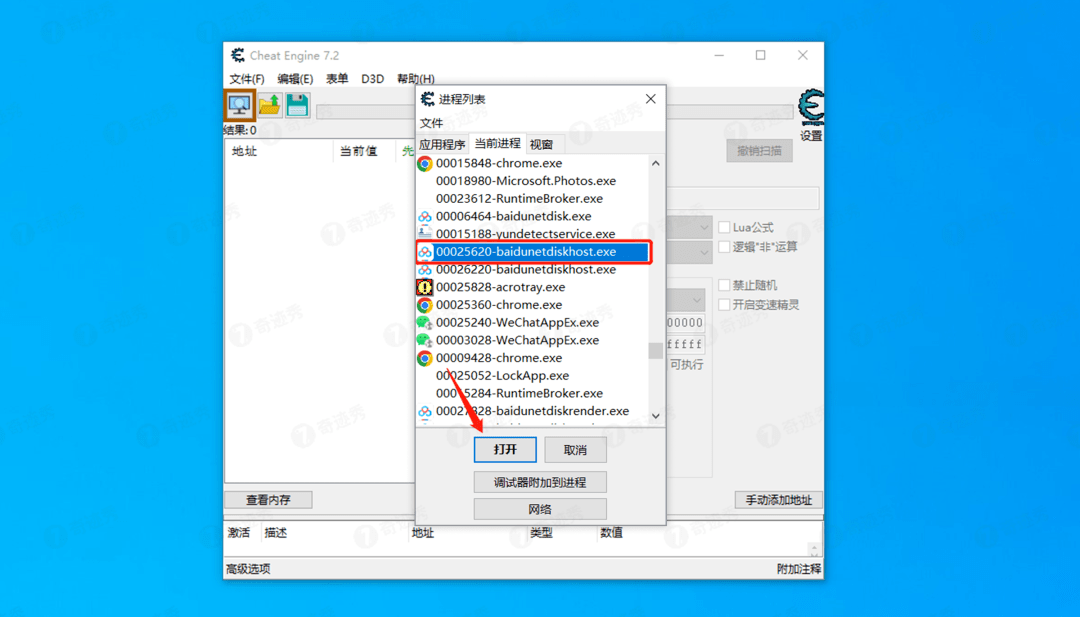
5.然后在弹窗中选择25620这个进程,然后点击打开 。
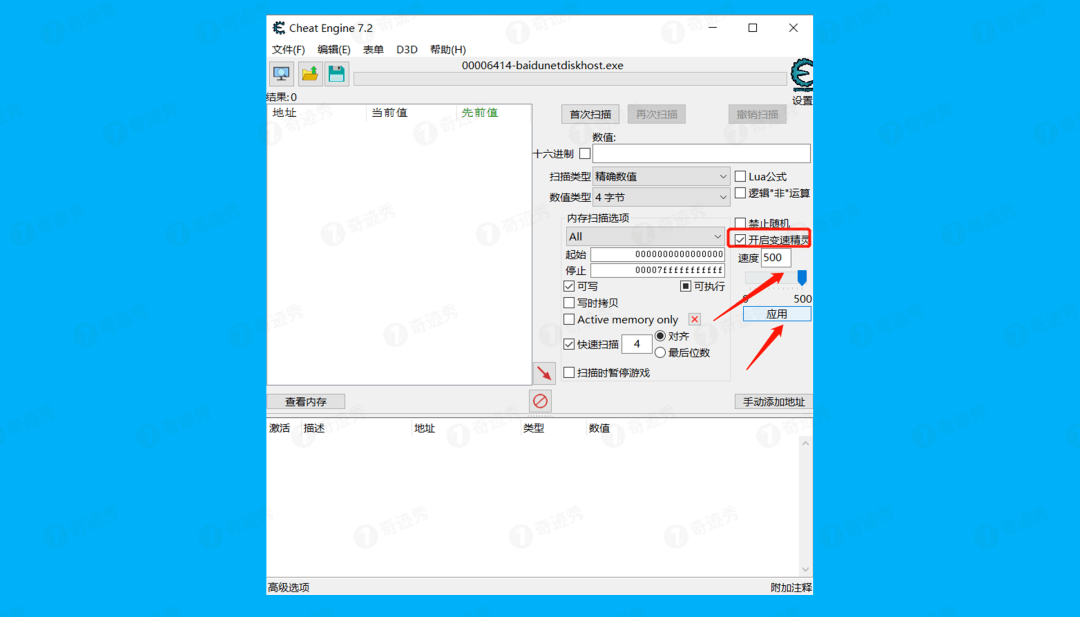
6.然后勾选「开启变速精灵」,将速度拖到最大值500,或者手动修改到9999也行,最后再点击「应用」。
7.现在打开网盘,虽然下载速度还是显示为几KB/S,但你会发现左边文件大小正在飞速增长!
8.这时你再去任务管理器中查看百度网盘的网速,达到8.5MB/S,直接能跑满宽带!
在开启加速的情况下,只用 3 分钟就下载完成1.5G的文件,平均下载速度达到了 8M/s,如果不是宽带限制,只怕还能跑得更快,最重要下载的文件可以正常打开,说明文件一切正常。