购物节优惠卷网站怎么做怎么优化推广自己的网站

文章目录
- 一. map的介绍
- 二. map的使用
- 结束语
一. map的介绍
- map是关联容器,它按照特定的次序(按照key来比较)存储由键值key和值value组合而成的元素
- 在map中,键值key通常用于排序和唯一地标识元素,而value中存储与此键值key关联的内容。键值key和值value的类型可能不同,并且在map的内部,key和value通过成员类型value_type绑定在一起,为其取别名为pair
typedef pair<const key,T>value_type;- 在内部,map中的元素总是按照键值key进行比较排序
- map中通过键值访问单个元素的速度比unordered_map容器慢,但map允许根据顺序对元素进行直接迭代(即对map中的元素进行迭代时,可以得到一个有序的序列)
- map支持下标访问符,即在[]中放下key,就可以找到对应的value
- map 通常被实现为二叉搜索树(更准确的说,平衡二叉搜索树(红黑树))。
二. map的使用
map中存储的是pair
T1 first就是key值,T2 second就是value值
template <class T1, class T2>
struct pair
{
typedef T1 first_type;
typedef T2 second_type;
T1 first;
T2 second;
pair(): first(T1()), second(T2())
{}
pair(const T1& a, const T2& b): first(a), second(b)
{}
};
insert插入

我们测试一下map的插入
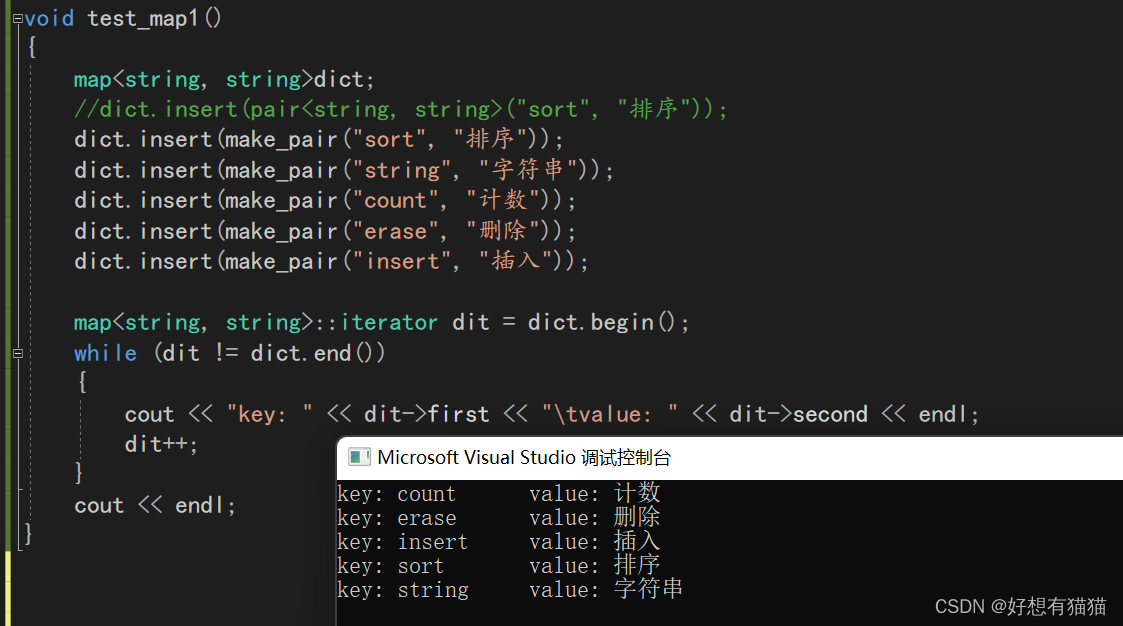
首先map存储的是pair这一数据类型,我们可以使用pair<string,string>的匿名构造,但是这样写法较为复杂。
C++就提供了一个make_pair的仿函数

使用make_pair这个仿函数的好处,一是写法较为简便,二是其会自动推导类型,所以不需要像pair匿名构造那样需要指明类型。
其次,map的迭代器解引用返回的是pair结构体,不能直接输出,需要再指定其内部属性。
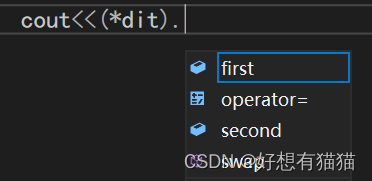
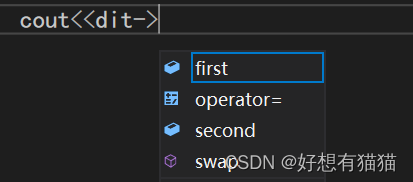
不过map重载了->,可以直接使用->输出。二者效果相同
operator[]重载
如果我们要统计水果的个数,可以这样统计
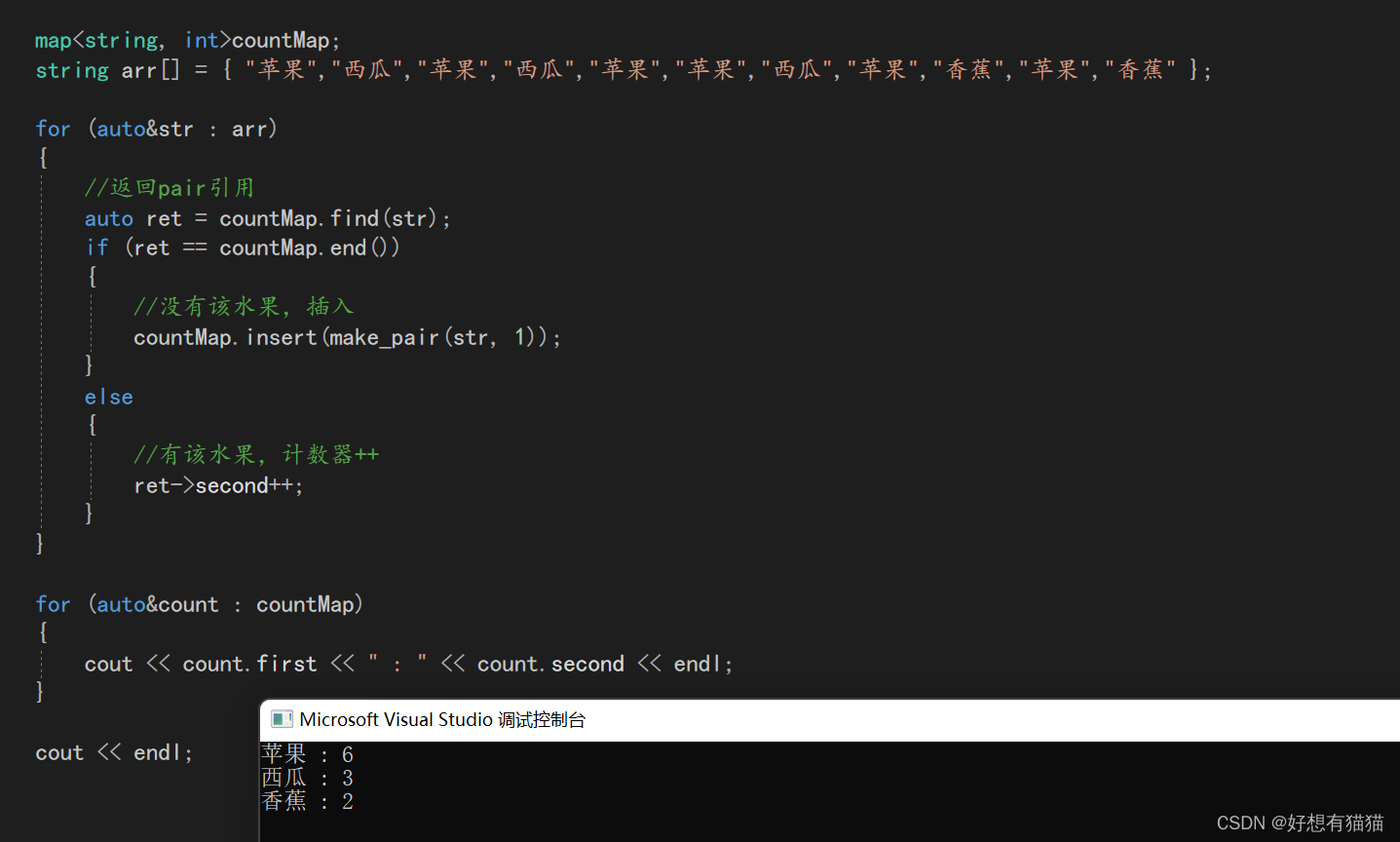
我们也可以使用map的operator[]重载完成需求
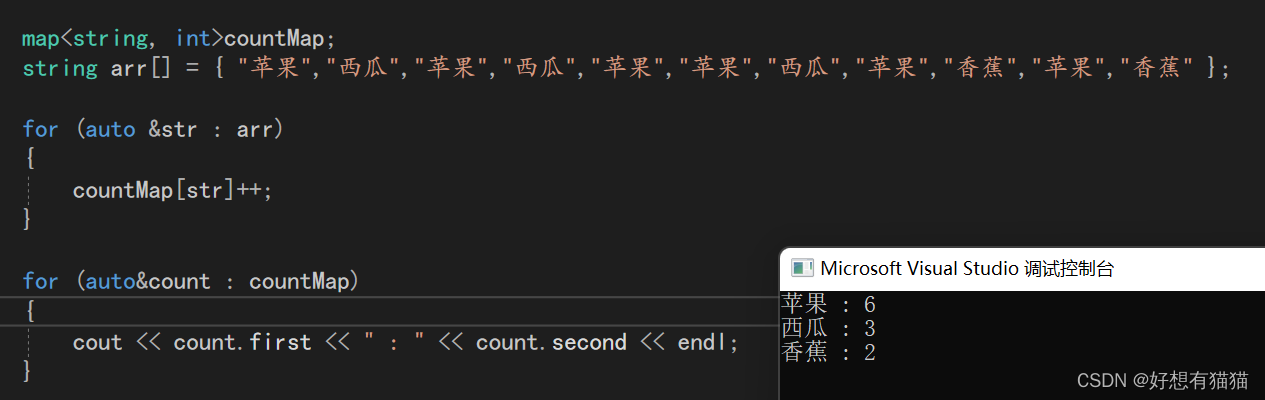
我们解析一下operator[]


调用operator[]实际是调用这一大坨东西,我们对其进行一个拆分
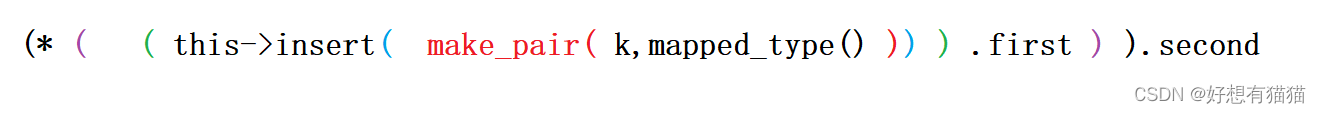
make_pair的返回值就是一个pair,但是我们看到这里也使用了insert的返回值
接下来我们讲解一下insert的返回值

insert插入的value_type其实就是pair,返回值也是一个pair,但是这个pair的第一个参数是一个迭代器,第二个参数是一个bool值
根据文献的描述,如果插入的元素在map中不存在,则插入,返回的迭代器指向该元素位置,如果已存在,返回的迭代器指向该元素在map中的位置;第二个bool值,如果是新插入元素,则返回真,若元素已存在,返回假。
所以( this->insert( make_pair( k,mapped_type() ) ) )其实就是一个pair<iterator,bool>
再取pair的的first,就是iterator,再解引用取到指向的pair,最后取second属性,就是value。并且返回该value的引用
所以,如果水果不存在,就插入,value因为是int,会调默认构造,初始化为0,然后返回value的引用,++就变成1了
如果水果存在,不会插入,但还是会返回value的引用,++就让value的值变大了。
所以operator[]的作用有四种
- 插入
- 插入+修改
- 修改
- 查找

dict[“left”]只指明了key,则value需要调用string的默认构造
dict[“right”]=“右边”,开始同上,但是[]返回value,我们将其改成"右边"
dict[“string”]=“(字符串)”,前部分返回value的引用,我们将其修改
因为[]会返回value,则也可以查找。
结束语
感谢你的阅读
如果觉得本篇文章对你有所帮助的话,不妨点个赞支持一下博主,拜托啦,这对我真的很重要。
